Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIITG-ADBU@HASOC-Dravidian-CodeMix-FIRE2020: Offensive Content Detection in Code-Mixed Dravidian Text
Jul 29, 2021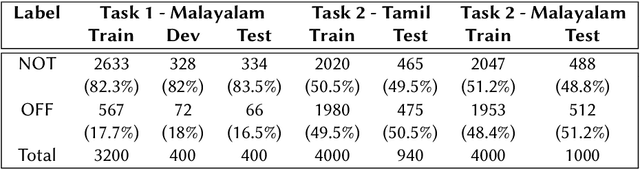
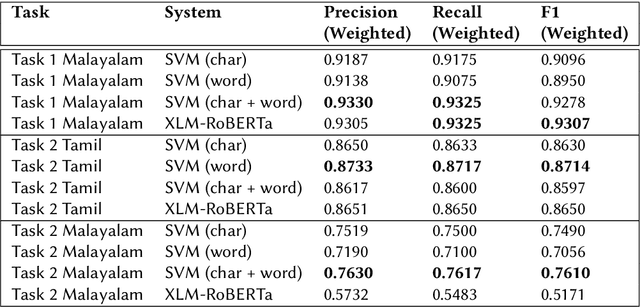
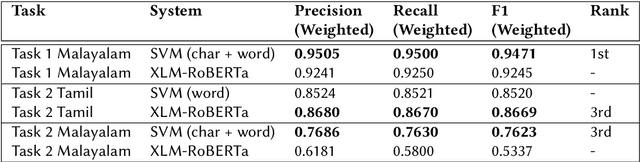
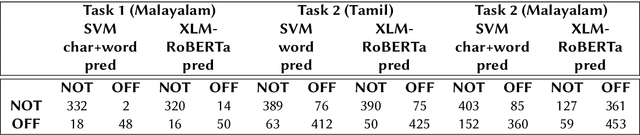
This paper presents the results obtained by our SVM and XLM-RoBERTa based classifiers in the shared task Dravidian-CodeMix-HASOC 2020. The SVM classifier trained using TF-IDF features of character and word n-grams performed the best on the code-mixed Malayalam text. It obtained a weighted F1 score of 0.95 (1st Rank) and 0.76 (3rd Rank) on the YouTube and Twitter dataset respectively. The XLM-RoBERTa based classifier performed the best on the code-mixed Tamil text. It obtained a weighted F1 score of 0.87 (3rd Rank) on the code-mixed Tamil Twitter dataset.
* CEUR, 2020
Via