 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Influence of Language on Sycophantic Behavior of Multilingual LLMs
Mar 29, 2026Large language models (LLMs) have achieved strong performance across a wide range of tasks, but they are also prone to sycophancy, the tendency to agree with user statements regardless of validity. Previous research has outlined both the extent and the underlying causes of sycophancy in earlier models, such as ChatGPT-3.5 and Davinci. Newer models have since undergone multiple mitigation strategies, yet there remains a critical need to systematically test their behavior. In particular, the effect of language on sycophancy has not been explored. In this work, we investigate how the language influences sycophantic responses. We evaluate three state-of-the-art models, GPT-4o mini, Gemini 1.5 Flash, and Claude 3.5 Haiku, using a set of tweet-like opinion prompts translated into five additional languages: Arabic, Chinese, French, Spanish, and Portuguese. Our results show that although newer models exhibit significantly less sycophancy overall compared to earlier generations, the extent of sycophancy is still influenced by the language. We further provide a granular analysis of how language shapes model agreeableness across sensitive topics, revealing systematic cultural and linguistic patterns. These findings highlight both the progress of mitigation efforts and the need for broader multilingual audits to ensure trustworthy and bias-aware deployment of LLMs.
Moral Sycophancy in Vision Language Models
Feb 09, 2026Sycophancy in Vision-Language Models (VLMs) refers to their tendency to align with user opinions, often at the expense of moral or factual accuracy. While prior studies have explored sycophantic behavior in general contexts, its impact on morally grounded visual decision-making remains insufficiently understood. To address this gap, we present the first systematic study of moral sycophancy in VLMs, analyzing ten widely-used models on the Moralise and M^3oralBench datasets under explicit user disagreement. Our results reveal that VLMs frequently produce morally incorrect follow-up responses even when their initial judgments are correct, and exhibit a consistent asymmetry: models are more likely to shift from morally right to morally wrong judgments than the reverse when exposed to user-induced bias. Follow-up prompts generally degrade performance on Moralise, while yielding mixed or even improved accuracy on M^3oralBench, highlighting dataset-dependent differences in moral robustness. Evaluation using Error Introduction Rate (EIR) and Error Correction Rate (ECR) reveals a clear trade-off: models with stronger error-correction capabilities tend to introduce more reasoning errors, whereas more conservative models minimize errors but exhibit limited ability to self-correct. Finally, initial contexts with a morally right stance elicit stronger sycophantic behavior, emphasizing the vulnerability of VLMs to moral influence and the need for principled strategies to improve ethical consistency and robustness in multimodal AI systems.
Automatic Classification of Arabic Literature into Historical Eras
Jan 22, 2026The Arabic language has undergone notable transformations over time, including the emergence of new vocabulary, the obsolescence of others, and shifts in word usage. This evolution is evident in the distinction between the classical and modern Arabic eras. Although historians and linguists have partitioned Arabic literature into multiple eras, relatively little research has explored the automatic classification of Arabic texts by time period, particularly beyond the domain of poetry. This paper addresses this gap by employing neural networks and deep learning techniques to automatically classify Arabic texts into distinct eras and periods. The proposed models are evaluated using two datasets derived from two publicly available corpora, covering texts from the pre-Islamic to the modern era. The study examines class setups ranging from binary to 15-class classification and considers both predefined historical eras and custom periodizations. Results range from F1-scores of 0.83 and 0.79 on the binary-era classification task using the OpenITI and APCD datasets, respectively, to 0.20 on the 15-era classification task using OpenITI and 0.18 on the 12-era classification task using APCD.
