 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan, Watch, Recover: A Benchmark and Architectures for Proactive Procedural Assistance
Jun 03, 2026We envision a proactive multi-modal assistant system which gives users real-time step-by-step guidance on a procedural task, autonomously deciding \textit{when} to interrupt, and \textit{how} to coach. However, progress is limited by the absence of large-scale, cross-domain benchmarks that reflect realistic conditions, particularly the common case in which users deviate from the expected step sequence. We address this gap with four contributions: \textbf{(1)}~we release \textbf{EgoProactive}, a large-scale wearable-egocentric dataset for proactive procedural assistance with explicit Out-of-Plan (OOP) annotations and recovery steps; \textbf{(2)}~we augment five established benchmarks (Ego4D, EPIC-KITCHENS, EgoExo4D, HoloAssist, HowTo100M) into \textbf{Pro\textsuperscript{2}Bench} under a unified proactive-guidance schema; \textbf{(3)}~we propose a \textbf{decoupled planner--interaction architecture} specialized for procedural state, visual cues, and recovery injection; \textbf{(4)}~we introduce a post-training recipe that transfers across model families, validated by cross-backbone replication on Llama~4 and Qwen-3.6-VL. In extensive experiments, our trained Llama-4 system substantially improves objective intervention quality over strong proprietary baselines (Claude Opus~4.6, Gemini~3.1~Pro, GPT~5.2) and open-weight baselines (Qwen3~VL~235B) baselines across all six datasets. Oracle-plan experiments further show that, when plan quality is controlled, the trained duplex model produces high-quality guidance and large gains on Out-of-Plan recovery.
LLM-Based Insight Extraction for Contact Center Analytics and Cost-Efficient Deployment
Mar 24, 2025



Large Language Models have transformed the Contact Center industry, manifesting in enhanced self-service tools, streamlined administrative processes, and augmented agent productivity. This paper delineates our system that automates call driver generation, which serves as the foundation for tasks such as topic modeling, incoming call classification, trend detection, and FAQ generation, delivering actionable insights for contact center agents and administrators to consume. We present a cost-efficient LLM system design, with 1) a comprehensive evaluation of proprietary, open-weight, and fine-tuned models and 2) cost-efficient strategies, and 3) the corresponding cost analysis when deployed in production environments.
