 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Bias in Gender Bias Benchmarks: How Spurious Features Distort Evaluation
Sep 09, 2025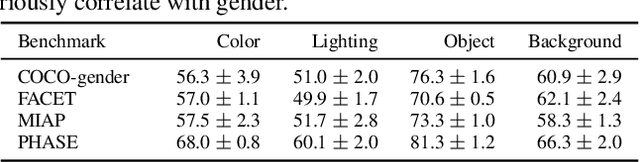

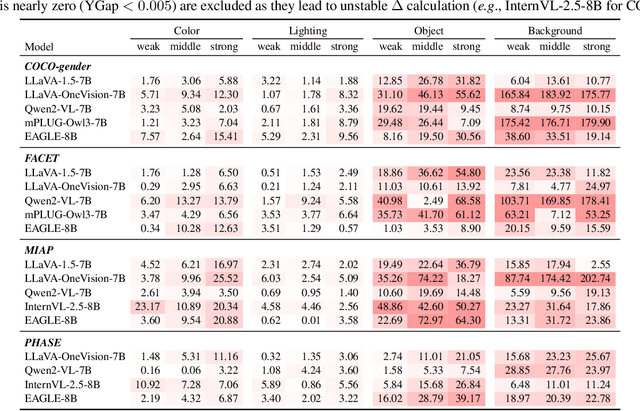

Gender bias in vision-language foundation models (VLMs) raises concerns about their safe deployment and is typically evaluated using benchmarks with gender annotations on real-world images. However, as these benchmarks often contain spurious correlations between gender and non-gender features, such as objects and backgrounds, we identify a critical oversight in gender bias evaluation: Do spurious features distort gender bias evaluation? To address this question, we systematically perturb non-gender features across four widely used benchmarks (COCO-gender, FACET, MIAP, and PHASE) and various VLMs to quantify their impact on bias evaluation. Our findings reveal that even minimal perturbations, such as masking just 10% of objects or weakly blurring backgrounds, can dramatically alter bias scores, shifting metrics by up to 175% in generative VLMs and 43% in CLIP variants. This suggests that current bias evaluations often reflect model responses to spurious features rather than gender bias, undermining their reliability. Since creating spurious feature-free benchmarks is fundamentally challenging, we recommend reporting bias metrics alongside feature-sensitivity measurements to enable a more reliable bias assessment.
From Global to Local: Social Bias Transfer in CLIP
Aug 25, 2025The recycling of contrastive language-image pre-trained (CLIP) models as backbones for a large number of downstream tasks calls for a thorough analysis of their transferability implications, especially their well-documented reproduction of social biases and human stereotypes. How do such biases, learned during pre-training, propagate to downstream applications like visual question answering or image captioning? Do they transfer at all? We investigate this phenomenon, referred to as bias transfer in prior literature, through a comprehensive empirical analysis. Firstly, we examine how pre-training bias varies between global and local views of data, finding that bias measurement is highly dependent on the subset of data on which it is computed. Secondly, we analyze correlations between biases in the pre-trained models and the downstream tasks across varying levels of pre-training bias, finding difficulty in discovering consistent trends in bias transfer. Finally, we explore why this inconsistency occurs, showing that under the current paradigm, representation spaces of different pre-trained CLIPs tend to converge when adapted for downstream tasks. We hope this work offers valuable insights into bias behavior and informs future research to promote better bias mitigation practices.
SANER: Annotation-free Societal Attribute Neutralizer for Debiasing CLIP
Aug 19, 2024Large-scale vision-language models, such as CLIP, are known to contain harmful societal bias regarding protected attributes (e.g., gender and age). In this paper, we aim to address the problems of societal bias in CLIP. Although previous studies have proposed to debias societal bias through adversarial learning or test-time projecting, our comprehensive study of these works identifies two critical limitations: 1) loss of attribute information when it is explicitly disclosed in the input and 2) use of the attribute annotations during debiasing process. To mitigate societal bias in CLIP and overcome these limitations simultaneously, we introduce a simple-yet-effective debiasing method called SANER (societal attribute neutralizer) that eliminates attribute information from CLIP text features only of attribute-neutral descriptions. Experimental results show that SANER, which does not require attribute annotations and preserves original information for attribute-specific descriptions, demonstrates superior debiasing ability than the existing methods.
Resampled Datasets Are Not Enough: Mitigating Societal Bias Beyond Single Attributes
Jul 04, 2024
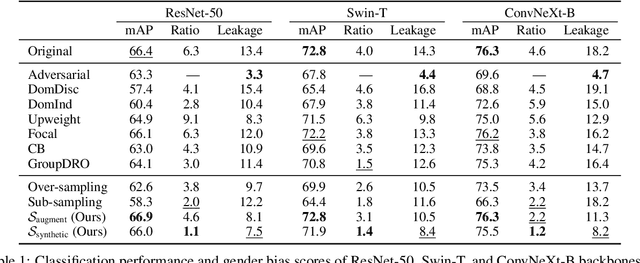
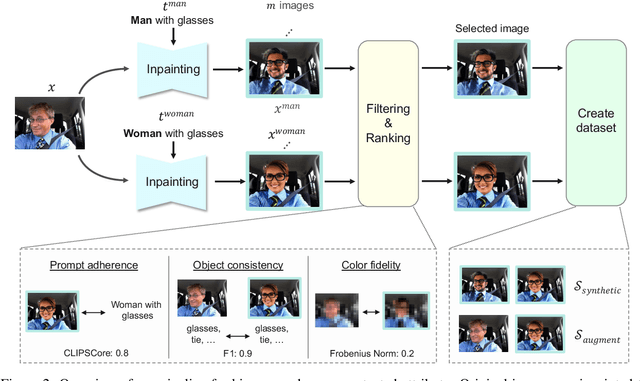
We tackle societal bias in image-text datasets by removing spurious correlations between protected groups and image attributes. Traditional methods only target labeled attributes, ignoring biases from unlabeled ones. Using text-guided inpainting models, our approach ensures protected group independence from all attributes and mitigates inpainting biases through data filtering. Evaluations on multi-label image classification and image captioning tasks show our method effectively reduces bias without compromising performance across various models.
From Descriptive Richness to Bias: Unveiling the Dark Side of Generative Image Caption Enrichment
Jun 20, 2024



