 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Testing (FedTest): A New Scheme to Enhance Convergence and Mitigate Adversarial Attacks in Federating Learning
Jan 19, 2025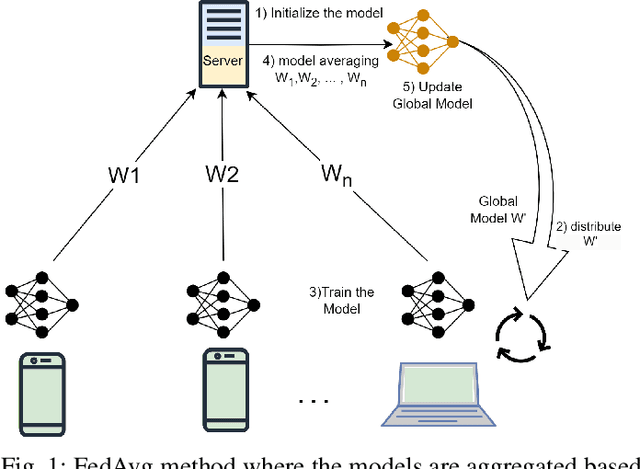
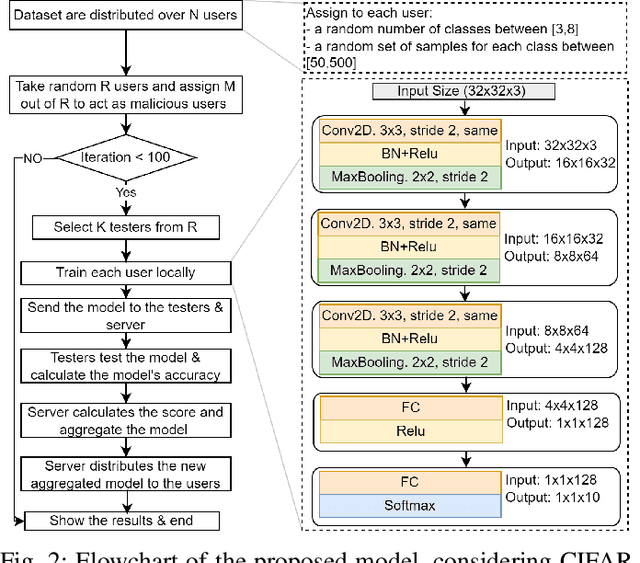
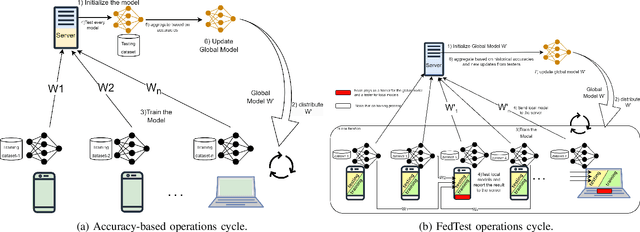
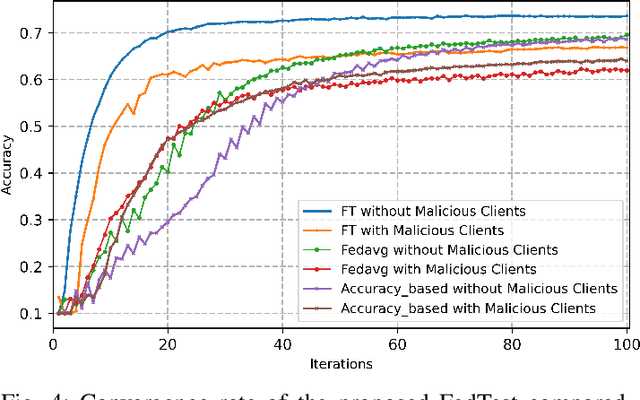
Federated Learning (FL) has emerged as a significant paradigm for training machine learning models. This is due to its data-privacy-preserving property and its efficient exploitation of distributed computational resources. This is achieved by conducting the training process in parallel at distributed users. However, traditional FL strategies grapple with difficulties in evaluating the quality of received models, handling unbalanced models, and reducing the impact of detrimental models. To resolve these problems, we introduce a novel federated learning framework, which we call federated testing for federated learning (FedTest). In the FedTest method, the local data of a specific user is used to train the model of that user and test the models of the other users. This approach enables users to test each other's models and determine an accurate score for each. This score can then be used to aggregate the models efficiently and identify any malicious ones. Our numerical results reveal that the proposed method not only accelerates convergence rates but also diminishes the potential influence of malicious users. This significantly enhances the overall efficiency and robustness of FL systems.
