 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Native Memes to Global Moderation: Cross-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection
Feb 11, 2026Cultural context profoundly shapes how people interpret online content, yet vision-language models (VLMs) remain predominantly trained through Western or English-centric lenses. This limits their fairness and cross-cultural robustness in tasks like hateful meme detection. We introduce a systematic evaluation framework designed to diagnose and quantify the cross-cultural robustness of state-of-the-art VLMs across multilingual meme datasets, analyzing three axes: (i) learning strategy (zero-shot vs. one-shot), (ii) prompting language (native vs. English), and (iii) translation effects on meaning and detection. Results show that the common ``translate-then-detect'' approach deteriorate performance, while culturally aligned interventions - native-language prompting and one-shot learning - significantly enhance detection. Our findings reveal systematic convergence toward Western safety norms and provide actionable strategies to mitigate such bias, guiding the design of globally robust multimodal moderation systems.
From Native Memes to Global Moderation: Cros-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection
Feb 07, 2026Cultural context profoundly shapes how people interpret online content, yet vision-language models (VLMs) remain predominantly trained through Western or English-centric lenses. This limits their fairness and cross-cultural robustness in tasks like hateful meme detection. We introduce a systematic evaluation framework designed to diagnose and quantify the cross-cultural robustness of state-of-the-art VLMs across multilingual meme datasets, analyzing three axes: (i) learning strategy (zero-shot vs. one-shot), (ii) prompting language (native vs. English), and (iii) translation effects on meaning and detection. Results show that the common ``translate-then-detect'' approach deteriorate performance, while culturally aligned interventions - native-language prompting and one-shot learning - significantly enhance detection. Our findings reveal systematic convergence toward Western safety norms and provide actionable strategies to mitigate such bias, guiding the design of globally robust multimodal moderation systems.
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Jun 11, 2025Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
LOCO-EPI: Leave-one-chromosome-out (LOCO) as a benchmarking paradigm for deep learning based prediction of enhancer-promoter interactions
Apr 01, 2025In mammalian and vertebrate genomes, the promoter regions of the gene and their distal enhancers may be located millions of base-pairs from each other, while a promoter may not interact with the closest enhancer. Since base-pair proximity is not a good indicator of these interactions, there is considerable work toward developing methods for predicting Enhancer-Promoter Interactions (EPI). Several machine learning methods have reported increasingly higher accuracies for predicting EPI. Typically, these approaches randomly split the dataset of Enhancer-Promoter (EP) pairs into training and testing subsets followed by model training. However, the aforementioned random splitting causes information leakage by assigning EP pairs from the same genomic region to both testing and training sets, leading to performance overestimation. In this paper we propose to use a more thorough training and testing paradigm i.e., Leave-one-chromosome-out (LOCO) cross-validation for EPI-prediction. We demonstrate that a deep learning algorithm, which gives higher accuracies when trained and tested on random-splitting setting, drops drastically in performance under LOCO setting, confirming overestimation of performance. We further propose a novel hybrid deep neural network for EPI-prediction that fuses k-mer features of the nucleotide sequence. We show that the hybrid architecture performs significantly better in the LOCO setting, demonstrating it can learn more generalizable aspects of EP interactions. With this paper we are also releasing the LOCO splitting-based EPI dataset. Research data is available in this public repository: https://github.com/malikmtahir/EPI
AraTrust: An Evaluation of Trustworthiness for LLMs in Arabic
Mar 15, 2024



The swift progress and widespread acceptance of artificial intelligence (AI) systems highlight a pressing requirement to comprehend both the capabilities and potential risks associated with AI. Given the linguistic complexity, cultural richness, and underrepresented status of Arabic in AI research, there is a pressing need to focus on Large Language Models (LLMs) performance and safety for Arabic related tasks. Despite some progress in their development, there is a lack of comprehensive trustworthiness evaluation benchmarks which presents a major challenge in accurately assessing and improving the safety of LLMs when prompted in Arabic. In this paper, we introduce AraTrust, the first comprehensive trustworthiness benchmark for LLMs in Arabic. AraTrust comprises 516 human-written multiple-choice questions addressing diverse dimensions related to truthfulness, ethics, safety, physical health, mental health, unfairness, illegal activities, privacy, and offensive language. We evaluated a set of LLMs against our benchmark to assess their trustworthiness. GPT-4 was the most trustworthy LLM, while open-source models, particularly AceGPT 7B and Jais 13B, struggled to achieve a score of 60% in our benchmark.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
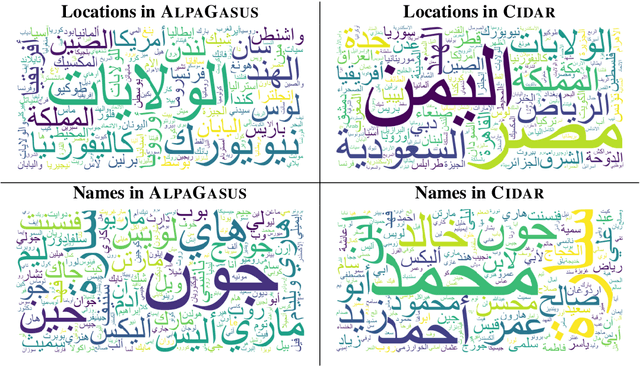
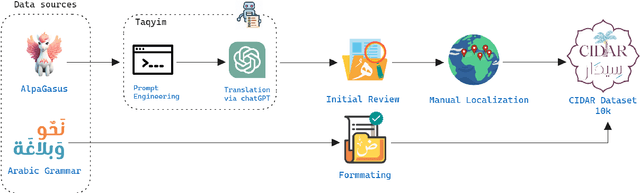

