 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Training for Cultural Awareness: The Role of Dataset Linguistic Structure in Large Language Models
Feb 01, 2026The global deployment of large language models (LLMs) has raised concerns about cultural misalignment, yet the linguistic properties of fine-tuning datasets used for cultural adaptation remain poorly understood. We adopt a dataset-centric view of cultural alignment and ask which linguistic properties of fine-tuning data are associated with cultural performance, whether these properties are predictive prior to training, and how these effects vary across models. We compute lightweight linguistic, semantic, and structural metrics for Arabic, Chinese, and Japanese datasets and apply principal component analysis separately within each language. This design ensures that the resulting components capture variation among datasets written in the same language rather than differences between languages. The resulting components correspond to broadly interpretable axes related to semantic coherence, surface-level lexical and syntactic diversity, and lexical or structural richness, though their composition varies across languages. We fine-tune three major LLM families (LLaMA, Mistral, DeepSeek) and evaluate them on benchmarks of cultural knowledge, values, and norms. While PCA components correlate with downstream performance, these associations are strongly model-dependent. Through controlled subset interventions, we show that lexical-oriented components (PC3) are the most robust, yielding more consistent performance across models and benchmarks, whereas emphasizing semantic or diversity extremes (PC1-PC2) is often neutral or harmful.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025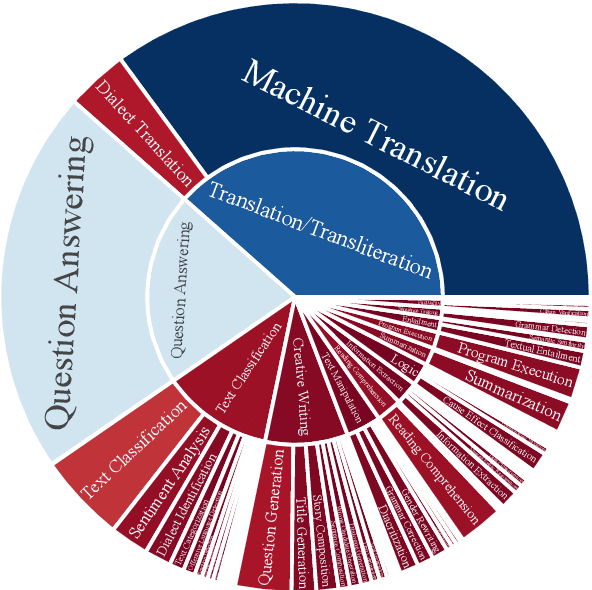



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Leveraging Corpus Metadata to Detect Template-based Translation: An Exploratory Case Study of the Egyptian Arabic Wikipedia Edition
Mar 31, 2024Wikipedia articles (content pages) are commonly used corpora in Natural Language Processing (NLP) research, especially in low-resource languages other than English. Yet, a few research studies have studied the three Arabic Wikipedia editions, Arabic Wikipedia (AR), Egyptian Arabic Wikipedia (ARZ), and Moroccan Arabic Wikipedia (ARY), and documented issues in the Egyptian Arabic Wikipedia edition regarding the massive automatic creation of its articles using template-based translation from English to Arabic without human involvement, overwhelming the Egyptian Arabic Wikipedia with articles that do not only have low-quality content but also with articles that do not represent the Egyptian people, their culture, and their dialect. In this paper, we aim to mitigate the problem of template translation that occurred in the Egyptian Arabic Wikipedia by identifying these template-translated articles and their characteristics through exploratory analysis and building automatic detection systems. We first explore the content of the three Arabic Wikipedia editions in terms of density, quality, and human contributions and utilize the resulting insights to build multivariate machine learning classifiers leveraging articles' metadata to detect the template-translated articles automatically. We then publicly deploy and host the best-performing classifier, XGBoost, as an online application called EGYPTIAN WIKIPEDIA SCANNER and release the extracted, filtered, and labeled datasets to the research community to benefit from our datasets and the online, web-based detection system.
Arabic Synonym BERT-based Adversarial Examples for Text Classification
Feb 05, 2024Text classification systems have been proven vulnerable to adversarial text examples, modified versions of the original text examples that are often unnoticed by human eyes, yet can force text classification models to alter their classification. Often, research works quantifying the impact of adversarial text attacks have been applied only to models trained in English. In this paper, we introduce the first word-level study of adversarial attacks in Arabic. Specifically, we use a synonym (word-level) attack using a Masked Language Modeling (MLM) task with a BERT model in a black-box setting to assess the robustness of the state-of-the-art text classification models to adversarial attacks in Arabic. To evaluate the grammatical and semantic similarities of the newly produced adversarial examples using our synonym BERT-based attack, we invite four human evaluators to assess and compare the produced adversarial examples with their original examples. We also study the transferability of these newly produced Arabic adversarial examples to various models and investigate the effectiveness of defense mechanisms against these adversarial examples on the BERT models. We find that fine-tuned BERT models were more susceptible to our synonym attacks than the other Deep Neural Networks (DNN) models like WordCNN and WordLSTM we trained. We also find that fine-tuned BERT models were more susceptible to transferred attacks. We, lastly, find that fine-tuned BERT models successfully regain at least 2% in accuracy after applying adversarial training as an initial defense mechanism.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024
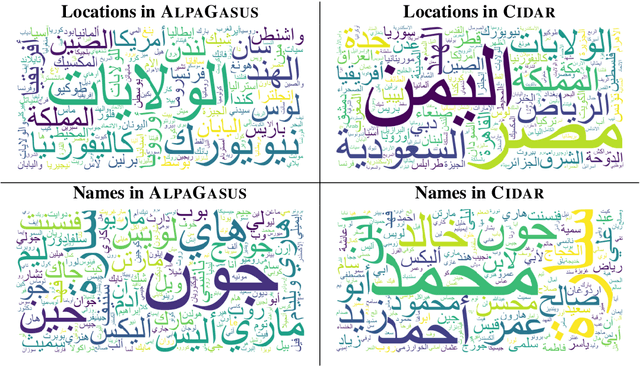
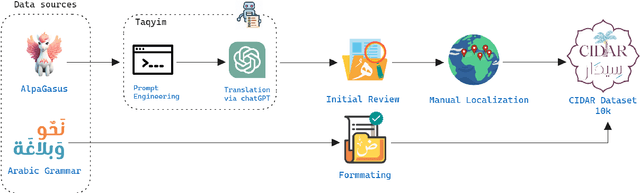

Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.