 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Numerical Predictive Distributions of LLMs Without Autoregression
Mar 03, 2026Large Language Models (LLMs) have recently been successfully applied to regression tasks -- such as time series forecasting and tabular prediction -- by leveraging their in-context learning abilities. However, their autoregressive decoding process may be ill-suited to continuous-valued outputs, where obtaining predictive distributions over numerical targets requires repeated sampling, leading to high computational cost and inference time. In this work, we investigate whether distributional properties of LLM predictions can be recovered without explicit autoregressive generation. To this end, we study a set of regression probes trained to predict statistical functionals (e.g., mean, median, quantiles) of the LLM's numerical output distribution directly from its internal representations. Our results suggest that LLM embeddings carry informative signals about summary statistics of their predictive distributions, including the numerical uncertainty. This investigation opens up new questions about how LLMs internally encode uncertainty in numerical tasks, and about the feasibility of lightweight alternatives to sampling-based approaches for uncertainty-aware numerical predictions.
Preference Learning for AI Alignment: a Causal Perspective
Jun 06, 2025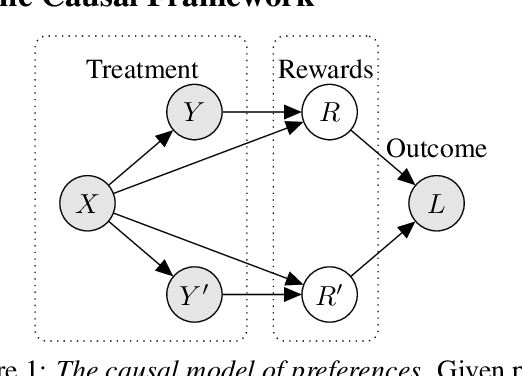
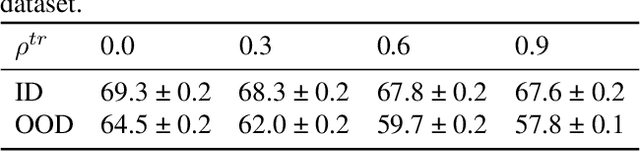
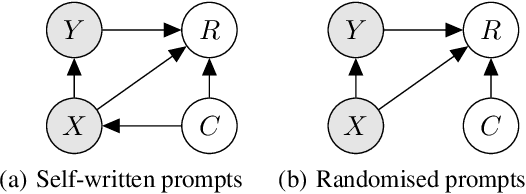
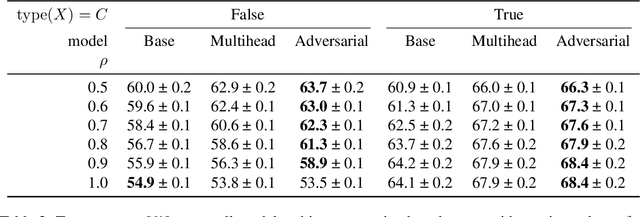
Reward modelling from preference data is a crucial step in aligning large language models (LLMs) with human values, requiring robust generalisation to novel prompt-response pairs. In this work, we propose to frame this problem in a causal paradigm, providing the rich toolbox of causality to identify the persistent challenges, such as causal misidentification, preference heterogeneity, and confounding due to user-specific factors. Inheriting from the literature of causal inference, we identify key assumptions necessary for reliable generalisation and contrast them with common data collection practices. We illustrate failure modes of naive reward models and demonstrate how causally-inspired approaches can improve model robustness. Finally, we outline desiderata for future research and practices, advocating targeted interventions to address inherent limitations of observational data.
Active Task Disambiguation with LLMs
Feb 06, 2025Despite the impressive performance of large language models (LLMs) across various benchmarks, their ability to address ambiguously specified problems--frequent in real-world interactions--remains underexplored. To address this gap, we introduce a formal definition of task ambiguity and frame the problem of task disambiguation through the lens of Bayesian Experimental Design. By posing clarifying questions, LLM agents can acquire additional task specifications, progressively narrowing the space of viable solutions and reducing the risk of generating unsatisfactory outputs. Yet, generating effective clarifying questions requires LLM agents to engage in a form of meta-cognitive reasoning, an ability LLMs may presently lack. Our proposed approach of active task disambiguation enables LLM agents to generate targeted questions maximizing the information gain. Effectively, this approach shifts the load from implicit to explicit reasoning about the space of viable solutions. Empirical results demonstrate that this form of question selection leads to more effective task disambiguation in comparison to approaches relying on reasoning solely within the space of questions.
Few-shot Steerable Alignment: Adapting Rewards and LLM Policies with Neural Processes
Dec 18, 2024