"Laughing at you or with you": The Role of Sarcasm in Shaping the Disagreement Space
Jan 26, 2021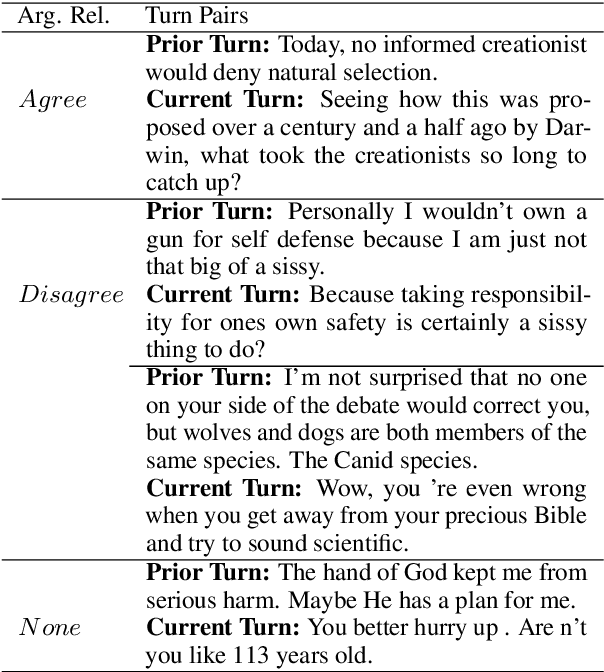
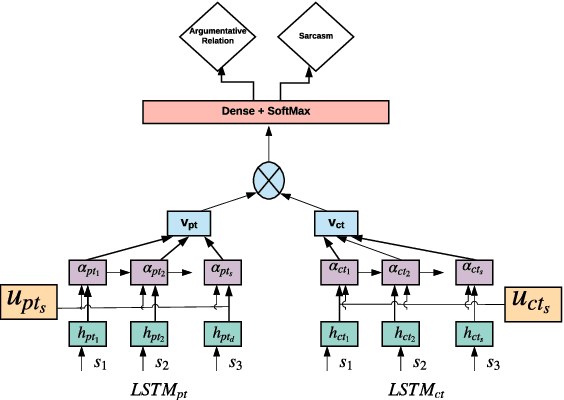
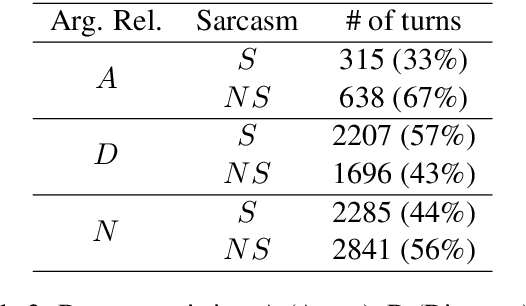
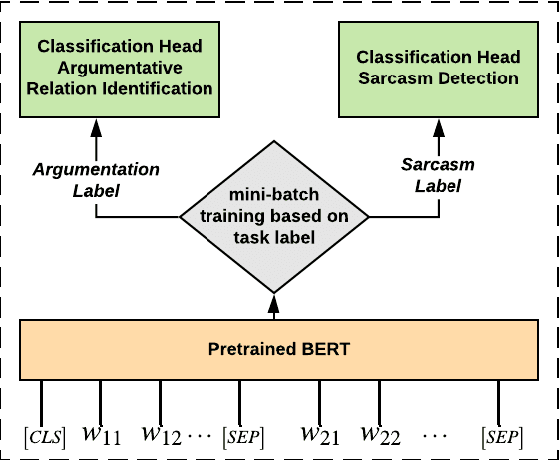
Detecting arguments in online interactions is useful to understand how conflicts arise and get resolved. Users often use figurative language, such as sarcasm, either as persuasive devices or to attack the opponent by an ad hominem argument. To further our understanding of the role of sarcasm in shaping the disagreement space, we present a thorough experimental setup using a corpus annotated with both argumentative moves (agree/disagree) and sarcasm. We exploit joint modeling in terms of (a) applying discrete features that are useful in detecting sarcasm to the task of argumentative relation classification (agree/disagree/none), and (b) multitask learning for argumentative relation classification and sarcasm detection using deep learning architectures (e.g., dual Long Short-Term Memory (LSTM) with hierarchical attention and Transformer-based architectures). We demonstrate that modeling sarcasm improves the argumentative relation classification task (agree/disagree/none) in all setups.
Topical Stance Detection for Twitter: A Two-Phase LSTM Model Using Attention
Jan 09, 2018
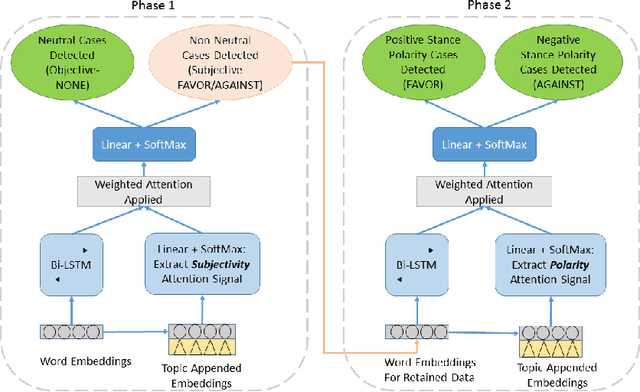
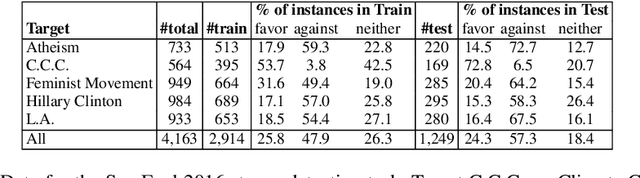

The topical stance detection problem addresses detecting the stance of the text content with respect to a given topic: whether the sentiment of the given text content is in FAVOR of (positive), is AGAINST (negative), or is NONE (neutral) towards the given topic. Using the concept of attention, we develop a two-phase solution. In the first phase, we classify subjectivity - whether a given tweet is neutral or subjective with respect to the given topic. In the second phase, we classify sentiment of the subjective tweets (ignoring the neutral tweets) - whether a given subjective tweet has a FAVOR or AGAINST stance towards the topic. We propose a Long Short-Term memory (LSTM) based deep neural network for each phase, and embed attention at each of the phases. On the SemEval 2016 stance detection Twitter task dataset, we obtain a best-case macro F-score of 68.84% and a best-case accuracy of 60.2%, outperforming the existing deep learning based solutions. Our framework, T-PAN, is the first in the topical stance detection literature, that uses deep learning within a two-phase architecture.
