 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopical Stance Detection for Twitter: A Two-Phase LSTM Model Using Attention
Jan 09, 2018
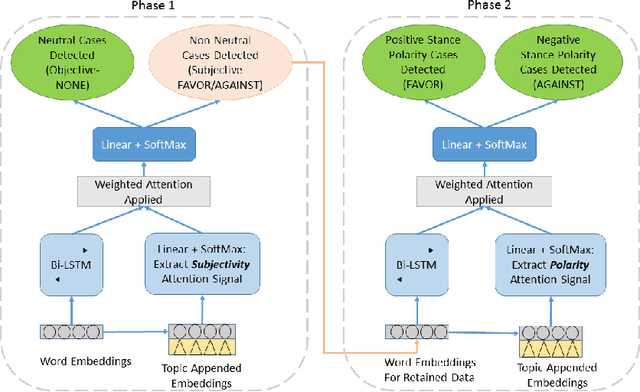
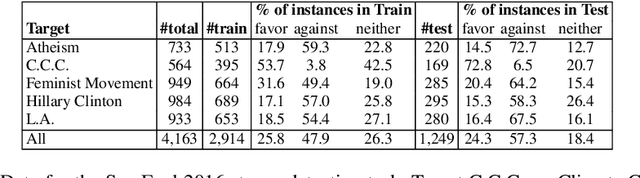

The topical stance detection problem addresses detecting the stance of the text content with respect to a given topic: whether the sentiment of the given text content is in FAVOR of (positive), is AGAINST (negative), or is NONE (neutral) towards the given topic. Using the concept of attention, we develop a two-phase solution. In the first phase, we classify subjectivity - whether a given tweet is neutral or subjective with respect to the given topic. In the second phase, we classify sentiment of the subjective tweets (ignoring the neutral tweets) - whether a given subjective tweet has a FAVOR or AGAINST stance towards the topic. We propose a Long Short-Term memory (LSTM) based deep neural network for each phase, and embed attention at each of the phases. On the SemEval 2016 stance detection Twitter task dataset, we obtain a best-case macro F-score of 68.84% and a best-case accuracy of 60.2%, outperforming the existing deep learning based solutions. Our framework, T-PAN, is the first in the topical stance detection literature, that uses deep learning within a two-phase architecture.
EmTaggeR: A Word Embedding Based Novel Method for Hashtag Recommendation on Twitter
Dec 05, 2017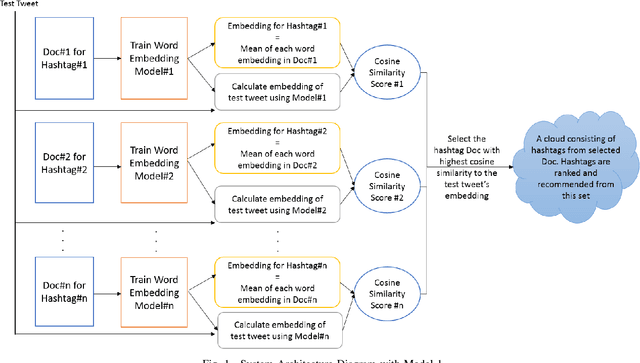
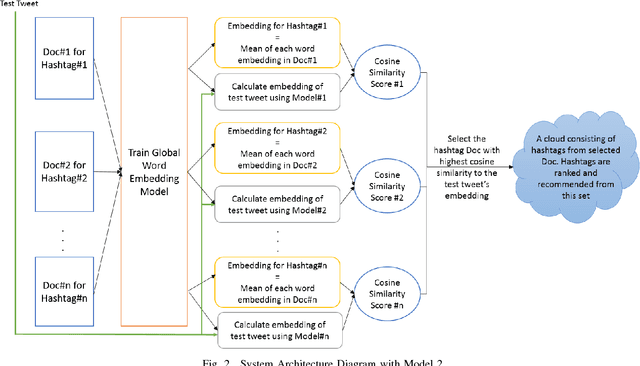
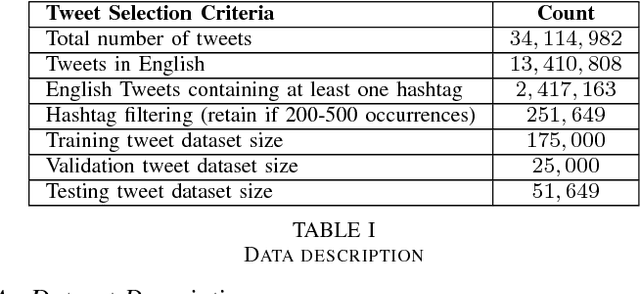

The hashtag recommendation problem addresses recommending (suggesting) one or more hashtags to explicitly tag a post made on a given social network platform, based upon the content and context of the post. In this work, we propose a novel methodology for hashtag recommendation for microblog posts, specifically Twitter. The methodology, EmTaggeR, is built upon a training-testing framework that builds on the top of the concept of word embedding. The training phase comprises of learning word vectors associated with each hashtag, and deriving a word embedding for each hashtag. We provide two training procedures, one in which each hashtag is trained with a separate word embedding model applicable in the context of that hashtag, and another in which each hashtag obtains its embedding from a global context. The testing phase constitutes computing the average word embedding of the test post, and finding the similarity of this embedding with the known embeddings of the hashtags. The tweets that contain the most-similar hashtag are extracted, and all the hashtags that appear in these tweets are ranked in terms of embedding similarity scores. The top-K hashtags that appear in this ranked list, are recommended for the given test post. Our system produces F1 score of 50.83%, improving over the LDA baseline by around 6.53 times, outperforming the best-performing system known in the literature that provides a lift of 6.42 times. EmTaggeR is a fast, scalable and lightweight system, which makes it practical to deploy in real-life applications.