 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPRA: Video Prediction for Robot Actions
Nov 11, 2025



Can we turn a video prediction model into a robot policy? Videos, including those of humans or teleoperated robots, capture rich physical interactions. However, most of them lack labeled actions, which limits their use in robot learning. We present Video Prediction for Robot Actions (ViPRA), a simple pretraining-finetuning framework that learns continuous robot control from these actionless videos. Instead of directly predicting actions, we train a video-language model to predict both future visual observations and motion-centric latent actions, which serve as intermediate representations of scene dynamics. We train these latent actions using perceptual losses and optical flow consistency to ensure they reflect physically grounded behavior. For downstream control, we introduce a chunked flow matching decoder that maps latent actions to robot-specific continuous action sequences, using only 100 to 200 teleoperated demonstrations. This approach avoids expensive action annotation, supports generalization across embodiments, and enables smooth, high-frequency continuous control upto 22 Hz via chunked action decoding. Unlike prior latent action works that treat pretraining as autoregressive policy learning, explicitly models both what changes and how. Our method outperforms strong baselines, with a 16% gain on the SIMPLER benchmark and a 13% improvement across real world manipulation tasks. We will release models and code at https://vipra-project.github.io
HRP: Human Affordances for Robotic Pre-Training
Jul 26, 2024
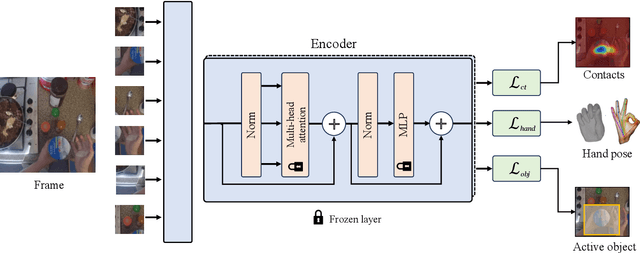
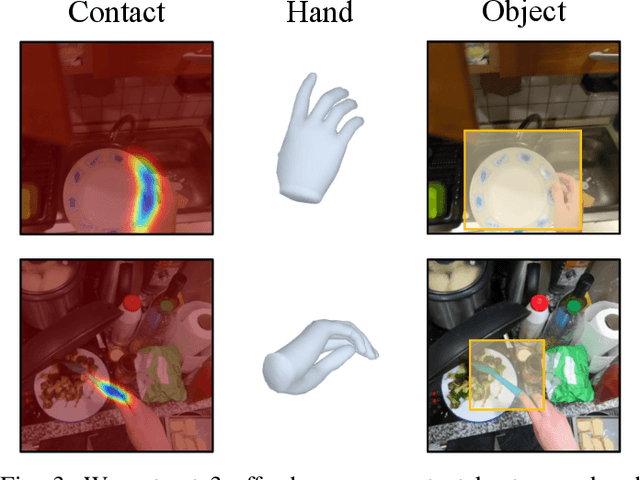
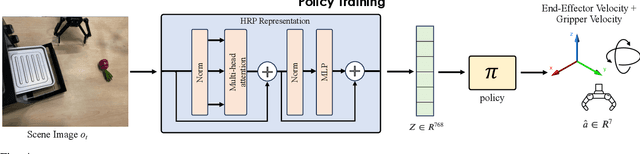
In order to *generalize* to various tasks in the wild, robotic agents will need a suitable representation (i.e., vision network) that enables the robot to predict optimal actions given high dimensional vision inputs. However, learning such a representation requires an extreme amount of diverse training data, which is prohibitively expensive to collect on a real robot. How can we overcome this problem? Instead of collecting more robot data, this paper proposes using internet-scale, human videos to extract "affordances," both at the environment and agent level, and distill them into a pre-trained representation. We present a simple framework for pre-training representations on hand, object, and contact "affordance labels" that highlight relevant objects in images and how to interact with them. These affordances are automatically extracted from human video data (with the help of off-the-shelf computer vision modules) and used to fine-tune existing representations. Our approach can efficiently fine-tune *any* existing representation, and results in models with stronger downstream robotic performance across the board. We experimentally demonstrate (using 3000+ robot trials) that this affordance pre-training scheme boosts performance by a minimum of 15% on 5 real-world tasks, which consider three diverse robot morphologies (including a dexterous hand). Unlike prior works in the space, these representations improve performance across 3 different camera views. Quantitatively, we find that our approach leads to higher levels of generalization in out-of-distribution settings. For code, weights, and data check: https://hrp-robot.github.io
PlayFusion: Skill Acquisition via Diffusion from Language-Annotated Play
Dec 07, 2023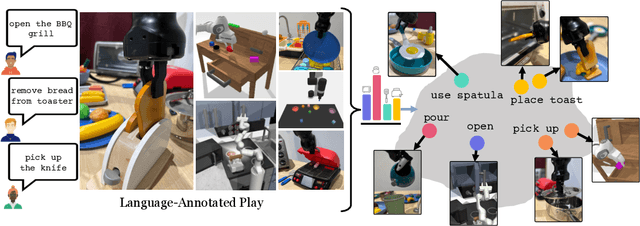
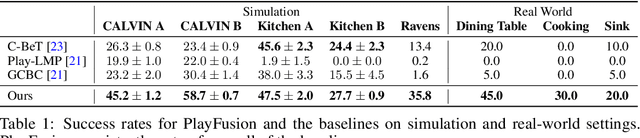
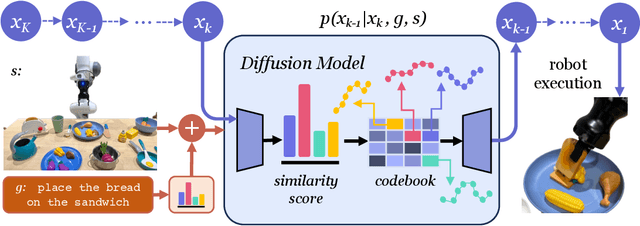
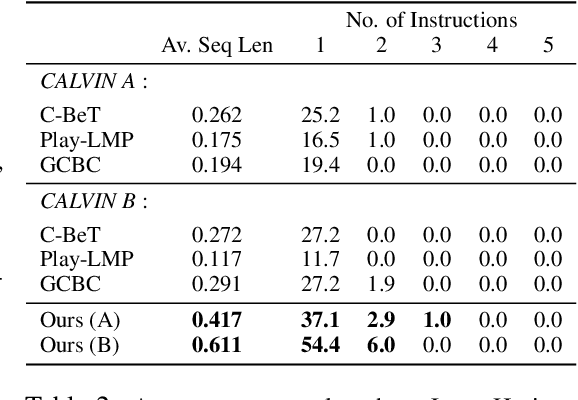
Learning from unstructured and uncurated data has become the dominant paradigm for generative approaches in language and vision. Such unstructured and unguided behavior data, commonly known as play, is also easier to collect in robotics but much more difficult to learn from due to its inherently multimodal, noisy, and suboptimal nature. In this paper, we study this problem of learning goal-directed skill policies from unstructured play data which is labeled with language in hindsight. Specifically, we leverage advances in diffusion models to learn a multi-task diffusion model to extract robotic skills from play data. Using a conditional denoising diffusion process in the space of states and actions, we can gracefully handle the complexity and multimodality of play data and generate diverse and interesting robot behaviors. To make diffusion models more useful for skill learning, we encourage robotic agents to acquire a vocabulary of skills by introducing discrete bottlenecks into the conditional behavior generation process. In our experiments, we demonstrate the effectiveness of our approach across a wide variety of environments in both simulation and the real world. Results visualizations and videos at https://play-fusion.github.io
DEFT: Dexterous Fine-Tuning for Real-World Hand Policies
Oct 30, 2023
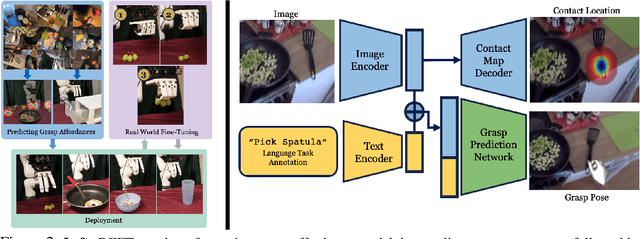
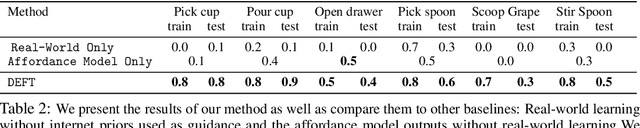