EmTaggeR: A Word Embedding Based Novel Method for Hashtag Recommendation on Twitter
Dec 05, 2017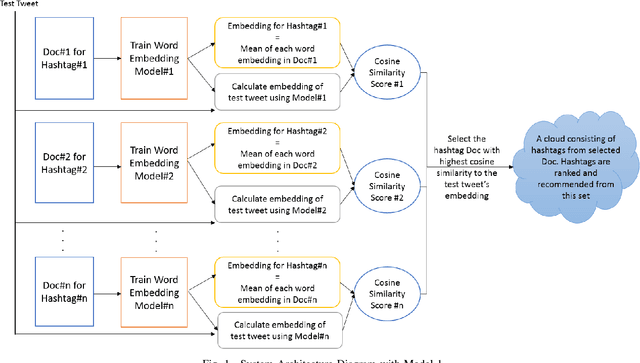
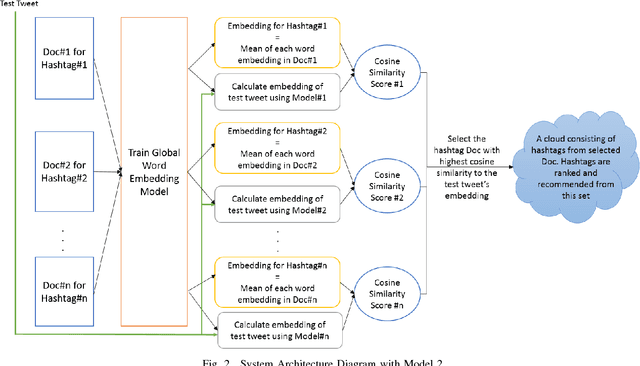
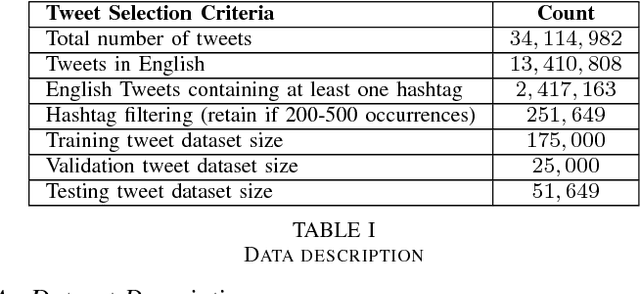

The hashtag recommendation problem addresses recommending (suggesting) one or more hashtags to explicitly tag a post made on a given social network platform, based upon the content and context of the post. In this work, we propose a novel methodology for hashtag recommendation for microblog posts, specifically Twitter. The methodology, EmTaggeR, is built upon a training-testing framework that builds on the top of the concept of word embedding. The training phase comprises of learning word vectors associated with each hashtag, and deriving a word embedding for each hashtag. We provide two training procedures, one in which each hashtag is trained with a separate word embedding model applicable in the context of that hashtag, and another in which each hashtag obtains its embedding from a global context. The testing phase constitutes computing the average word embedding of the test post, and finding the similarity of this embedding with the known embeddings of the hashtags. The tweets that contain the most-similar hashtag are extracted, and all the hashtags that appear in these tweets are ranked in terms of embedding similarity scores. The top-K hashtags that appear in this ranked list, are recommended for the given test post. Our system produces F1 score of 50.83%, improving over the LDA baseline by around 6.53 times, outperforming the best-performing system known in the literature that provides a lift of 6.42 times. EmTaggeR is a fast, scalable and lightweight system, which makes it practical to deploy in real-life applications.
