 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-aware Monocular Depth Estimation for Minimally Invasive Surgery
Mar 03, 2026Purpose: Monocular depth estimation (MDE) is vital for scene understanding in minimally invasive surgery (MIS). However, endoscopic video sequences are often contaminated by smoke, specular reflections, blur, and occlusions, limiting the accuracy of MDE models. In addition, current MDE models do not output depth confidence, which could be a valuable tool for improving their clinical reliability. Methods: We propose a novel confidence-aware MDE framework featuring three significant contributions: (i) Calibrated confidence targets: an ensemble of fine-tuned stereo matching models is used to capture disparity variance into pixel-wise confidence probabilities; (ii) Confidence-aware loss: Baseline MDE models are optimized with confidence-aware loss functions, utilizing pixel-wise confidence probabilities such that reliable pixels dominate training; and (iii) Inference-time confidence: a confidence estimation head is proposed with two convolution layers to predict per-pixel confidence at inference, enabling assessment of depth reliability. Results: Comprehensive experimental validation across internal and public datasets demonstrates that our framework improves depth estimation accuracy and can robustly quantify the prediction's confidence. On the internal clinical endoscopic dataset (StereoKP), we improve dense depth estimation accuracy by ~8% as compared to the baseline model. Conclusion: Our confidence-aware framework enables improved accuracy of MDE models in MIS, addressing challenges posed by noise and artifacts in pre-clinical and clinical data, and allows MDE models to provide confidence maps that may be used to improve their reliability for clinical applications.
