 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeXtract: Light-Weight Metadata Extraction from Scientific Papers
Oct 08, 2025Metadata plays a critical role in indexing, documenting, and analyzing scientific literature, yet extracting it accurately and efficiently remains a challenging task. Traditional approaches often rely on rule-based or task-specific models, which struggle to generalize across domains and schema variations. In this paper, we present MeXtract, a family of lightweight language models designed for metadata extraction from scientific papers. The models, ranging from 0.5B to 3B parameters, are built by fine-tuning Qwen 2.5 counterparts. In their size family, MeXtract achieves state-of-the-art performance on metadata extraction on the MOLE benchmark. To further support evaluation, we extend the MOLE benchmark to incorporate model-specific metadata, providing an out-of-domain challenging subset. Our experiments show that fine-tuning on a given schema not only yields high accuracy but also transfers effectively to unseen schemas, demonstrating the robustness and adaptability of our approach. We release all the code, datasets, and models openly for the research community.
The Arabic AI Fingerprint: Stylometric Analysis and Detection of Large Language Models Text
May 29, 2025Large Language Models (LLMs) have achieved unprecedented capabilities in generating human-like text, posing subtle yet significant challenges for information integrity across critical domains, including education, social media, and academia, enabling sophisticated misinformation campaigns, compromising healthcare guidance, and facilitating targeted propaganda. This challenge becomes severe, particularly in under-explored and low-resource languages like Arabic. This paper presents a comprehensive investigation of Arabic machine-generated text, examining multiple generation strategies (generation from the title only, content-aware generation, and text refinement) across diverse model architectures (ALLaM, Jais, Llama, and GPT-4) in academic, and social media domains. Our stylometric analysis reveals distinctive linguistic patterns differentiating human-written from machine-generated Arabic text across these varied contexts. Despite their human-like qualities, we demonstrate that LLMs produce detectable signatures in their Arabic outputs, with domain-specific characteristics that vary significantly between different contexts. Based on these insights, we developed BERT-based detection models that achieved exceptional performance in formal contexts (up to 99.9\% F1-score) with strong precision across model architectures. Our cross-domain analysis confirms generalization challenges previously reported in the literature. To the best of our knowledge, this work represents the most comprehensive investigation of Arabic machine-generated text to date, uniquely combining multiple prompt generation methods, diverse model architectures, and in-depth stylometric analysis across varied textual domains, establishing a foundation for developing robust, linguistically-informed detection systems essential for preserving information integrity in Arabic-language contexts.
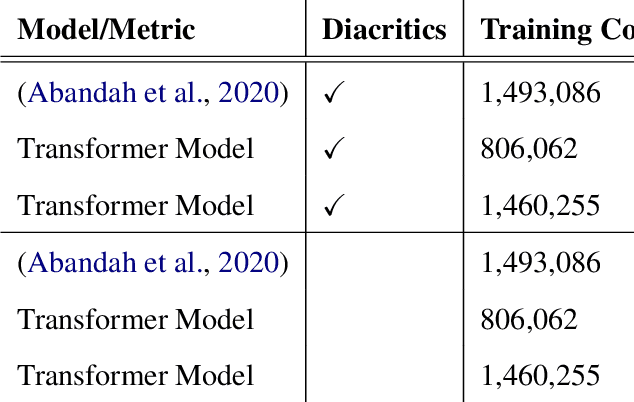
MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs
May 26, 2025Metadata extraction is essential for cataloging and preserving datasets, enabling effective research discovery and reproducibility, especially given the current exponential growth in scientific research. While Masader (Alyafeai et al.,2021) laid the groundwork for extracting a wide range of metadata attributes from Arabic NLP datasets' scholarly articles, it relies heavily on manual annotation. In this paper, we present MOLE, a framework that leverages Large Language Models (LLMs) to automatically extract metadata attributes from scientific papers covering datasets of languages other than Arabic. Our schema-driven methodology processes entire documents across multiple input formats and incorporates robust validation mechanisms for consistent output. Additionally, we introduce a new benchmark to evaluate the research progress on this task. Through systematic analysis of context length, few-shot learning, and web browsing integration, we demonstrate that modern LLMs show promising results in automating this task, highlighting the need for further future work improvements to ensure consistent and reliable performance. We release the code: https://github.com/IVUL-KAUST/MOLE and dataset: https://huggingface.co/datasets/IVUL-KAUST/MOLE for the research community.