PENDULUM: A Benchmark for Assessing Sycophancy in Multimodal Large Language Models
Dec 22, 2025Sycophancy, an excessive tendency of AI models to agree with user input at the expense of factual accuracy or in contradiction of visual evidence, poses a critical and underexplored challenge for multimodal large language models (MLLMs). While prior studies have examined this behavior in text-only settings of large language models, existing research on visual or multimodal counterparts remains limited in scope and depth of analysis. To address this gap, we introduce a comprehensive evaluation benchmark, \textit{PENDULUM}, comprising approximately 2,000 human-curated Visual Question Answering pairs specifically designed to elicit sycophantic responses. The benchmark spans six distinct image domains of varying complexity, enabling a systematic investigation of how image type and inherent challenges influence sycophantic tendencies. Through extensive evaluation of state-of-the-art MLLMs. we observe substantial variability in model robustness and a pronounced susceptibility to sycophantic and hallucinatory behavior. Furthermore, we propose novel metrics to quantify sycophancy in visual reasoning, offering deeper insights into its manifestations across different multimodal contexts. Our findings highlight the urgent need for developing sycophancy-resilient architectures and training strategies to enhance factual consistency and reliability in future MLLMs. Our proposed dataset with MLLMs response are available at https://github.com/ashikiut/pendulum/.
Poem Meter Classification of Recited Arabic Poetry: Integrating High-Resource Systems for a Low-Resource Task
Apr 16, 2025Arabic poetry is an essential and integral part of Arabic language and culture. It has been used by the Arabs to spot lights on their major events such as depicting brutal battles and conflicts. They also used it, as in many other languages, for various purposes such as romance, pride, lamentation, etc. Arabic poetry has received major attention from linguistics over the decades. One of the main characteristics of Arabic poetry is its special rhythmic structure as opposed to prose. This structure is referred to as a meter. Meters, along with other poetic characteristics, are intensively studied in an Arabic linguistic field called "\textit{Aroud}". Identifying these meters for a verse is a lengthy and complicated process. It also requires technical knowledge in \textit{Aruod}. For recited poetry, it adds an extra layer of processing. Developing systems for automatic identification of poem meters for recited poems need large amounts of labelled data. In this study, we propose a state-of-the-art framework to identify the poem meters of recited Arabic poetry, where we integrate two separate high-resource systems to perform the low-resource task. To ensure generalization of our proposed architecture, we publish a benchmark for this task for future research.
Dotless Representation of Arabic Text: Analysis and Modeling
Dec 26, 2023This paper presents a novel dotless representation of Arabic text as an alternative to the standard Arabic text representation. We delve into its implications through comprehensive analysis across five diverse corpora and four different tokenization techniques. We explore the impact of dotless representation on the relationships between tokenization granularity and vocabulary size and compare them with standard text representation. Moreover, we analyze the information density of dotless versus standard text using text entropy calculations. To delve deeper into the implications of the dotless representation, statistical and neural language models are constructed using the various text corpora and tokenization techniques. A comparative assessment is then made against language models developed using the standard Arabic text representation. This multifaceted analysis provides valuable insights into the potential advantages and challenges associated with the dotless representation. Last but not the least, utilizing parallel corpora, we draw comparisons between the text analysis of Arabic and English to gain further insights. Our findings shed light on the potential benefits of dotless representation for various NLP tasks, paving the way for further exploration for Arabic natural language processing.