A spatio-temporal network for video semantic segmentation in surgical videos
Jun 19, 2023Semantic segmentation in surgical videos has applications in intra-operative guidance, post-operative analytics and surgical education. Segmentation models need to provide accurate and consistent predictions since temporally inconsistent identification of anatomical structures can impair usability and hinder patient safety. Video information can alleviate these challenges leading to reliable models suitable for clinical use. We propose a novel architecture for modelling temporal relationships in videos. The proposed model includes a spatio-temporal decoder to enable video semantic segmentation by improving temporal consistency across frames. The encoder processes individual frames whilst the decoder processes a temporal batch of adjacent frames. The proposed decoder can be used on top of any segmentation encoder to improve temporal consistency. Model performance was evaluated on the CholecSeg8k dataset and a private dataset of robotic Partial Nephrectomy procedures. Segmentation performance was improved when the temporal decoder was applied across both datasets. The proposed model also displayed improvements in temporal consistency.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022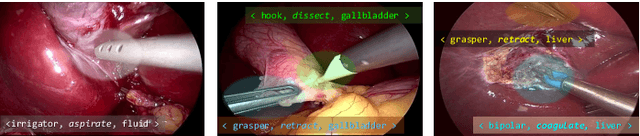

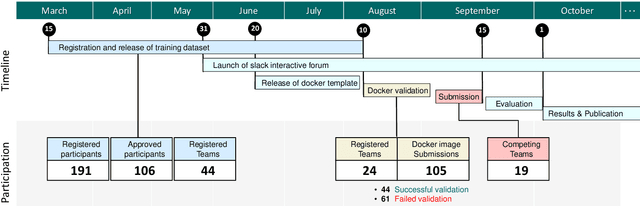
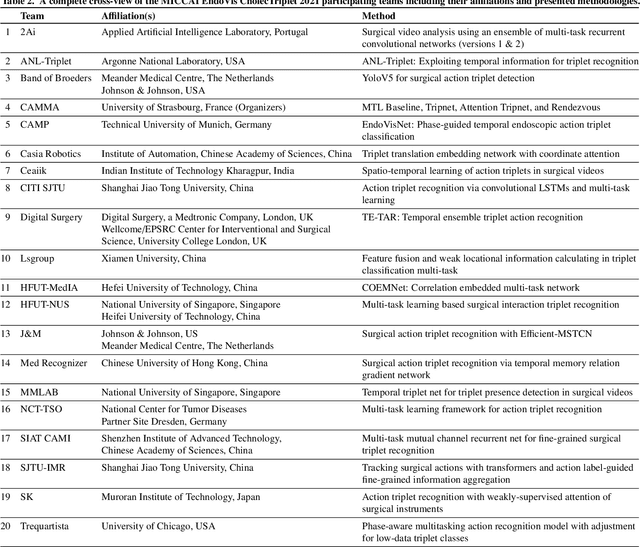
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Improving filling level classification with adversarial training
Feb 08, 2021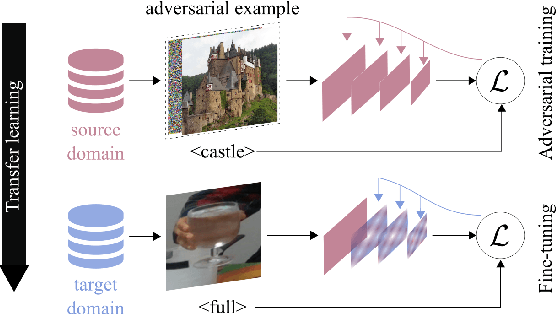
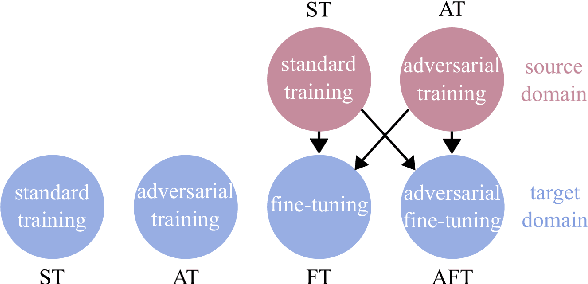