Dexterity is often seen as a cornerstone of complex manipulation. Humans are able to perform a host of skills with their hands, from making food to operating tools. In this paper, we investigate these challenges, especially in the case of soft, deformable objects as well as complex, relatively long-horizon tasks. However, learning such behaviors from scratch can be data inefficient. To circumvent this, we propose a novel approach, DEFT (DExterous Fine-Tuning for Hand Policies), that leverages human-driven priors, which are executed directly in the real world. In order to improve upon these priors, DEFT involves an efficient online optimization procedure. With the integration of human-based learning and online fine-tuning, coupled with a soft robotic hand, DEFT demonstrates success across various tasks, establishing a robust, data-efficient pathway toward general dexterous manipulation. Please see our website at https://dexterous-finetuning.github.io for video results.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Efficient RL via Disentangled Environment and Agent Representations
Sep 05, 2023



Agents that are aware of the separation between themselves and their environments can leverage this understanding to form effective representations of visual input. We propose an approach for learning such structured representations for RL algorithms, using visual knowledge of the agent, such as its shape or mask, which is often inexpensive to obtain. This is incorporated into the RL objective using a simple auxiliary loss. We show that our method, Structured Environment-Agent Representations, outperforms state-of-the-art model-free approaches over 18 different challenging visual simulation environments spanning 5 different robots. Website at https://sear-rl.github.io/
Structured World Models from Human Videos
Aug 21, 2023