FxP-QNet: A Post-Training Quantizer for the Design of Mixed Low-Precision DNNs with Dynamic Fixed-Point Representation
Mar 22, 2022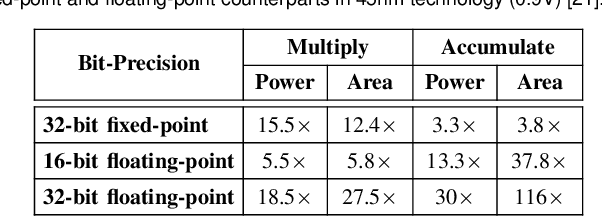

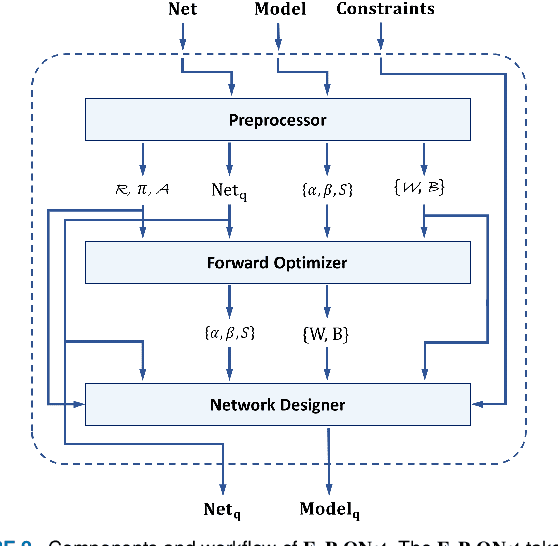
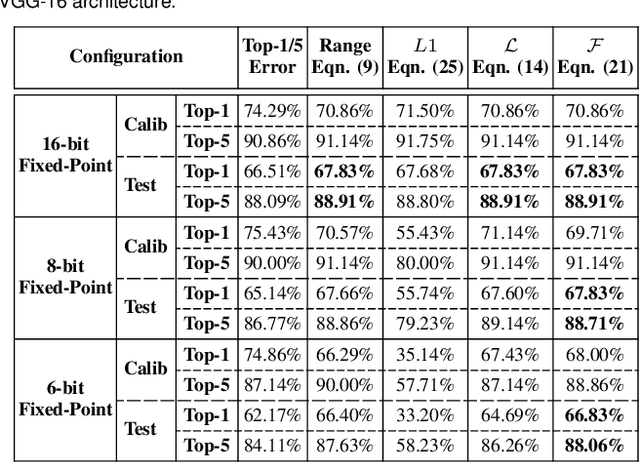
Deep neural networks (DNNs) have demonstrated their effectiveness in a wide range of computer vision tasks, with the state-of-the-art results obtained through complex and deep structures that require intensive computation and memory. Now-a-days, efficient model inference is crucial for consumer applications on resource-constrained platforms. As a result, there is much interest in the research and development of dedicated deep learning (DL) hardware to improve the throughput and energy efficiency of DNNs. Low-precision representation of DNN data-structures through quantization would bring great benefits to specialized DL hardware. However, the rigorous quantization leads to a severe accuracy drop. As such, quantization opens a large hyper-parameter space at bit-precision levels, the exploration of which is a major challenge. In this paper, we propose a novel framework referred to as the Fixed-Point Quantizer of deep neural Networks (FxP-QNet) that flexibly designs a mixed low-precision DNN for integer-arithmetic-only deployment. Specifically, the FxP-QNet gradually adapts the quantization level for each data-structure of each layer based on the trade-off between the network accuracy and the low-precision requirements. Additionally, it employs post-training self-distillation and network prediction error statistics to optimize the quantization of floating-point values into fixed-point numbers. Examining FxP-QNet on state-of-the-art architectures and the benchmark ImageNet dataset, we empirically demonstrate the effectiveness of FxP-QNet in achieving the accuracy-compression trade-off without the need for training. The results show that FxP-QNet-quantized AlexNet, VGG-16, and ResNet-18 reduce the overall memory requirements of their full-precision counterparts by 7.16x, 10.36x, and 6.44x with less than 0.95%, 0.95%, and 1.99% accuracy drop, respectively.
