 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIITG-ADBU@HASOC-Dravidian-CodeMix-FIRE2020: Offensive Content Detection in Code-Mixed Dravidian Text
Jul 29, 2021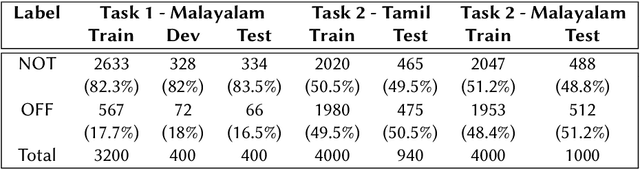
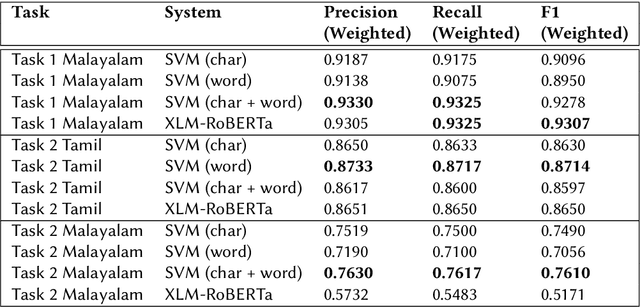
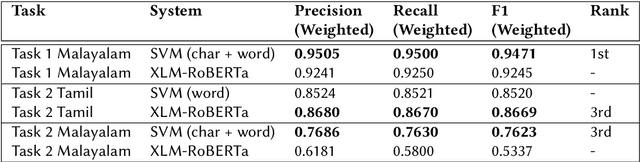
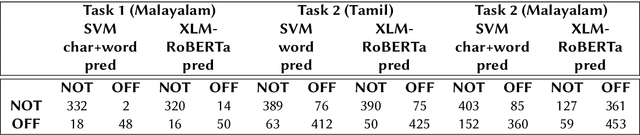
This paper presents the results obtained by our SVM and XLM-RoBERTa based classifiers in the shared task Dravidian-CodeMix-HASOC 2020. The SVM classifier trained using TF-IDF features of character and word n-grams performed the best on the code-mixed Malayalam text. It obtained a weighted F1 score of 0.95 (1st Rank) and 0.76 (3rd Rank) on the YouTube and Twitter dataset respectively. The XLM-RoBERTa based classifier performed the best on the code-mixed Tamil text. It obtained a weighted F1 score of 0.87 (3rd Rank) on the code-mixed Tamil Twitter dataset.
A Survey of Named Entity Recognition in Assamese and other Indian Languages
Jul 09, 2014
Named Entity Recognition is always important when dealing with major Natural Language Processing tasks such as information extraction, question-answering, machine translation, document summarization etc so in this paper we put forward a survey of Named Entities in Indian Languages with particular reference to Assamese. There are various rule-based and machine learning approaches available for Named Entity Recognition. At the very first of the paper we give an idea of the available approaches for Named Entity Recognition and then we discuss about the related research in this field. Assamese like other Indian languages is agglutinative and suffers from lack of appropriate resources as Named Entity Recognition requires large data sets, gazetteer list, dictionary etc and some useful feature like capitalization as found in English cannot be found in Assamese. Apart from this we also describe some of the issues faced in Assamese while doing Named Entity Recognition.