Towards a Transformer-Based Pre-trained Model for IoT Traffic Classification
Jul 26, 2024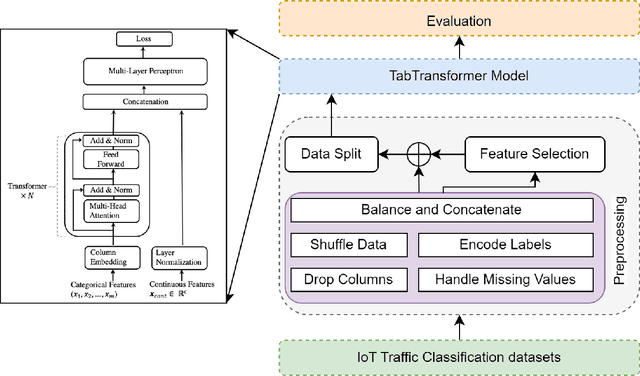
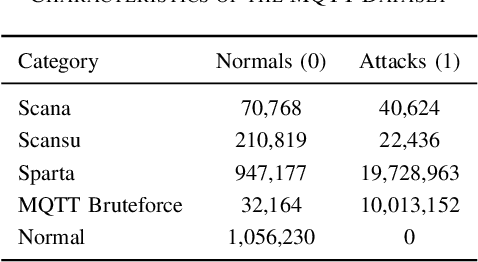
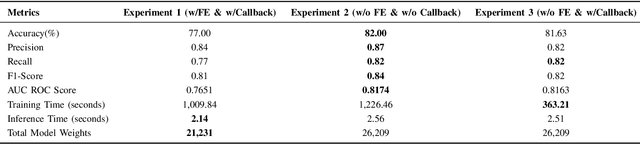
The classification of IoT traffic is important to improve the efficiency and security of IoT-based networks. As the state-of-the-art classification methods are based on Deep Learning, most of the current results require a large amount of data to be trained. Thereby, in real-life situations, where there is a scarce amount of IoT traffic data, the models would not perform so well. Consequently, these models underperform outside their initial training conditions and fail to capture the complex characteristics of network traffic, rendering them inefficient and unreliable in real-world applications. In this paper, we propose IoT Traffic Classification Transformer (ITCT), a novel approach that utilizes the state-of-the-art transformer-based model named TabTransformer. ITCT, which is pre-trained on a large labeled MQTT-based IoT traffic dataset and may be fine-tuned with a small set of labeled data, showed promising results in various traffic classification tasks. Our experiments demonstrated that the ITCT model significantly outperforms existing models, achieving an overall accuracy of 82%. To support reproducibility and collaborative development, all associated code has been made publicly available.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
