 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFauna Sprout: A lightweight, approachable, developer-ready humanoid robot
Jan 26, 2026Recent advances in learned control, large-scale simulation, and generative models have accelerated progress toward general-purpose robotic controllers, yet the field still lacks platforms suitable for safe, expressive, long-term deployment in human environments. Most existing humanoids are either closed industrial systems or academic prototypes that are difficult to deploy and operate around people, limiting progress in robotics. We introduce Sprout, a developer platform designed to address these limitations through an emphasis on safety, expressivity, and developer accessibility. Sprout adopts a lightweight form factor with compliant control, limited joint torques, and soft exteriors to support safe operation in shared human spaces. The platform integrates whole-body control, manipulation with integrated grippers, and virtual-reality-based teleoperation within a unified hardware-software stack. An expressive head further enables social interaction -- a domain that remains underexplored on most utilitarian humanoids. By lowering physical and technical barriers to deployment, Sprout expands access to capable humanoid platforms and provides a practical basis for developing embodied intelligence in real human environments.
Holo-Dex: Teaching Dexterity with Immersive Mixed Reality
Oct 12, 2022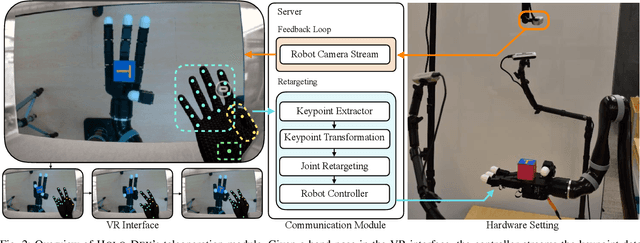



A fundamental challenge in teaching robots is to provide an effective interface for human teachers to demonstrate useful skills to a robot. This challenge is exacerbated in dexterous manipulation, where teaching high-dimensional, contact-rich behaviors often require esoteric teleoperation tools. In this work, we present Holo-Dex, a framework for dexterous manipulation that places a teacher in an immersive mixed reality through commodity VR headsets. The high-fidelity hand pose estimator onboard the headset is used to teleoperate the robot and collect demonstrations for a variety of general-purpose dexterous tasks. Given these demonstrations, we use powerful feature learning combined with non-parametric imitation to train dexterous skills. Our experiments on six common dexterous tasks, including in-hand rotation, spinning, and bottle opening, indicate that Holo-Dex can both collect high-quality demonstration data and train skills in a matter of hours. Finally, we find that our trained skills can exhibit generalization on objects not seen in training. Videos of Holo-Dex are available at https://holo-dex.github.io.
Dexterous Imitation Made Easy: A Learning-Based Framework for Efficient Dexterous Manipulation
Mar 24, 2022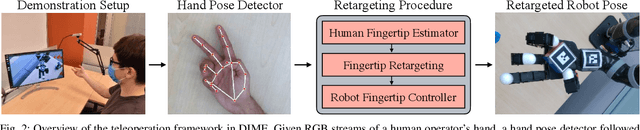



Optimizing behaviors for dexterous manipulation has been a longstanding challenge in robotics, with a variety of methods from model-based control to model-free reinforcement learning having been previously explored in literature. Perhaps one of the most powerful techniques to learn complex manipulation strategies is imitation learning. However, collecting and learning from demonstrations in dexterous manipulation is quite challenging. The complex, high-dimensional action-space involved with multi-finger control often leads to poor sample efficiency of learning-based methods. In this work, we propose 'Dexterous Imitation Made Easy' (DIME) a new imitation learning framework for dexterous manipulation. DIME only requires a single RGB camera to observe a human operator and teleoperate our robotic hand. Once demonstrations are collected, DIME employs standard imitation learning methods to train dexterous manipulation policies. On both simulation and real robot benchmarks we demonstrate that DIME can be used to solve complex, in-hand manipulation tasks such as 'flipping', 'spinning', and 'rotating' objects with the Allegro hand. Our framework along with pre-collected demonstrations is publicly available at https://nyu-robot-learning.github.io/dime.
The Surprising Effectiveness of Representation Learning for Visual Imitation
Dec 06, 2021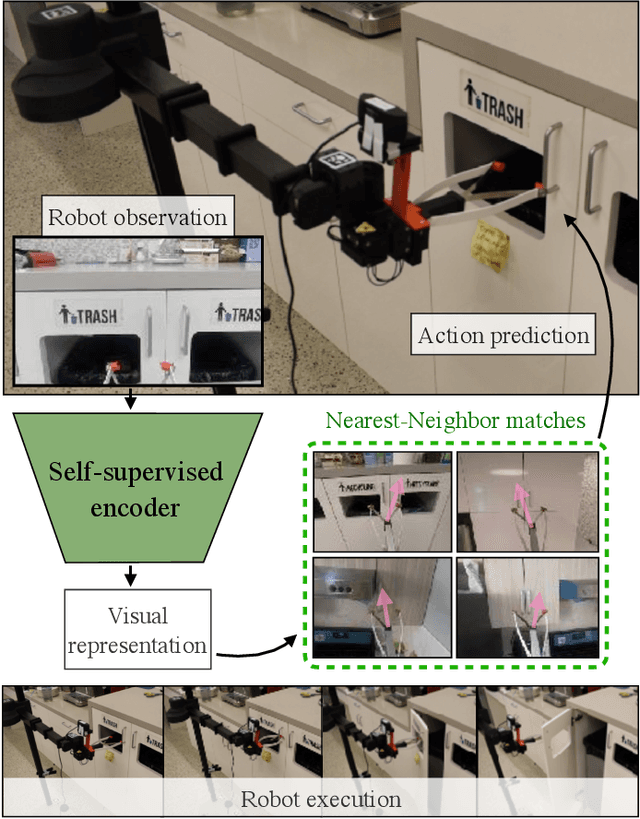
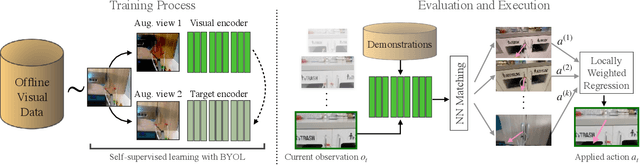

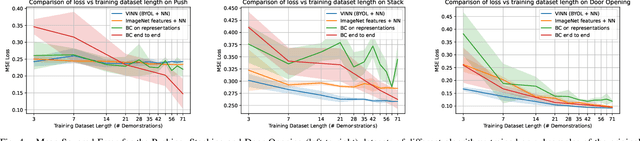
While visual imitation learning offers one of the most effective ways of learning from visual demonstrations, generalizing from them requires either hundreds of diverse demonstrations, task specific priors, or large, hard-to-train parametric models. One reason such complexities arise is because standard visual imitation frameworks try to solve two coupled problems at once: learning a succinct but good representation from the diverse visual data, while simultaneously learning to associate the demonstrated actions with such representations. Such joint learning causes an interdependence between these two problems, which often results in needing large amounts of demonstrations for learning. To address this challenge, we instead propose to decouple representation learning from behavior learning for visual imitation. First, we learn a visual representation encoder from offline data using standard supervised and self-supervised learning methods. Once the representations are trained, we use non-parametric Locally Weighted Regression to predict the actions. We experimentally show that this simple decoupling improves the performance of visual imitation models on both offline demonstration datasets and real-robot door opening compared to prior work in visual imitation. All of our generated data, code, and robot videos are publicly available at https://jyopari.github.io/VINN/.