A Big Data Analysis Framework Using Apache Spark and Deep Learning
Nov 25, 2017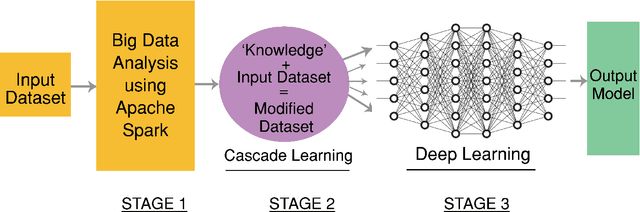
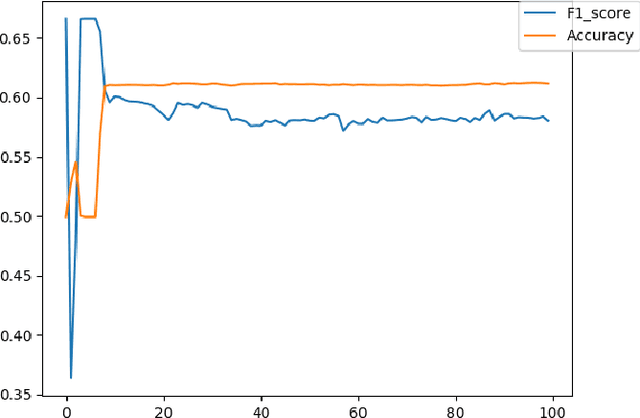
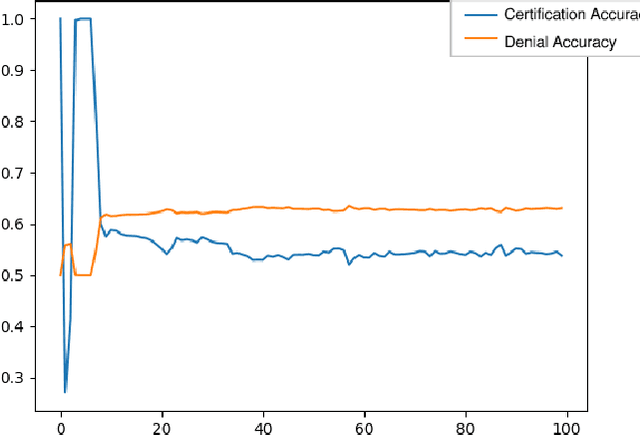
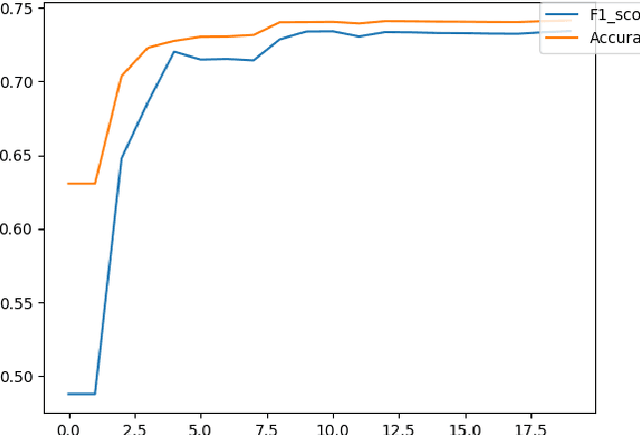
With the spreading prevalence of Big Data, many advances have recently been made in this field. Frameworks such as Apache Hadoop and Apache Spark have gained a lot of traction over the past decades and have become massively popular, especially in industries. It is becoming increasingly evident that effective big data analysis is key to solving artificial intelligence problems. Thus, a multi-algorithm library was implemented in the Spark framework, called MLlib. While this library supports multiple machine learning algorithms, there is still scope to use the Spark setup efficiently for highly time-intensive and computationally expensive procedures like deep learning. In this paper, we propose a novel framework that combines the distributive computational abilities of Apache Spark and the advanced machine learning architecture of a deep multi-layer perceptron (MLP), using the popular concept of Cascade Learning. We conduct empirical analysis of our framework on two real world datasets. The results are encouraging and corroborate our proposed framework, in turn proving that it is an improvement over traditional big data analysis methods that use either Spark or Deep learning as individual elements.