As large language models (LLMs) become increasingly embedded in everyday applications, ensuring their alignment with the diverse preferences of individual users has become a critical challenge. Currently deployed approaches typically assume homogeneous user objectives and rely on single-objective fine-tuning. However, human preferences are inherently heterogeneous, influenced by various unobservable factors, leading to conflicting signals in preference data. Existing solutions addressing this diversity often require costly datasets labelled for specific objectives and involve training multiple reward models or LLM policies, which is computationally expensive and impractical. In this work, we present a novel framework for few-shot steerable alignment, where users' underlying preferences are inferred from a small sample of their choices. To achieve this, we extend the Bradley-Terry-Luce model to handle heterogeneous preferences with unobserved variability factors and propose its practical implementation for reward modelling and LLM fine-tuning. Thanks to our proposed approach of functional parameter-space conditioning, LLMs trained with our framework can be adapted to individual preferences at inference time, generating outputs over a continuum of behavioural modes. We empirically validate the effectiveness of methods, demonstrating their ability to capture and align with diverse human preferences in a data-efficient manner. Our code is made available at: https://github.com/kasia-kobalczyk/few-shot-steerable-alignment.
LLMs for Generalizable Language-Conditioned Policy Learning under Minimal Data Requirements
Dec 09, 2024



To develop autonomous agents capable of executing complex, multi-step decision-making tasks as specified by humans in natural language, existing reinforcement learning approaches typically require expensive labeled datasets or access to real-time experimentation. Moreover, conventional methods often face difficulties in generalizing to unseen goals and states, thereby limiting their practical applicability. This paper presents TEDUO, a novel training pipeline for offline language-conditioned policy learning. TEDUO operates on easy-to-obtain, unlabeled datasets and is suited for the so-called in-the-wild evaluation, wherein the agent encounters previously unseen goals and states. To address the challenges posed by such data and evaluation settings, our method leverages the prior knowledge and instruction-following capabilities of large language models (LLMs) to enhance the fidelity of pre-collected offline data and enable flexible generalization to new goals and states. Empirical results demonstrate that the dual role of LLMs in our framework-as data enhancers and generalizers-facilitates both effective and data-efficient learning of generalizable language-conditioned policies.
Informed Meta-Learning
Feb 25, 2024


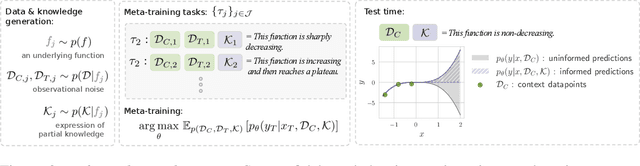
In noisy and low-data regimes prevalent in real-world applications, an outstanding challenge of machine learning lies in effectively incorporating inductive biases that promote data efficiency and robustness. Meta-learning and informed ML stand out as two approaches for incorporating prior knowledge into the ML pipeline. While the former relies on a purely data-driven source of priors, the latter is guided by a formal representation of expert knowledge. This paper introduces a novel hybrid paradigm, informed meta-learning, seeking complementarity in cross-task knowledge sharing of humans and machines. We establish the foundational components of informed meta-learning and present a concrete instantiation of this framework--the Informed Neural Process. Through a series of illustrative and larger-scale experiments, we demonstrate the potential benefits of informed meta-learning in improving data efficiency and robustness to observational noise, task distribution shifts, and heterogeneity.
Tabular Few-Shot Generalization Across Heterogeneous Feature Spaces
Nov 16, 2023Despite the prevalence of tabular datasets, few-shot learning remains under-explored within this domain. Existing few-shot methods are not directly applicable to tabular datasets due to varying column relationships, meanings, and permutational invariance. To address these challenges, we propose FLAT-a novel approach to tabular few-shot learning, encompassing knowledge sharing between datasets with heterogeneous feature spaces. Utilizing an encoder inspired by Dataset2Vec, FLAT learns low-dimensional embeddings of datasets and their individual columns, which facilitate knowledge transfer and generalization to previously unseen datasets. A decoder network parametrizes the predictive target network, implemented as a Graph Attention Network, to accommodate the heterogeneous nature of tabular datasets. Experiments on a diverse collection of 118 UCI datasets demonstrate FLAT's successful generalization to new tabular datasets and a considerable improvement over the baselines.
cegpy: Modelling with Chain Event Graphs in Python
Nov 21, 2022



Chain event graphs (CEGs) are a recent family of probabilistic graphical models that generalise the popular Bayesian networks (BNs) family. Crucially, unlike BNs, a CEG is able to embed, within its graph and its statistical model, asymmetries exhibited by a process. These asymmetries might be in the conditional independence relationships or in the structure of the graph and its underlying event space. Structural asymmetries are common in many domains, and can occur naturally (e.g. a defendant vs prosecutor's version of events) or by design (e.g. a public health intervention). However, there currently exists no software that allows a user to leverage the theoretical developments of the CEG model family in modelling processes with structural asymmetries. This paper introduces cegpy, the first Python package for learning and analysing complex processes using CEGs. The key feature of cegpy is that it is the first CEG package in any programming language that can model processes with symmetric as well as asymmetric structures. cegpy contains an implementation of Bayesian model selection and probability propagation algorithms for CEGs. We illustrate the functionality of cegpy using a structurally asymmetric dataset.