Poem Meter Classification of Recited Arabic Poetry: Integrating High-Resource Systems for a Low-Resource Task
Apr 16, 2025Arabic poetry is an essential and integral part of Arabic language and culture. It has been used by the Arabs to spot lights on their major events such as depicting brutal battles and conflicts. They also used it, as in many other languages, for various purposes such as romance, pride, lamentation, etc. Arabic poetry has received major attention from linguistics over the decades. One of the main characteristics of Arabic poetry is its special rhythmic structure as opposed to prose. This structure is referred to as a meter. Meters, along with other poetic characteristics, are intensively studied in an Arabic linguistic field called "\textit{Aroud}". Identifying these meters for a verse is a lengthy and complicated process. It also requires technical knowledge in \textit{Aruod}. For recited poetry, it adds an extra layer of processing. Developing systems for automatic identification of poem meters for recited poems need large amounts of labelled data. In this study, we propose a state-of-the-art framework to identify the poem meters of recited Arabic poetry, where we integrate two separate high-resource systems to perform the low-resource task. To ensure generalization of our proposed architecture, we publish a benchmark for this task for future research.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
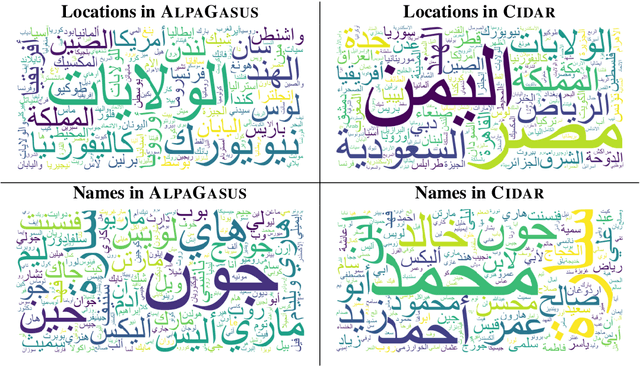
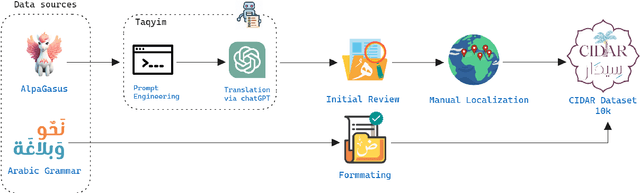

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
Dotless Representation of Arabic Text: Analysis and Modeling
Dec 26, 2023This paper presents a novel dotless representation of Arabic text as an alternative to the standard Arabic text representation. We delve into its implications through comprehensive analysis across five diverse corpora and four different tokenization techniques. We explore the impact of dotless representation on the relationships between tokenization granularity and vocabulary size and compare them with standard text representation. Moreover, we analyze the information density of dotless versus standard text using text entropy calculations. To delve deeper into the implications of the dotless representation, statistical and neural language models are constructed using the various text corpora and tokenization techniques. A comparative assessment is then made against language models developed using the standard Arabic text representation. This multifaceted analysis provides valuable insights into the potential advantages and challenges associated with the dotless representation. Last but not the least, utilizing parallel corpora, we draw comparisons between the text analysis of Arabic and English to gain further insights. Our findings shed light on the potential benefits of dotless representation for various NLP tasks, paving the way for further exploration for Arabic natural language processing.
Ashaar: Automatic Analysis and Generation of Arabic Poetry Using Deep Learning Approaches
Jul 12, 2023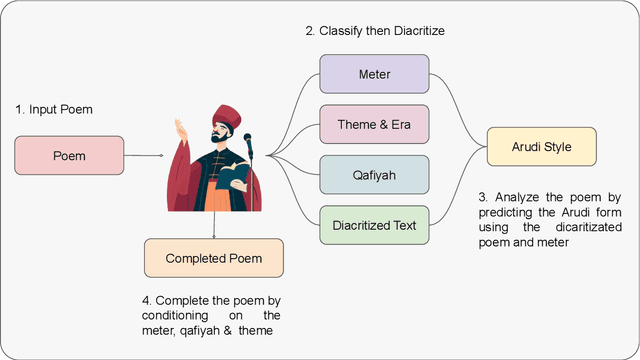
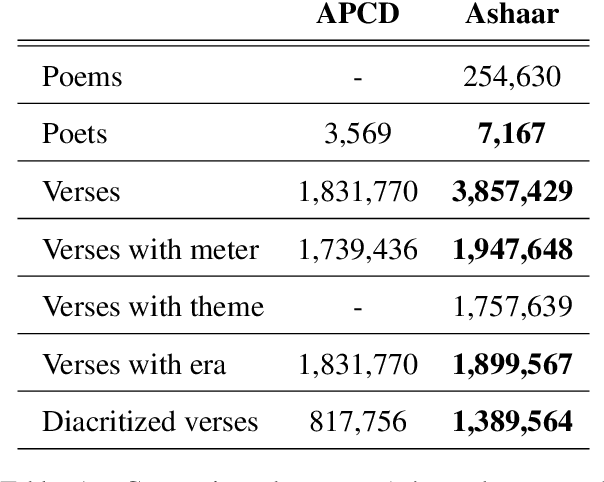
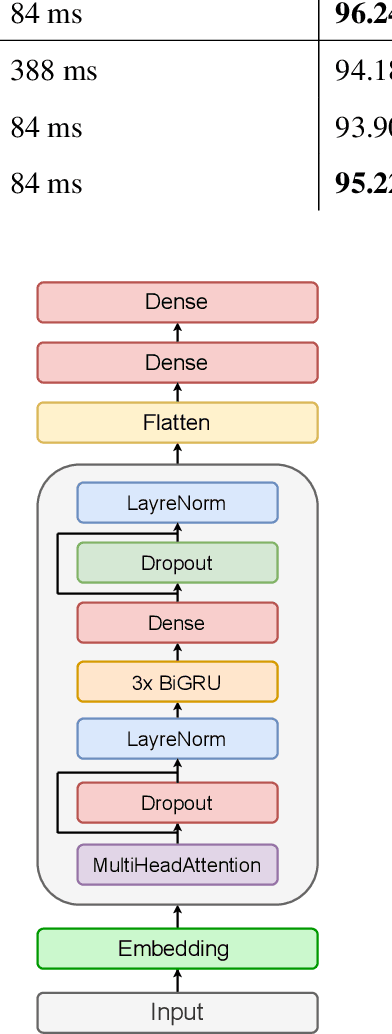
