 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
Mar 31, 2023



We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data scale and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 5.6M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Finally, we show that task or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. These models required over 10,000 GPU-hours to train and can be found on our website for the benefit of the research community.
Dexterous Imitation Made Easy: A Learning-Based Framework for Efficient Dexterous Manipulation
Mar 24, 2022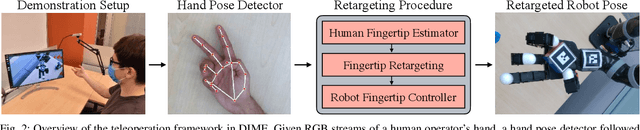



Optimizing behaviors for dexterous manipulation has been a longstanding challenge in robotics, with a variety of methods from model-based control to model-free reinforcement learning having been previously explored in literature. Perhaps one of the most powerful techniques to learn complex manipulation strategies is imitation learning. However, collecting and learning from demonstrations in dexterous manipulation is quite challenging. The complex, high-dimensional action-space involved with multi-finger control often leads to poor sample efficiency of learning-based methods. In this work, we propose 'Dexterous Imitation Made Easy' (DIME) a new imitation learning framework for dexterous manipulation. DIME only requires a single RGB camera to observe a human operator and teleoperate our robotic hand. Once demonstrations are collected, DIME employs standard imitation learning methods to train dexterous manipulation policies. On both simulation and real robot benchmarks we demonstrate that DIME can be used to solve complex, in-hand manipulation tasks such as 'flipping', 'spinning', and 'rotating' objects with the Allegro hand. Our framework along with pre-collected demonstrations is publicly available at https://nyu-robot-learning.github.io/dime.