Large language models (LLMs) have enhanced the capacity of vision-language models to caption visual text. This generative approach to image caption enrichment further makes textual captions more descriptive, improving alignment with the visual context. However, while many studies focus on benefits of generative caption enrichment (GCE), are there any negative side effects? We compare standard-format captions and recent GCE processes from the perspectives of "gender bias" and "hallucination", showing that enriched captions suffer from increased gender bias and hallucination. Furthermore, models trained on these enriched captions amplify gender bias by an average of 30.9% and increase hallucination by 59.5%. This study serves as a caution against the trend of making captions more descriptive.
Would Deep Generative Models Amplify Bias in Future Models?
Apr 04, 2024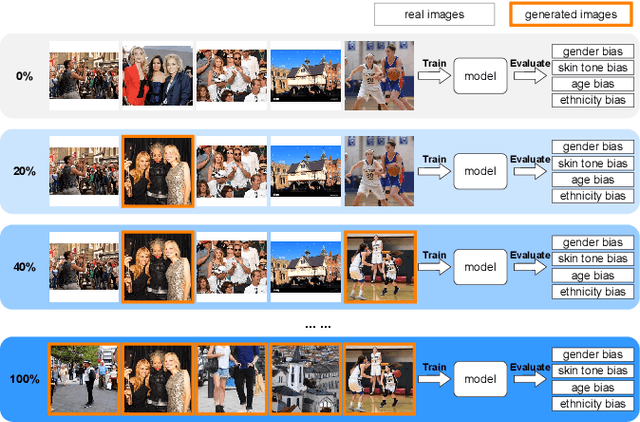
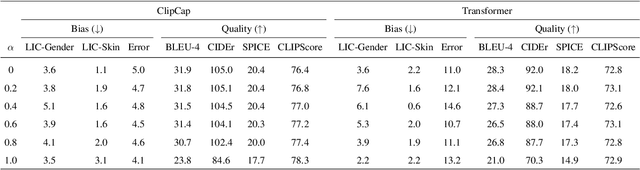
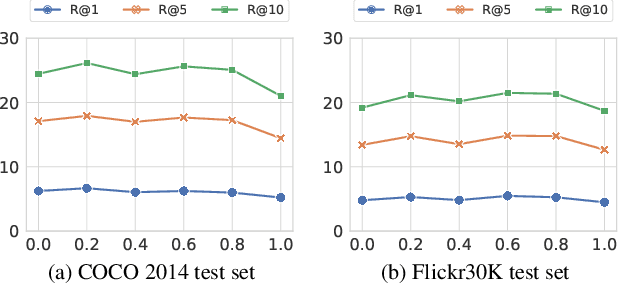
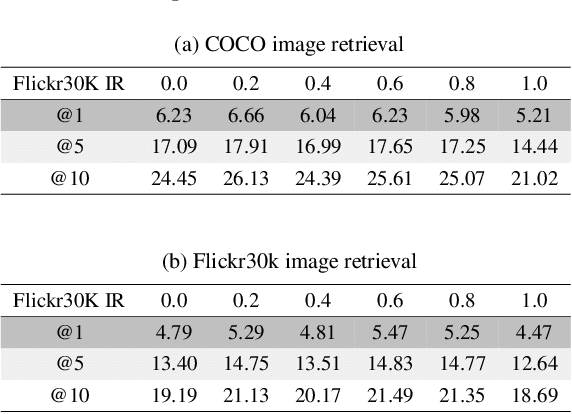
We investigate the impact of deep generative models on potential social biases in upcoming computer vision models. As the internet witnesses an increasing influx of AI-generated images, concerns arise regarding inherent biases that may accompany them, potentially leading to the dissemination of harmful content. This paper explores whether a detrimental feedback loop, resulting in bias amplification, would occur if generated images were used as the training data for future models. We conduct simulations by progressively substituting original images in COCO and CC3M datasets with images generated through Stable Diffusion. The modified datasets are used to train OpenCLIP and image captioning models, which we evaluate in terms of quality and bias. Contrary to expectations, our findings indicate that introducing generated images during training does not uniformly amplify bias. Instead, instances of bias mitigation across specific tasks are observed. We further explore the factors that may influence these phenomena, such as artifacts in image generation (e.g., blurry faces) or pre-existing biases in the original datasets.
Model-Agnostic Gender Debiased Image Captioning
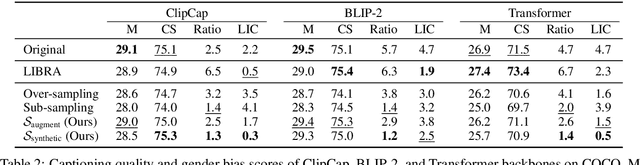
Apr 07, 2023Image captioning models are known to perpetuate and amplify harmful societal bias in the training set. In this work, we aim to mitigate such gender bias in image captioning models. While prior work has addressed this problem by forcing models to focus on people to reduce gender misclassification, it conversely generates gender-stereotypical words at the expense of predicting the correct gender. From this observation, we hypothesize that there are two types of gender bias affecting image captioning models: 1) bias that exploits context to predict gender, and 2) bias in the probability of generating certain (often stereotypical) words because of gender. To mitigate both types of gender biases, we propose a framework, called LIBRA, that learns from synthetically biased samples to decrease both types of biases, correcting gender misclassification and changing gender-stereotypical words to more neutral ones.
Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
Apr 06, 2023
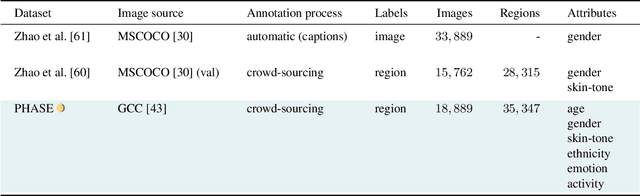

