 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Courier Scheduling in Crowdsourced Last-Mile Delivery through Dynamic Shift Extensions: A Deep Reinforcement Learning Approach
Feb 15, 2024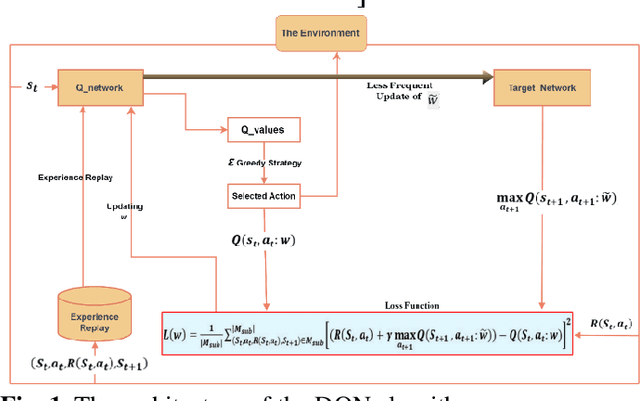
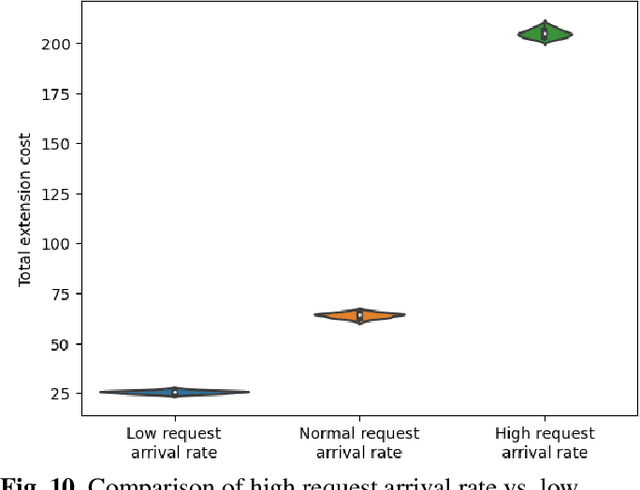
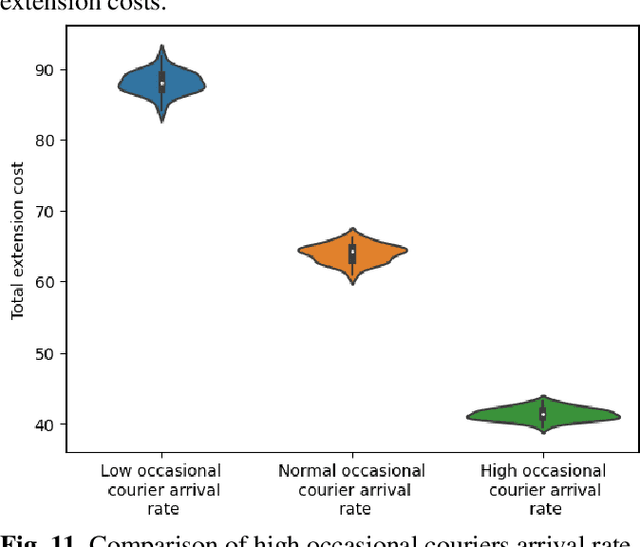
Crowdsourced delivery platforms face complex scheduling challenges to match couriers and customer orders. We consider two types of crowdsourced couriers, namely, committed and occasional couriers, each with different compensation schemes. Crowdsourced delivery platforms usually schedule committed courier shifts based on predicted demand. Therefore, platforms may devise an offline schedule for committed couriers before the planning period. However, due to the unpredictability of demand, there are instances where it becomes necessary to make online adjustments to the offline schedule. In this study, we focus on the problem of dynamically adjusting the offline schedule through shift extensions for committed couriers. This problem is modeled as a sequential decision process. The objective is to maximize platform profit by determining the shift extensions of couriers and the assignments of requests to couriers. To solve the model, a Deep Q-Network (DQN) learning approach is developed. Comparing this model with the baseline policy where no extensions are allowed demonstrates the benefits that platforms can gain from allowing shift extensions in terms of reward, reduced lost order costs, and lost requests. Additionally, sensitivity analysis showed that the total extension compensation increases in a nonlinear manner with the arrival rate of requests, and in a linear manner with the arrival rate of occasional couriers. On the compensation sensitivity, the results showed that the normal scenario exhibited the highest average number of shift extensions and, consequently, the fewest average number of lost requests. These findings serve as evidence of the successful learning of such dynamics by the DQN algorithm.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
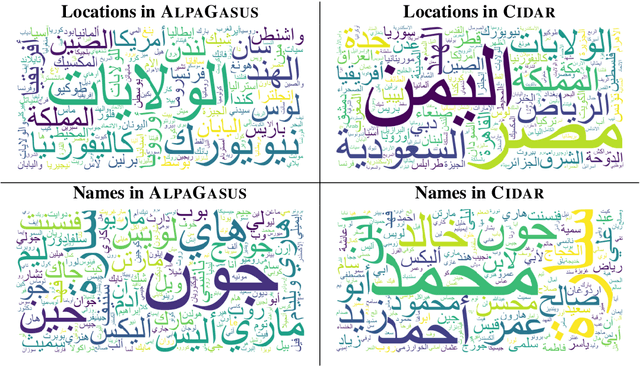
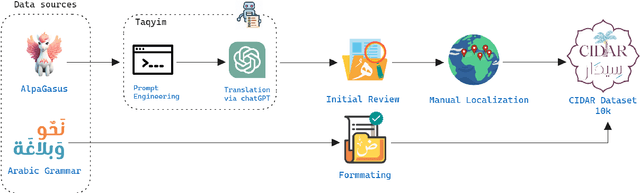

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.