We investigate the problem of classifying - from a single image - the level of content in a cup or a drinking glass. This problem is made challenging by several ambiguities caused by transparencies, shape variations and partial occlusions, and by the availability of only small training datasets. In this paper, we tackle this problem with an appropriate strategy for transfer learning. Specifically, we use adversarial training in a generic source dataset and then refine the training with a task-specific dataset. We also discuss and experimentally evaluate several training strategies and their combination on a range of container types of the CORSMAL Containers Manipulation dataset. We show that transfer learning with adversarial training in the source domain consistently improves the classification accuracy on the test set and limits the overfitting of the classifier to specific features of the training data.
Benchmark for Anonymous Video Analytics
Sep 30, 2020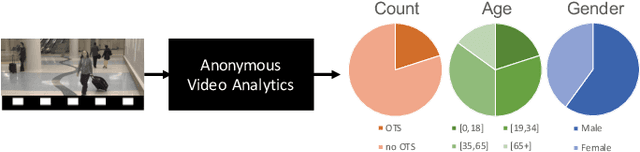
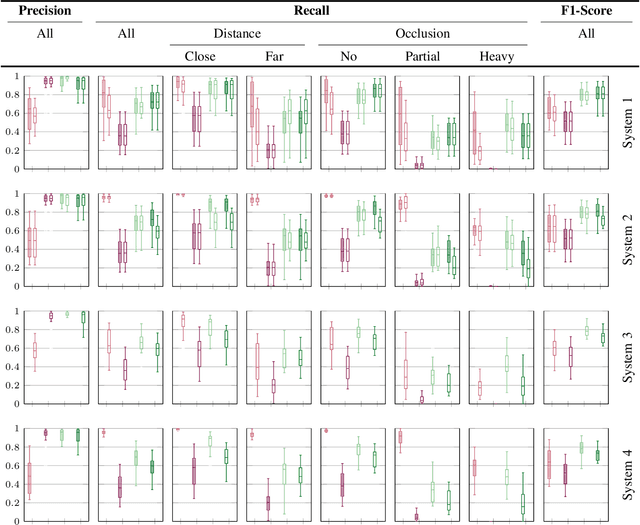
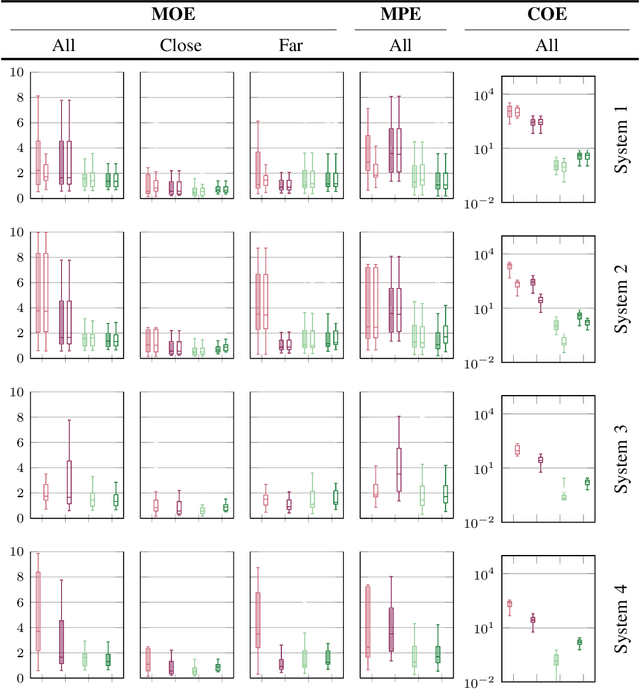
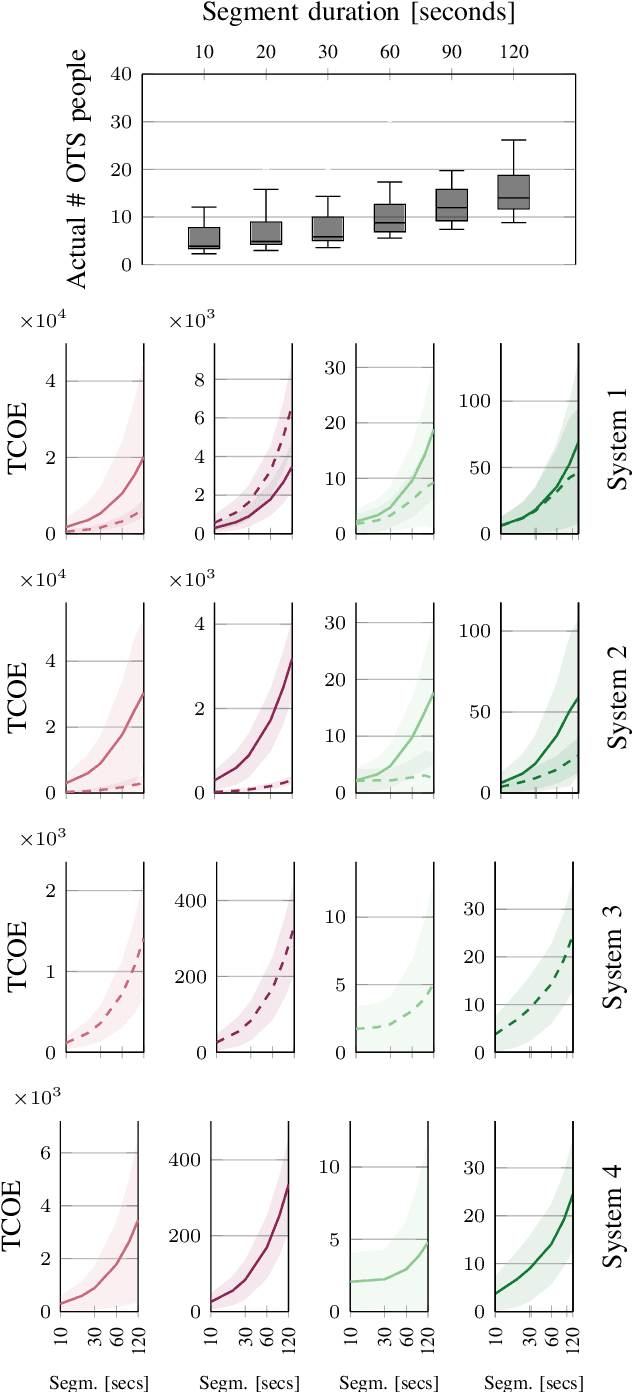
Estimating the number of people exposed to digital signage is important to help measuring the return on investment of digital out-of-home advertisement. However, while audience measurement solutions are of increasing interest, no commonly accepted benchmark exists to evaluate their performance. In this paper, we propose the first benchmark for digital out-of-home audience measurement that evaluates the tasks of audience localization and counting, and audience demographics. The benchmark is composed of a novel video dataset captured in multiple indoor and outdoor locations and a set of performance measures. Using the benchmark, we present an in-depth comparison of eight open-source algorithms on four hardware platforms with GPU and CPU-optimized inferences and of two commercial off-the-shelf solutions for localization, count, age, and gender estimation.