Poetry holds immense significance within the cultural and traditional fabric of any nation. It serves as a vehicle for poets to articulate their emotions, preserve customs, and convey the essence of their culture. Arabic poetry is no exception, having played a cherished role in the heritage of the Arabic community throughout history and maintaining its relevance in the present era. Typically, comprehending Arabic poetry necessitates the expertise of a linguist who can analyze its content and assess its quality. This paper presents the introduction of a framework called \textit{Ashaar} https://github.com/ARBML/Ashaar, which encompasses a collection of datasets and pre-trained models designed specifically for the analysis and generation of Arabic poetry. The pipeline established within our proposed approach encompasses various aspects of poetry, such as meter, theme, and era classification. It also incorporates automatic poetry diacritization, enabling more intricate analyses like automated extraction of the \textit{Arudi} style. Additionally, we explore the feasibility of generating conditional poetry through the pre-training of a character-based GPT model. Furthermore, as part of this endeavor, we provide four datasets: one for poetry generation, another for diacritization, and two for Arudi-style prediction. These datasets aim to facilitate research and development in the field of Arabic poetry by enabling researchers and enthusiasts to delve into the nuances of this rich literary tradition.
A Bibliography of Multiple Sclerosis Lesions Detection Methods using Brain MRIs
Feb 19, 2023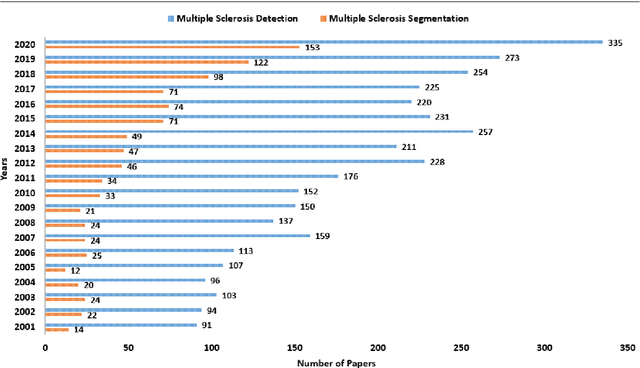

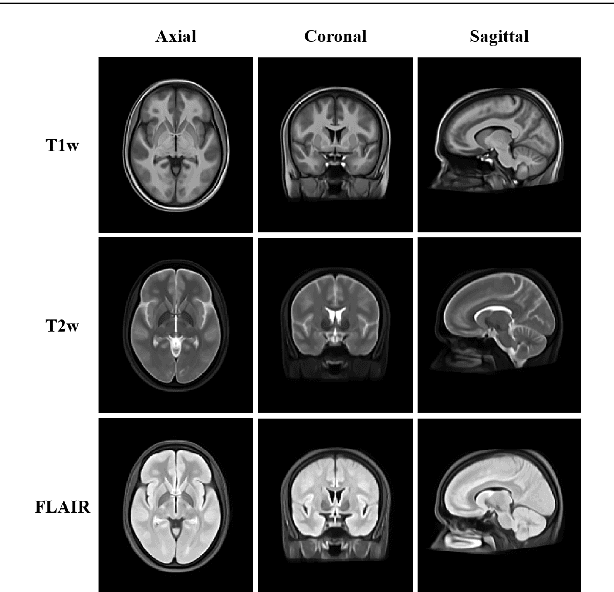

Introduction: Multiple Sclerosis (MS) is a chronic disease that affects millions of people across the globe. MS can critically affect different organs of the central nervous system such as the eyes, the spinal cord, and the brain. Background: To help physicians in diagnosing MS lesions, computer-aided methods are widely used. In this regard, a considerable research has been carried out in the area of automatic detection and segmentation of MS lesions in magnetic resonance images (MRIs). Methodology: In this study, we review the different approaches that have been used in computer-aided detection and segmentation of MS lesions. Our review resulted in categorizing MS lesion segmentation approaches into six broad categories: data-driven, statistical, supervised machine learning, unsupervised machine learning, fuzzy, and deep learning-based techniques. We critically analyze the different techniques under these approaches and highlight their strengths and weaknesses. Results: From the study, we observe that a considerable amount of work, around 25% of related literature, is focused on statistical-based MS lesion segmentation techniques, followed by 21.15% for data-driven based methods, 19.23% for deep learning and 15.38% for supervised methods. Implication: The study points out the challenges/gaps to be addressed in future research. The study shows the work which has been done in last one decade in detection and segmentation of MS lesions. The results show that, in recent years, deep learning methods are outperforming all the others methods.