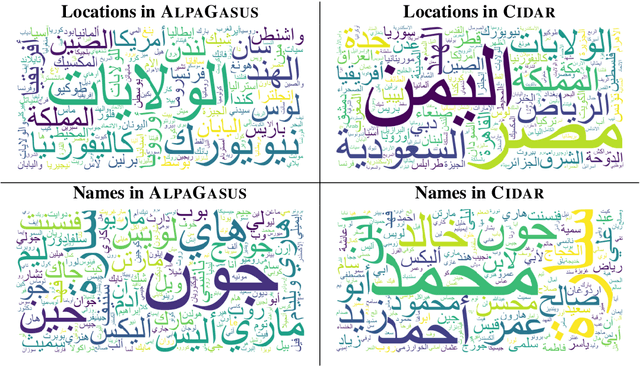
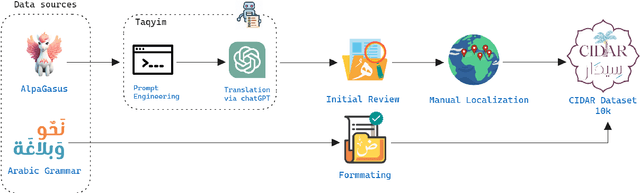

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Masader Plus: A New Interface for Exploring +500 Arabic NLP Datasets
Aug 01, 2022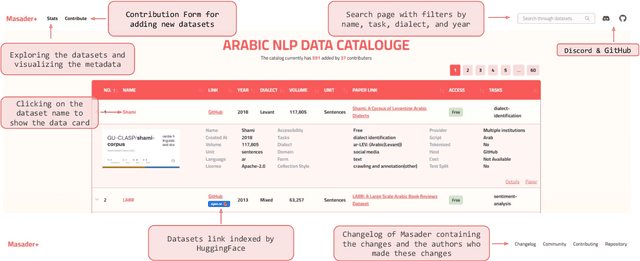
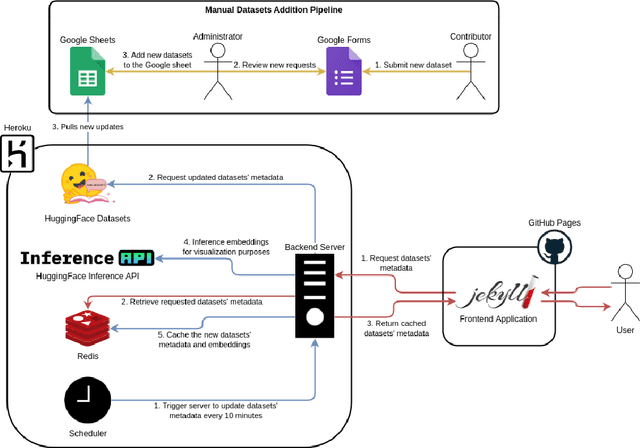
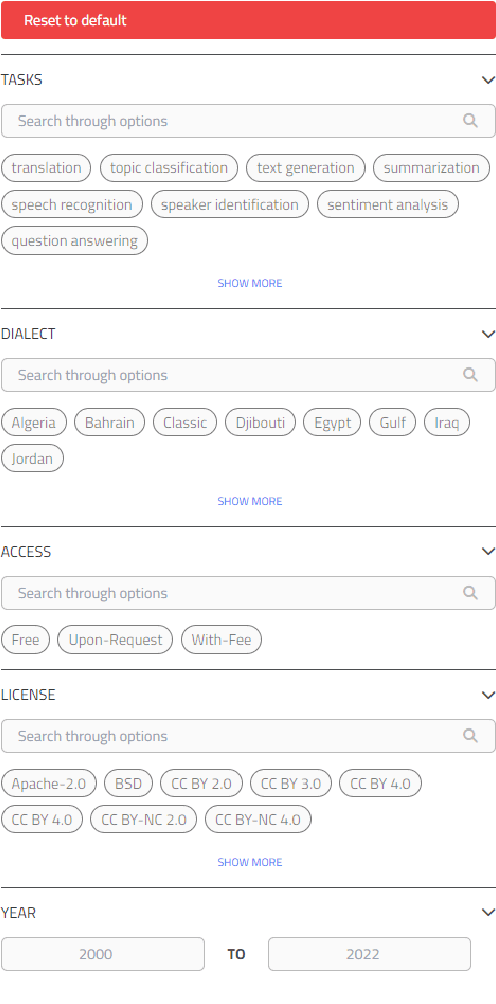
Masader (Alyafeai et al., 2021) created a metadata structure to be used for cataloguing Arabic NLP datasets. However, developing an easy way to explore such a catalogue is a challenging task. In order to give the optimal experience for users and researchers exploring the catalogue, several design and user experience challenges must be resolved. Furthermore, user interactions with the website may provide an easy approach to improve the catalogue. In this paper, we introduce Masader Plus, a web interface for users to browse Masader. We demonstrate data exploration, filtration, and a simple API that allows users to examine datasets from the backend. Masader Plus can be explored using this link https://arbml.github.io/masader. A video recording explaining the interface can be found here https://www.youtube.com/watch?v=SEtdlSeqchk.
