 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments
Feb 15, 2026Long-horizon reasoning is a key challenge for autonomous agents, yet existing benchmarks evaluate agents on single tasks in isolation. Real organizational work requires managing many concurrent long-horizon tasks with interleaving, dependencies, and reprioritization. We introduce Multi-Horizon Task Environments (MHTEs): a distinct problem class requiring coherent execution across dozens of interleaved tasks (45+, 500-1500+ steps) within persistent execution contexts spanning hours. We identify four failure modes that cause baseline CUAs to degrade from 16.7% to 8.7% completion as load scales 25% to 100%, a pattern consistent across three independent implementations. These failure modes are context saturation (O(N) vs O(1) growth), memory interference, dependency complexity (DAGs vs. chains), and reprioritization overhead. We present CorpGen, an architecture-agnostic framework addressing these failures via hierarchical planning for multi-horizon goal alignment, sub-agent isolation preventing cross-task contamination, tiered memory (working, structured, semantic), and adaptive summarization. CorpGen simulates corporate environments through digital employees with persistent identities and realistic schedules. Across three CUA backends (UFO2, OpenAI CUA, hierarchical) on OSWorld Office, CorpGen achieves up to 3.5x improvement over baselines (15.2% vs 4.3%) with stable performance under increasing load, confirming that gains stem from architectural mechanisms rather than specific CUA implementations. Ablation studies show experiential learning provides the largest gains.
Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
SAGEval: The frontiers of Satisfactory Agent based NLG Evaluation for reference-free open-ended text
Nov 25, 2024Large Language Model (LLM) integrations into applications like Microsoft365 suite and Google Workspace for creating/processing documents, emails, presentations, etc. has led to considerable enhancements in productivity and time savings. But as these integrations become more more complex, it is paramount to ensure that the quality of output from the LLM-integrated applications are relevant and appropriate for use. Identifying the need to develop robust evaluation approaches for natural language generation, wherein references/ground labels doesn't exist or isn't amply available, this paper introduces a novel framework called "SAGEval" which utilizes a critiquing Agent to provide feedback on scores generated by LLM evaluators. We show that the critiquing Agent is able to rectify scores from LLM evaluators, in absence of references/ground-truth labels, thereby reducing the need for labeled data even for complex NLG evaluation scenarios, like the generation of JSON-structured forms/surveys with responses in different styles like multiple choice, likert ratings, single choice questions, etc.
Would Deep Generative Models Amplify Bias in Future Models?
Apr 04, 2024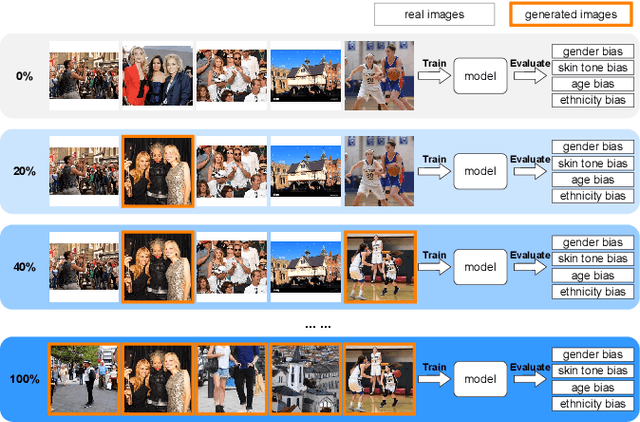
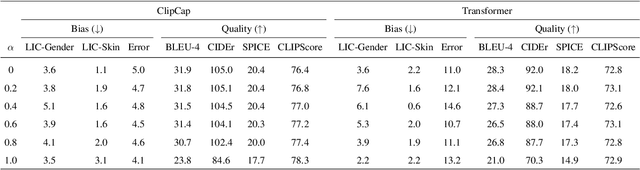
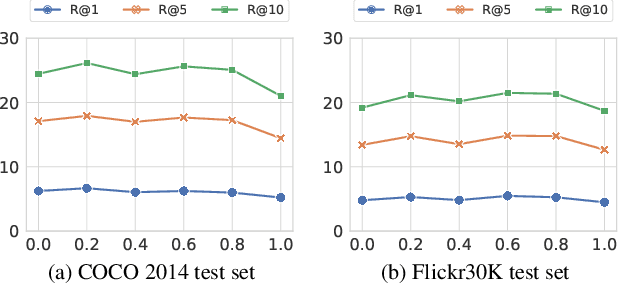
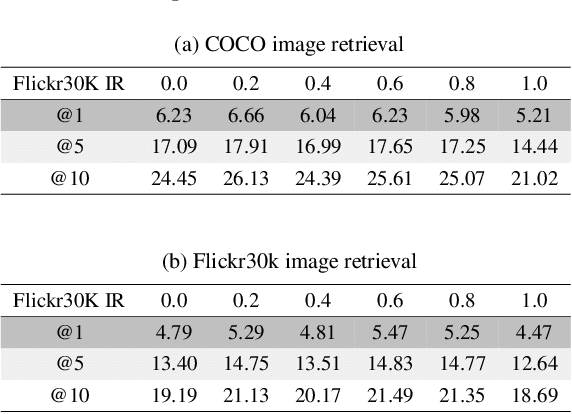
We investigate the impact of deep generative models on potential social biases in upcoming computer vision models. As the internet witnesses an increasing influx of AI-generated images, concerns arise regarding inherent biases that may accompany them, potentially leading to the dissemination of harmful content. This paper explores whether a detrimental feedback loop, resulting in bias amplification, would occur if generated images were used as the training data for future models. We conduct simulations by progressively substituting original images in COCO and CC3M datasets with images generated through Stable Diffusion. The modified datasets are used to train OpenCLIP and image captioning models, which we evaluate in terms of quality and bias. Contrary to expectations, our findings indicate that introducing generated images during training does not uniformly amplify bias. Instead, instances of bias mitigation across specific tasks are observed. We further explore the factors that may influence these phenomena, such as artifacts in image generation (e.g., blurry faces) or pre-existing biases in the original datasets.
