 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXIRL: Cross-embodiment Inverse Reinforcement Learning
Paper and Code
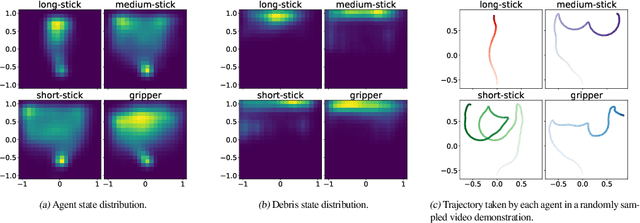

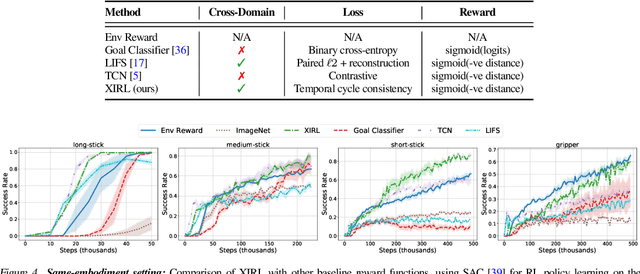
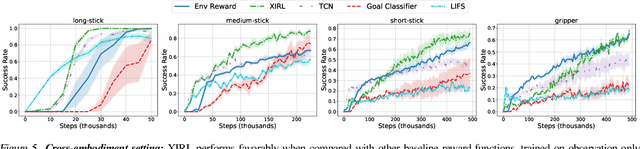
We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings has typically required alignment with a reference trajectory, which may be difficult to acquire. We show empirically that if the embeddings are aware of task-progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. We also find that XIRL policies are more sample efficient than baselines, and in some cases exceed the sample efficiency of the same agent trained with ground truth sparse rewards.