Masader: Metadata Sourcing for Arabic Text and Speech Data Resources
Oct 13, 2021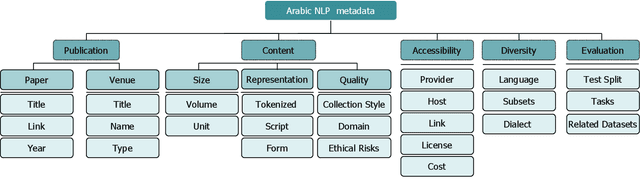
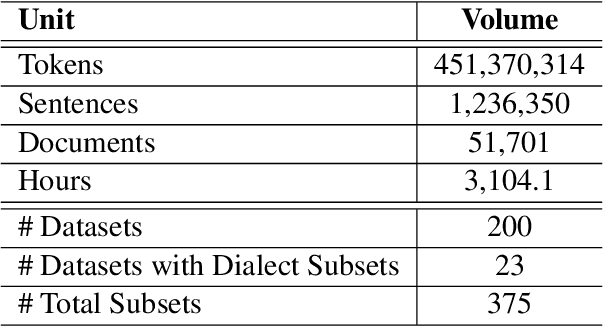
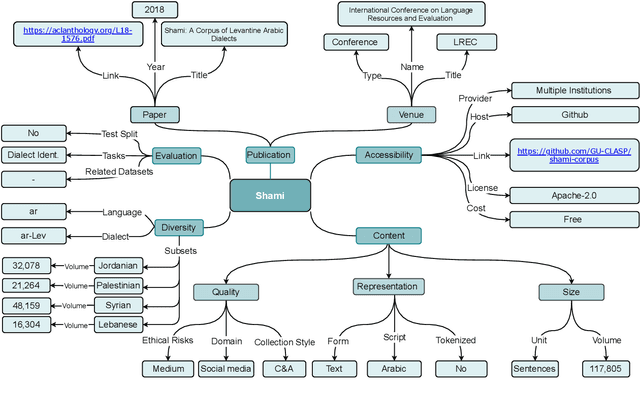
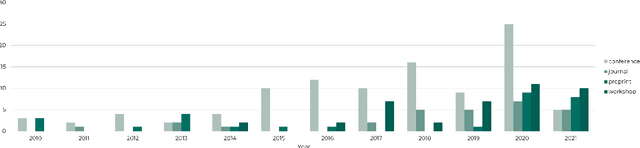
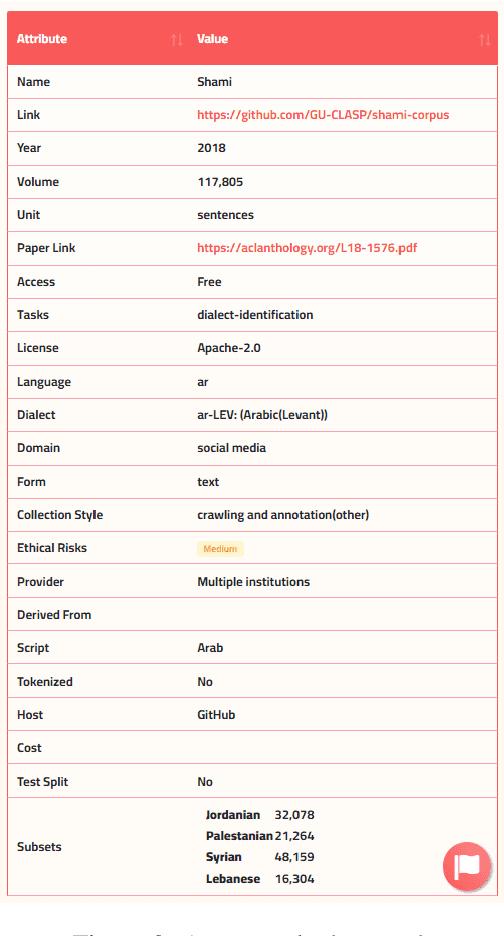
The NLP pipeline has evolved dramatically in the last few years. The first step in the pipeline is to find suitable annotated datasets to evaluate the tasks we are trying to solve. Unfortunately, most of the published datasets lack metadata annotations that describe their attributes. Not to mention, the absence of a public catalogue that indexes all the publicly available datasets related to specific regions or languages. When we consider low-resource dialectical languages, for example, this issue becomes more prominent. In this paper we create \textit{Masader}, the largest public catalogue for Arabic NLP datasets, which consists of 200 datasets annotated with 25 attributes. Furthermore, We develop a metadata annotation strategy that could be extended to other languages. We also make remarks and highlight some issues about the current status of Arabic NLP datasets and suggest recommendations to address them.
