 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy in Image Datasets: A Case Study on Pregnancy Ultrasounds
Feb 06, 2026The rise of generative models has led to increased use of large-scale datasets collected from the internet, often with minimal or no data curation. This raises concerns about the inclusion of sensitive or private information. In this work, we explore the presence of pregnancy ultrasound images, which contain sensitive personal information and are often shared online. Through a systematic examination of LAION-400M dataset using CLIP embedding similarity, we retrieve images containing pregnancy ultrasound and detect thousands of entities of private information such as names and locations. Our findings reveal that multiple images have high-risk information that could enable re-identification or impersonation. We conclude with recommended practices for dataset curation, data privacy, and ethical use of public image datasets.
Stable Diffusion Exposed: Gender Bias from Prompt to Image
Dec 05, 2023

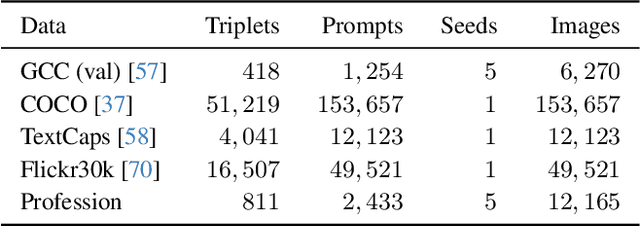

Recent studies have highlighted biases in generative models, shedding light on their predisposition towards gender-based stereotypes and imbalances. This paper contributes to this growing body of research by introducing an evaluation protocol designed to automatically analyze the impact of gender indicators on Stable Diffusion images. Leveraging insights from prior work, we explore how gender indicators not only affect gender presentation but also the representation of objects and layouts within the generated images. Our findings include the existence of differences in the depiction of objects, such as instruments tailored for specific genders, and shifts in overall layouts. We also reveal that neutral prompts tend to produce images more aligned with masculine prompts than their feminine counterparts, providing valuable insights into the nuanced gender biases inherent in Stable Diffusion.
Not Only Generative Art: Stable Diffusion for Content-Style Disentanglement in Art Analysis
Apr 20, 2023The duality of content and style is inherent to the nature of art. For humans, these two elements are clearly different: content refers to the objects and concepts in the piece of art, and style to the way it is expressed. This duality poses an important challenge for computer vision. The visual appearance of objects and concepts is modulated by the style that may reflect the author's emotions, social trends, artistic movement, etc., and their deep comprehension undoubtfully requires to handle both. A promising step towards a general paradigm for art analysis is to disentangle content and style, whereas relying on human annotations to cull a single aspect of artworks has limitations in learning semantic concepts and the visual appearance of paintings. We thus present GOYA, a method that distills the artistic knowledge captured in a recent generative model to disentangle content and style. Experiments show that synthetically generated images sufficiently serve as a proxy of the real distribution of artworks, allowing GOYA to separately represent the two elements of art while keeping more information than existing methods.
Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
Apr 06, 2023
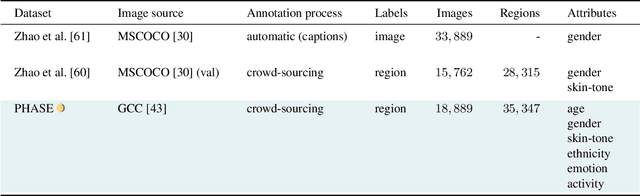

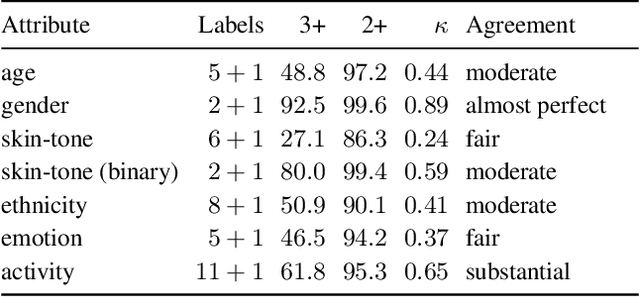
The increasing tendency to collect large and uncurated datasets to train vision-and-language models has raised concerns about fair representations. It is known that even small but manually annotated datasets, such as MSCOCO, are affected by societal bias. This problem, far from being solved, may be getting worse with data crawled from the Internet without much control. In addition, the lack of tools to analyze societal bias in big collections of images makes addressing the problem extremely challenging. Our first contribution is to annotate part of the Google Conceptual Captions dataset, widely used for training vision-and-language models, with four demographic and two contextual attributes. Our second contribution is to conduct a comprehensive analysis of the annotations, focusing on how different demographic groups are represented. Our last contribution lies in evaluating three prevailing vision-and-language tasks: image captioning, text-image CLIP embeddings, and text-to-image generation, showing that societal bias is a persistent problem in all of them.