Learning More May Not Be Better: Knowledge Transferability in Vision and Language Tasks
Aug 23, 2022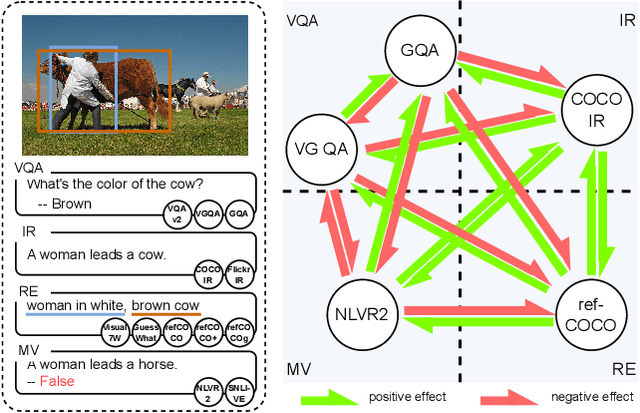
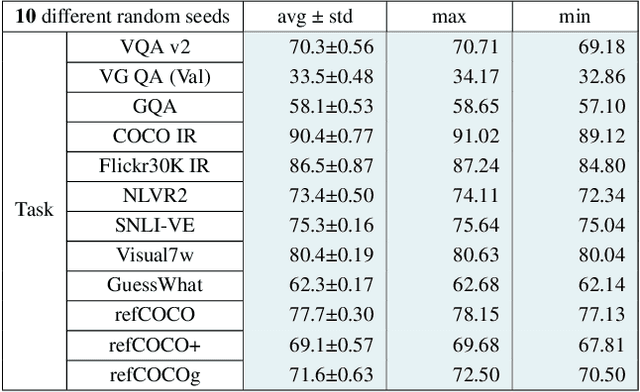
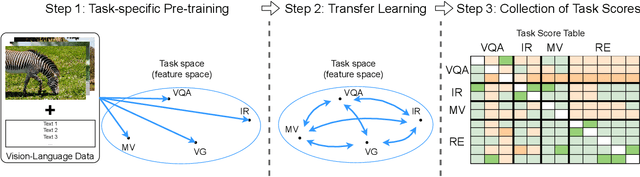
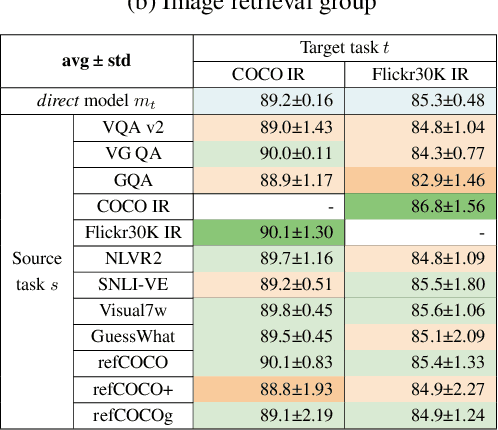
Is more data always better to train vision-and-language models? We study knowledge transferability in multi-modal tasks. The current tendency in machine learning is to assume that by joining multiple datasets from different tasks their overall performance will improve. However, we show that not all the knowledge transfers well or has a positive impact on related tasks, even when they share a common goal. We conduct an exhaustive analysis based on hundreds of cross-experiments on 12 vision-and-language tasks categorized in 4 groups. Whereas tasks in the same group are prone to improve each other, results show that this is not always the case. Other factors such as dataset size or pre-training stage have also a great impact on how well the knowledge is transferred.