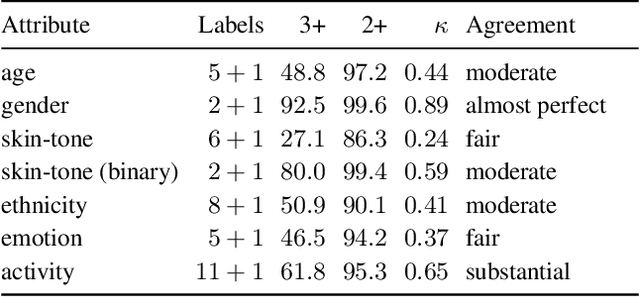
The increasing tendency to collect large and uncurated datasets to train vision-and-language models has raised concerns about fair representations. It is known that even small but manually annotated datasets, such as MSCOCO, are affected by societal bias. This problem, far from being solved, may be getting worse with data crawled from the Internet without much control. In addition, the lack of tools to analyze societal bias in big collections of images makes addressing the problem extremely challenging. Our first contribution is to annotate part of the Google Conceptual Captions dataset, widely used for training vision-and-language models, with four demographic and two contextual attributes. Our second contribution is to conduct a comprehensive analysis of the annotations, focusing on how different demographic groups are represented. Our last contribution lies in evaluating three prevailing vision-and-language tasks: image captioning, text-image CLIP embeddings, and text-to-image generation, showing that societal bias is a persistent problem in all of them.
Gender and Racial Bias in Visual Question Answering Datasets
May 18, 2022



Vision-and-language tasks have increasingly drawn more attention as a means to evaluate human-like reasoning in machine learning models. A popular task in the field is visual question answering (VQA), which aims to answer questions about images. However, VQA models have been shown to exploit language bias by learning the statistical correlations between questions and answers without looking into the image content: e.g., questions about the color of a banana are answered with yellow, even if the banana in the image is green. If societal bias (e.g., sexism, racism, ableism, etc.) is present in the training data, this problem may be causing VQA models to learn harmful stereotypes. For this reason, we investigate gender and racial bias in five VQA datasets. In our analysis, we find that the distribution of answers is highly different between questions about women and men, as well as the existence of detrimental gender-stereotypical samples. Likewise, we identify that specific race-related attributes are underrepresented, whereas potentially discriminatory samples appear in the analyzed datasets. Our findings suggest that there are dangers associated to using VQA datasets without considering and dealing with the potentially harmful stereotypes. We conclude the paper by proposing solutions to alleviate the problem before, during, and after the dataset collection process.