Exploiting vulnerabilities of deep neural networks for privacy protection
Jul 19, 2020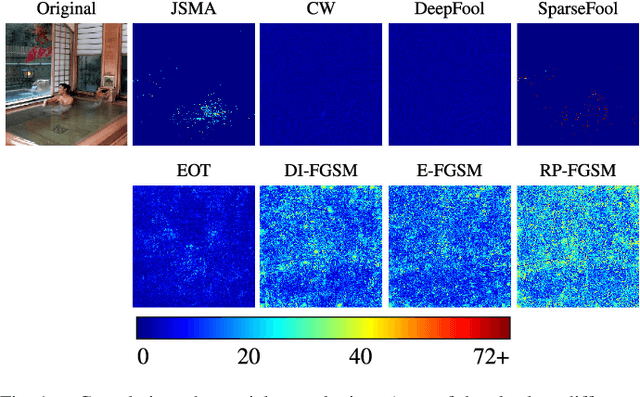
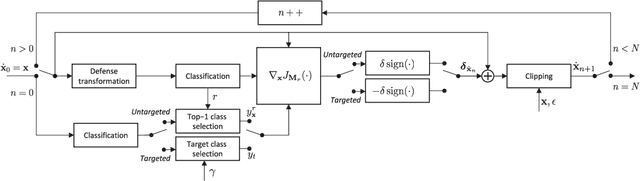
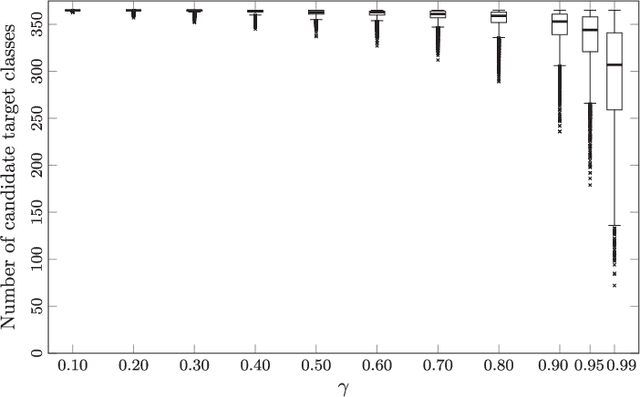
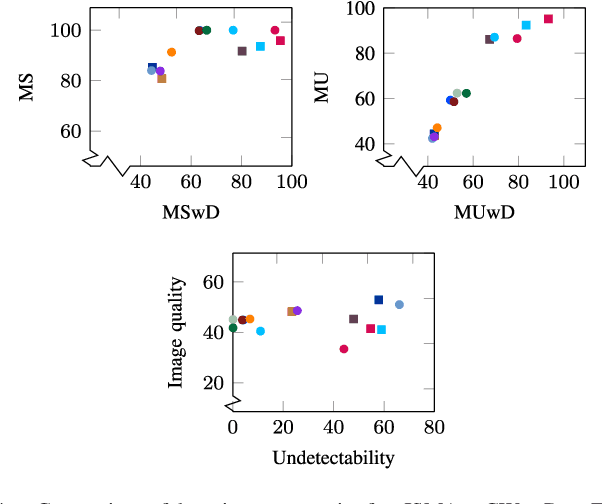
Adversarial perturbations can be added to images to protect their content from unwanted inferences. These perturbations may, however, be ineffective against classifiers that were not {seen} during the generation of the perturbation, or against defenses {based on re-quantization, median filtering or JPEG compression. To address these limitations, we present an adversarial attack {that is} specifically designed to protect visual content against { unseen} classifiers and known defenses. We craft perturbations using an iterative process that is based on the Fast Gradient Signed Method and {that} randomly selects a classifier and a defense, at each iteration}. This randomization prevents an undesirable overfitting to a specific classifier or defense. We validate the proposed attack in both targeted and untargeted settings on the private classes of the Places365-Standard dataset. Using ResNet18, ResNet50, AlexNet and DenseNet161 {as classifiers}, the performance of the proposed attack exceeds that of eleven state-of-the-art attacks. The implementation is available at https://github.com/smartcameras/RP-FGSM/.