Calliar: An Online Handwritten Dataset for Arabic Calligraphy
Jun 25, 2021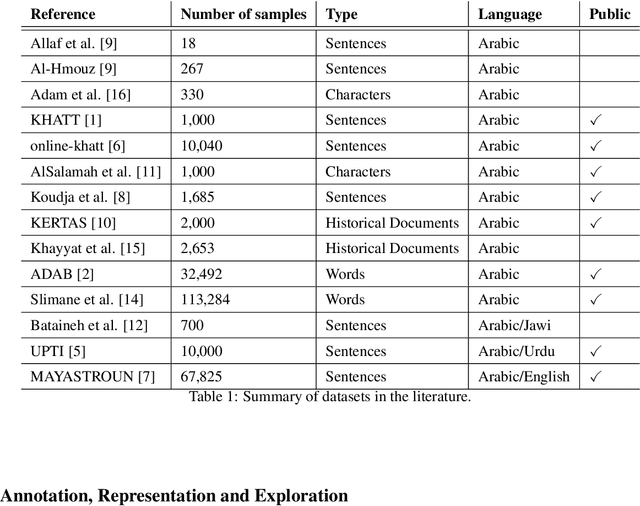


Calligraphy is an essential part of the Arabic heritage and culture. It has been used in the past for the decoration of houses and mosques. Usually, such calligraphy is designed manually by experts with aesthetic insights. In the past few years, there has been a considerable effort to digitize such type of art by either taking a photo of decorated buildings or drawing them using digital devices. The latter is considered an online form where the drawing is tracked by recording the apparatus movement, an electronic pen for instance, on a screen. In the literature, there are many offline datasets collected with a diversity of Arabic styles for calligraphy. However, there is no available online dataset for Arabic calligraphy. In this paper, we illustrate our approach for the collection and annotation of an online dataset for Arabic calligraphy called Calliar that consists of 2,500 sentences. Calliar is annotated for stroke, character, word and sentence level prediction.
Evaluating Various Tokenizers for Arabic Text Classification
Jun 14, 2021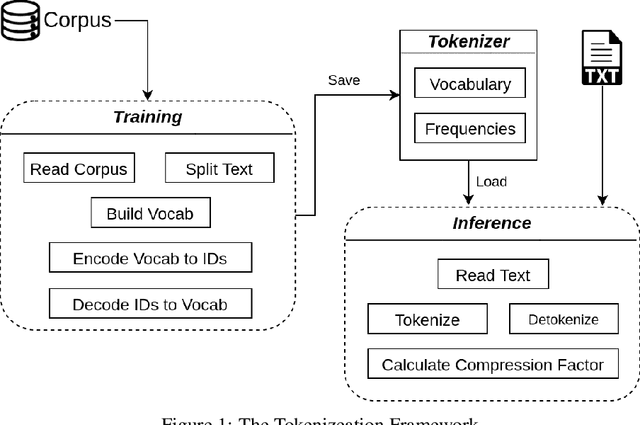

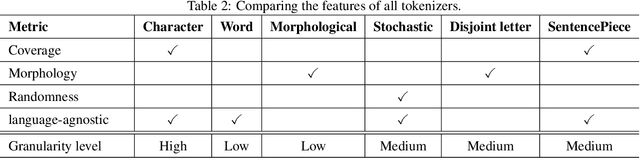
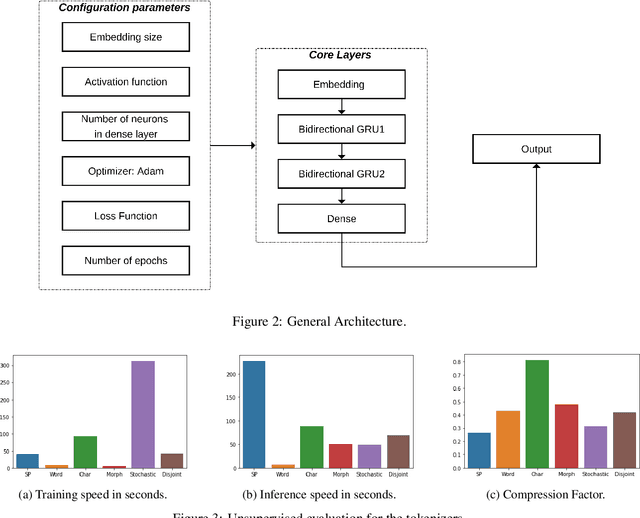
The first step in any NLP pipeline is learning word vector representations. However, given a large text corpus, representing all the words is not efficient. In the literature, many tokenization algorithms have emerged to tackle this problem by creating subwords which in turn limits the vocabulary size in any text corpus. However such algorithms are mostly language-agnostic and lack a proper way of capturing meaningful tokens. Not to mention the difficulty of evaluating such techniques in practice. In this paper, we introduce three new tokenization algorithms for Arabic and compare them to three other baselines using unsupervised evaluations. In addition to that, we compare all the six algorithms by evaluating them on three tasks which are sentiment analysis, news classification and poetry classification. Our experiments show that the performance of such tokenization algorithms depends on the size of the dataset, type of the task, and the amount of morphology that exists in the dataset.