Evaluating Various Tokenizers for Arabic Text Classification
Jun 14, 2021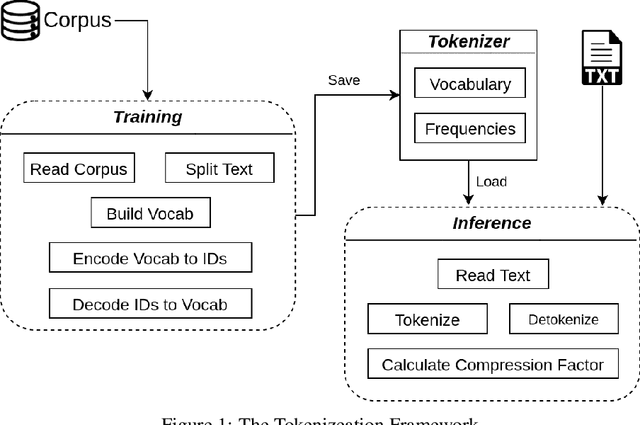

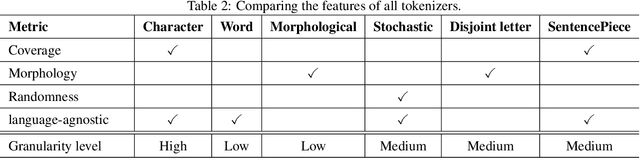
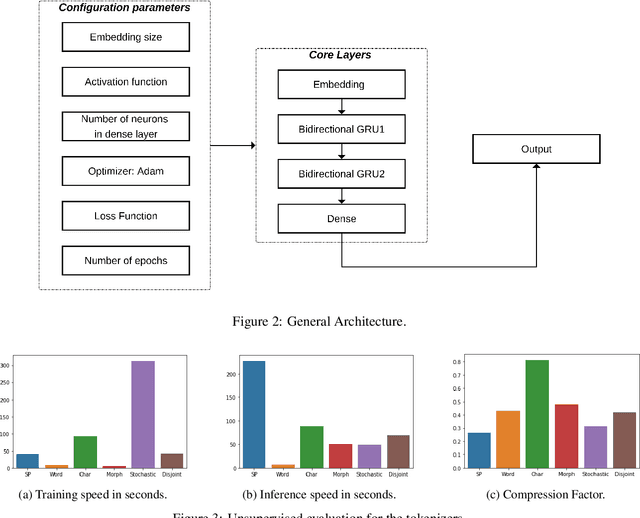
The first step in any NLP pipeline is learning word vector representations. However, given a large text corpus, representing all the words is not efficient. In the literature, many tokenization algorithms have emerged to tackle this problem by creating subwords which in turn limits the vocabulary size in any text corpus. However such algorithms are mostly language-agnostic and lack a proper way of capturing meaningful tokens. Not to mention the difficulty of evaluating such techniques in practice. In this paper, we introduce three new tokenization algorithms for Arabic and compare them to three other baselines using unsupervised evaluations. In addition to that, we compare all the six algorithms by evaluating them on three tasks which are sentiment analysis, news classification and poetry classification. Our experiments show that the performance of such tokenization algorithms depends on the size of the dataset, type of the task, and the amount of morphology that exists in the dataset.
Knowledge Distillation in Deep Learning and its Applications
Jul 17, 2020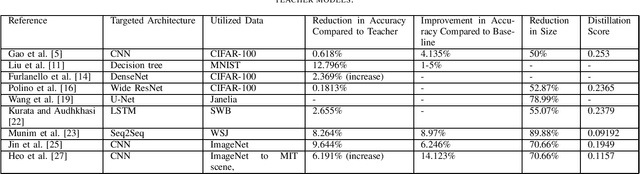
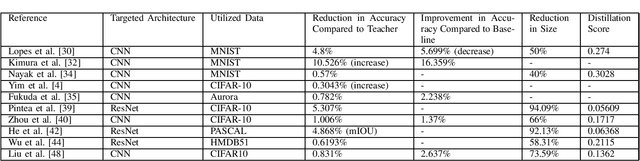
Deep learning based models are relatively large, and it is hard to deploy such models on resource-limited devices such as mobile phones and embedded devices. One possible solution is knowledge distillation whereby a smaller model (student model) is trained by utilizing the information from a larger model (teacher model). In this paper, we present a survey of knowledge distillation techniques applied to deep learning models. To compare the performances of different techniques, we propose a new metric called distillation metric. Distillation metric compares different knowledge distillation algorithms based on sizes and accuracy scores. Based on the survey, some interesting conclusions are drawn and presented in this paper.