We tackle the problem of learning complex, general behaviors directly in the real world. We propose an approach for robots to efficiently learn manipulation skills using only a handful of real-world interaction trajectories from many different settings. Inspired by the success of learning from large-scale datasets in the fields of computer vision and natural language, our belief is that in order to efficiently learn, a robot must be able to leverage internet-scale, human video data. Humans interact with the world in many interesting ways, which can allow a robot to not only build an understanding of useful actions and affordances but also how these actions affect the world for manipulation. Our approach builds a structured, human-centric action space grounded in visual affordances learned from human videos. Further, we train a world model on human videos and fine-tune on a small amount of robot interaction data without any task supervision. We show that this approach of affordance-space world models enables different robots to learn various manipulation skills in complex settings, in under 30 minutes of interaction. Videos can be found at https://human-world-model.github.io
Affordances from Human Videos as a Versatile Representation for Robotics
Apr 17, 2023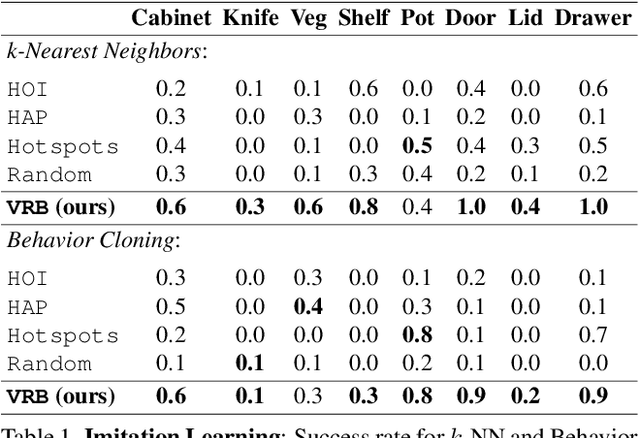
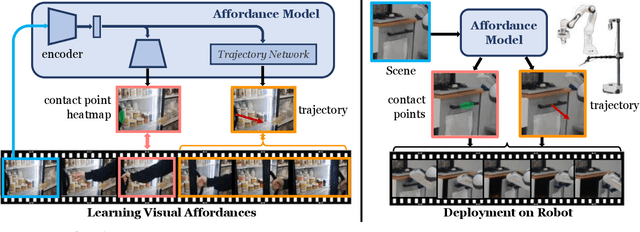
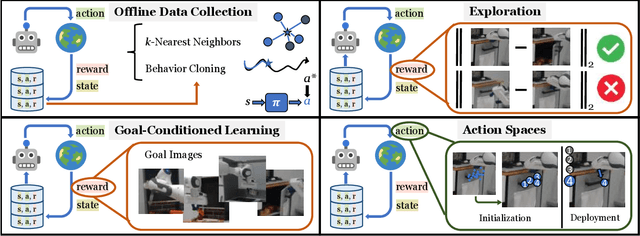

Building a robot that can understand and learn to interact by watching humans has inspired several vision problems. However, despite some successful results on static datasets, it remains unclear how current models can be used on a robot directly. In this paper, we aim to bridge this gap by leveraging videos of human interactions in an environment centric manner. Utilizing internet videos of human behavior, we train a visual affordance model that estimates where and how in the scene a human is likely to interact. The structure of these behavioral affordances directly enables the robot to perform many complex tasks. We show how to seamlessly integrate our affordance model with four robot learning paradigms including offline imitation learning, exploration, goal-conditioned learning, and action parameterization for reinforcement learning. We show the efficacy of our approach, which we call VRB, across 4 real world environments, over 10 different tasks, and 2 robotic platforms operating in the wild. Results, visualizations and videos at https://robo-affordances.github.io/
ALAN: Autonomously Exploring Robotic Agents in the Real World
Feb 13, 2023Robotic agents that operate autonomously in the real world need to continuously explore their environment and learn from the data collected, with minimal human supervision. While it is possible to build agents that can learn in such a manner without supervision, current methods struggle to scale to the real world. Thus, we propose ALAN, an autonomously exploring robotic agent, that can perform tasks in the real world with little training and interaction time. This is enabled by measuring environment change, which reflects object movement and ignores changes in the robot position. We use this metric directly as an environment-centric signal, and also maximize the uncertainty of predicted environment change, which provides agent-centric exploration signal. We evaluate our approach on two different real-world play kitchen settings, enabling a robot to efficiently explore and discover manipulation skills, and perform tasks specified via goal images. Website at https://robo-explorer.github.io/
VideoDex: Learning Dexterity from Internet Videos
Dec 08, 2022To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time, and hardware restrictions. We thus propose leveraging the next best thing as real-world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action, and physical priors from human video datasets to guide robot behavior. These actions and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand-based system and show strong results on various manipulation tasks, outperforming various state-of-the-art methods. Videos at https://video-dex.github.io