 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Temporal Fusion for Financial Market Forecasting
Apr 18, 2025Accurate financial market forecasting requires diverse data sources, including historical price trends, macroeconomic indicators, and financial news, each contributing unique predictive signals. However, existing methods often process these modalities independently or fail to effectively model their interactions. In this paper, we introduce Cross-Modal Temporal Fusion (CMTF), a novel transformer-based framework that integrates heterogeneous financial data to improve predictive accuracy. Our approach employs attention mechanisms to dynamically weight the contribution of different modalities, along with a specialized tensor interpretation module for feature extraction. To facilitate rapid model iteration in industry applications, we incorporate a mature auto-training scheme that streamlines optimization. When applied to real-world financial datasets, CMTF demonstrates improvements over baseline models in forecasting stock price movements and provides a scalable and effective solution for cross-modal integration in financial market prediction.
On the reversibility of adversarial attacks
Jun 01, 2022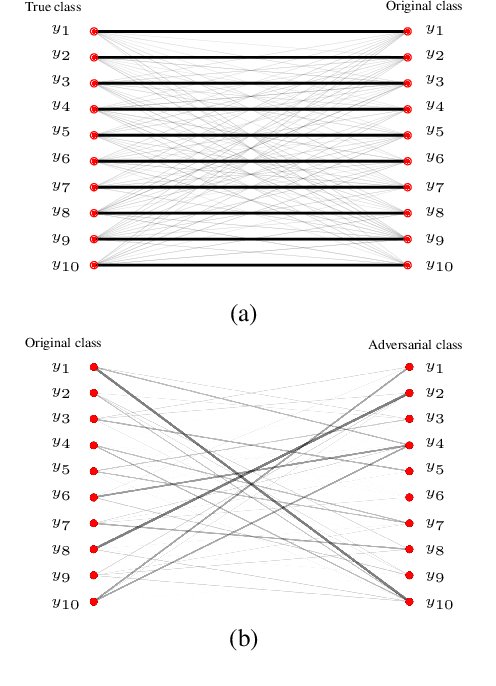


Adversarial attacks modify images with perturbations that change the prediction of classifiers. These modified images, known as adversarial examples, expose the vulnerabilities of deep neural network classifiers. In this paper, we investigate the predictability of the mapping between the classes predicted for original images and for their corresponding adversarial examples. This predictability relates to the possibility of retrieving the original predictions and hence reversing the induced misclassification. We refer to this property as the reversibility of an adversarial attack, and quantify reversibility as the accuracy in retrieving the original class or the true class of an adversarial example. We present an approach that reverses the effect of an adversarial attack on a classifier using a prior set of classification results. We analyse the reversibility of state-of-the-art adversarial attacks on benchmark classifiers and discuss the factors that affect the reversibility.
Underwater image filtering: methods, datasets and evaluation
Dec 22, 2020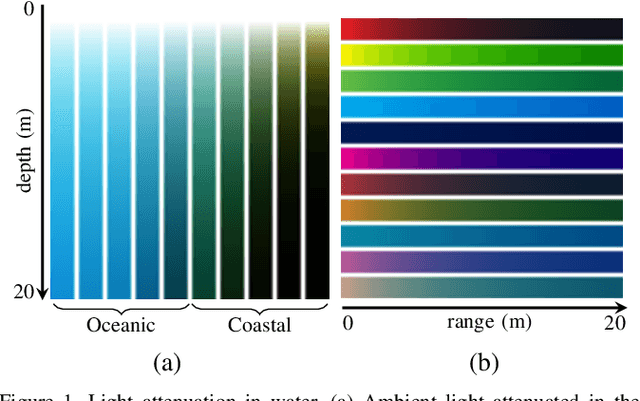
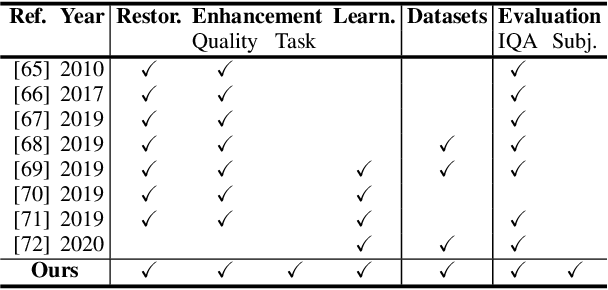

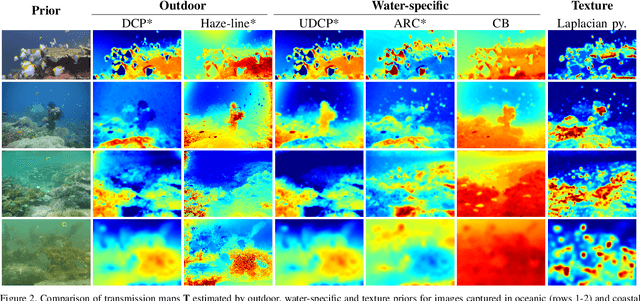
Underwater images are degraded by the selective attenuation of light that distorts colours and reduces contrast. The degradation extent depends on the water type, the distance between an object and the camera, and the depth under the water surface the object is at. Underwater image filtering aims to restore or to enhance the appearance of objects captured in an underwater image. Restoration methods compensate for the actual degradation, whereas enhancement methods improve either the perceived image quality or the performance of computer vision algorithms. The growing interest in underwater image filtering methods--including learning-based approaches used for both restoration and enhancement--and the associated challenges call for a comprehensive review of the state of the art. In this paper, we review the design principles of filtering methods and revisit the oceanology background that is fundamental to identify the degradation causes. We discuss image formation models and the results of restoration methods in various water types. Furthermore, we present task-dependent enhancement methods and categorise datasets for training neural networks and for method evaluation. Finally, we discuss evaluation strategies, including subjective tests and quality assessment measures. We complement this survey with a platform ( https://puiqe.eecs.qmul.ac.uk/ ), which hosts state-of-the-art underwater filtering methods and facilitates comparisons.