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
Learning to Unlearn: Building Immunity to Dataset Bias in Medical Imaging Studies
Dec 03, 2018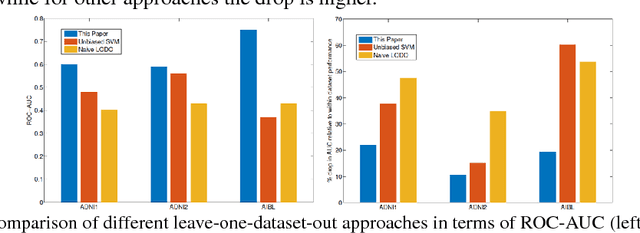
Medical imaging machine learning algorithms are usually evaluated on a single dataset. Although training and testing are performed on different subsets of the dataset, models built on one study show limited capability to generalize to other studies. While database bias has been recognized as a serious problem in the computer vision community, it has remained largely unnoticed in medical imaging research. Transfer learning thus remains confined to the re-use of feature representations requiring re-training on the new dataset. As a result, machine learning models do not generalize even when trained on imaging datasets that were captured to study the same variable of interest. The ability to transfer knowledge gleaned from one study to another, without the need for re-training, if possible, would provide reassurance that the models are learning knowledge fundamental to the problem under study instead of latching onto the idiosyncracies of a dataset. In this paper, we situate the problem of dataset bias in the context of medical imaging studies. We show empirical evidence that such a problem exists in medical datasets. We then present a framework to unlearn study membership as a means to handle the problem of database bias. Our main idea is to take the data from the original feature space to an intermediate space where the data points are indistinguishable in terms of which study they come from, while maintaining the recognition capability with respect to the variable of interest. This will promote models which learn the more general properties of the etiology under study instead of aligning to dataset-specific peculiarities. Essentially, our proposed model learns to unlearn the dataset bias.
Video Analysis of "YouTube Funnies" to Aid the Study of Human Gait and Falls - Preliminary Results and Proof of Concept
Oct 26, 2016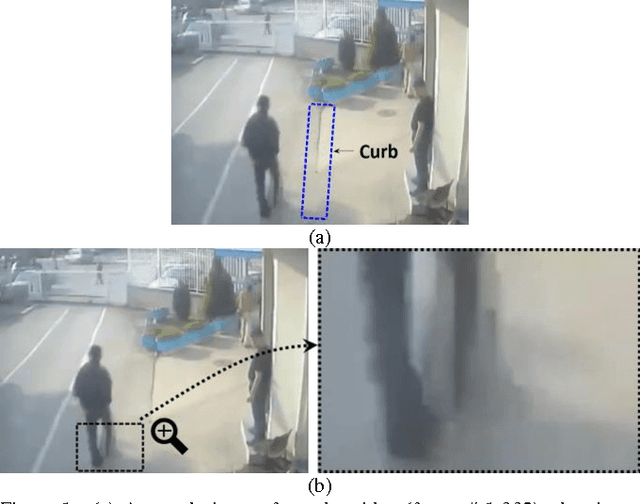


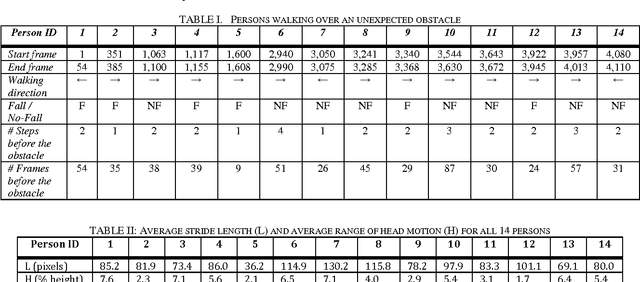
Because falls are funny, YouTube and other video sharing sites contain a large repository of real-life falls. We propose extracting gait and balance information from these videos to help us better understand some of the factors that contribute to falls. Proof-of-concept is explored in a single video containing multiple (n=14) falls/non-falls in the presence of an unexpected obstacle. The analysis explores: computing spatiotemporal parameters of gait in a video captured from an arbitrary viewpoint; the relationship between parameters of gait from the last few steps before the obstacle and falling vs. not falling; and the predictive capacity of a multivariate model in predicting a fall in the presence of an unexpected obstacle. Homography transformations correct the perspective projection distortion and allow for the consistent tracking of gait parameters as an individual walks in an arbitrary direction in the scene. A synthetic top view allows for computing the average stride length and a synthetic side view allows for measuring up and down motions of the head. In leave-one-out cross-validation, we were able to correctly predict whether a person would fall or not in 11 out of the 14 cases (78.6%), just by looking at the average stride length and the range of vertical head motion during the 1-4 most recent steps prior to reaching the obstacle.