Towards robust sensing for Autonomous Vehicles: An adversarial perspective
Jul 14, 2020
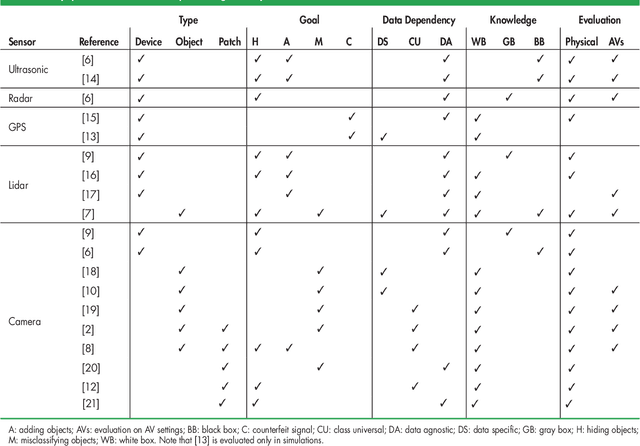

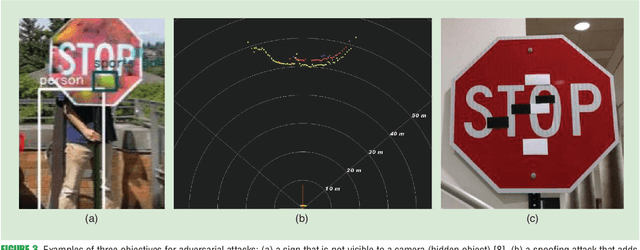
Autonomous Vehicles rely on accurate and robust sensor observations for safety critical decision-making in a variety of conditions. Fundamental building blocks of such systems are sensors and classifiers that process ultrasound, RADAR, GPS, LiDAR and camera signals~\cite{Khan2018}. It is of primary importance that the resulting decisions are robust to perturbations, which can take the form of different types of nuisances and data transformations, and can even be adversarial perturbations (APs). Adversarial perturbations are purposefully crafted alterations of the environment or of the sensory measurements, with the objective of attacking and defeating the autonomous systems. A careful evaluation of the vulnerabilities of their sensing system(s) is necessary in order to build and deploy safer systems in the fast-evolving domain of AVs. To this end, we survey the emerging field of sensing in adversarial settings: after reviewing adversarial attacks on sensing modalities for autonomous systems, we discuss countermeasures and present future research directions.
Multi-view shape estimation of transparent containers
Nov 27, 2019
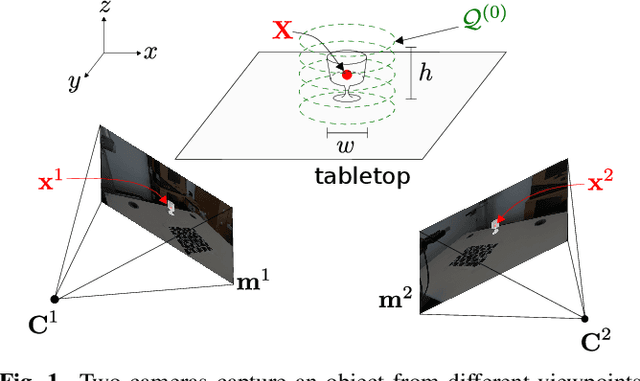


The 3D localisation of an object and the estimation of its properties, such as shape and dimensions, are challenging under varying degrees of transparency and lighting conditions. In this paper, we propose a method for jointly localising container-like objects and estimating their dimensions using two wide-baseline, calibrated RGB cameras. Under the assumption of vertical circular symmetry, we estimate the dimensions of an object by sampling at different heights a set of sparse circumferences with iterative shape fitting and image re-projection to verify the sampling hypotheses in each camera using semantic segmentation masks. We evaluate the proposed method on a novel dataset of objects with different degrees of transparency and captured under different backgrounds and illumination conditions. Our method, which is based on RGB images only outperforms, in terms of localisation success and dimension estimation accuracy a deep-learning based approach that uses depth maps.
ColorFool: Semantic Adversarial Colorization
Nov 25, 2019



Adversarial attacks that generate small L_p-norm perturbations to mislead classifiers have limited success in black-box settings and with unseen classifiers. These attacks are also fragile with defenses that use denoising filters and to adversarial training procedures. Instead, adversarial attacks that generate unrestricted perturbations are more robust to defenses, are generally more successful in black-box settings and are more transferable to unseen classifiers. However, unrestricted perturbations may be noticeable to humans. In this paper, we propose a content-based black-box adversarial attack that generates unrestricted perturbations by exploiting image semantics to selectively modify colors within chosen ranges that are perceived as natural by humans. We show that the proposed approach, ColorFool, outperforms in terms of success rate, robustness to defense frameworks and transferability five state-of-the-art adversarial attacks on two different tasks, scene and object classification, when attacking three state-of-the-art deep neural networks using three standard datasets. We will make the code of the proposed approach and the whole evaluation framework publicly available.