Exploiting vulnerabilities of deep neural networks for privacy protection
Jul 19, 2020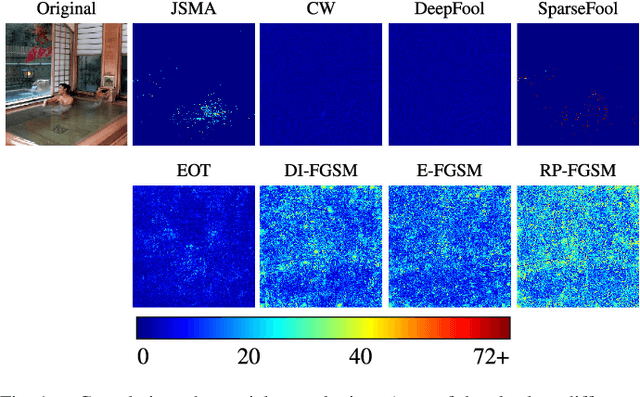
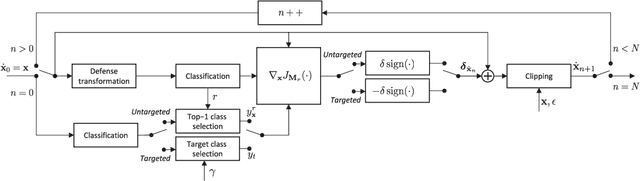
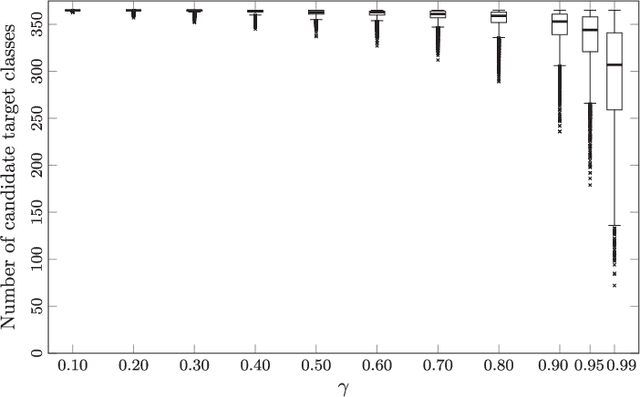
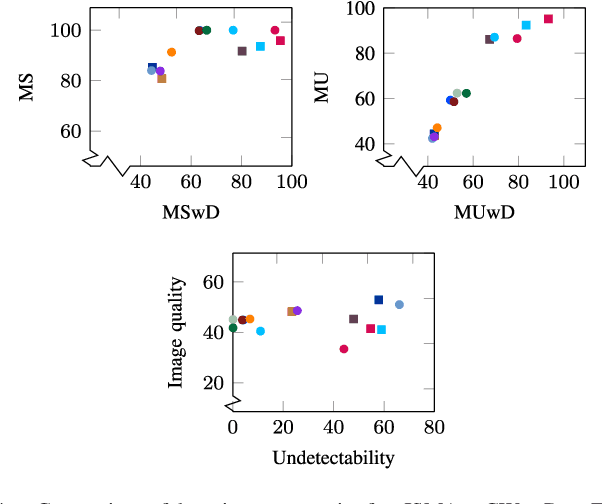
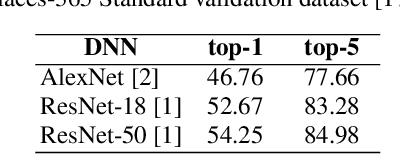
Adversarial perturbations can be added to images to protect their content from unwanted inferences. These perturbations may, however, be ineffective against classifiers that were not {seen} during the generation of the perturbation, or against defenses {based on re-quantization, median filtering or JPEG compression. To address these limitations, we present an adversarial attack {that is} specifically designed to protect visual content against { unseen} classifiers and known defenses. We craft perturbations using an iterative process that is based on the Fast Gradient Signed Method and {that} randomly selects a classifier and a defense, at each iteration}. This randomization prevents an undesirable overfitting to a specific classifier or defense. We validate the proposed attack in both targeted and untargeted settings on the private classes of the Places365-Standard dataset. Using ResNet18, ResNet50, AlexNet and DenseNet161 {as classifiers}, the performance of the proposed attack exceeds that of eleven state-of-the-art attacks. The implementation is available at https://github.com/smartcameras/RP-FGSM/.