 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Synonym BERT-based Adversarial Examples for Text Classification
Feb 05, 2024Text classification systems have been proven vulnerable to adversarial text examples, modified versions of the original text examples that are often unnoticed by human eyes, yet can force text classification models to alter their classification. Often, research works quantifying the impact of adversarial text attacks have been applied only to models trained in English. In this paper, we introduce the first word-level study of adversarial attacks in Arabic. Specifically, we use a synonym (word-level) attack using a Masked Language Modeling (MLM) task with a BERT model in a black-box setting to assess the robustness of the state-of-the-art text classification models to adversarial attacks in Arabic. To evaluate the grammatical and semantic similarities of the newly produced adversarial examples using our synonym BERT-based attack, we invite four human evaluators to assess and compare the produced adversarial examples with their original examples. We also study the transferability of these newly produced Arabic adversarial examples to various models and investigate the effectiveness of defense mechanisms against these adversarial examples on the BERT models. We find that fine-tuned BERT models were more susceptible to our synonym attacks than the other Deep Neural Networks (DNN) models like WordCNN and WordLSTM we trained. We also find that fine-tuned BERT models were more susceptible to transferred attacks. We, lastly, find that fine-tuned BERT models successfully regain at least 2% in accuracy after applying adversarial training as an initial defense mechanism.
Is Machine Learning Speaking my Language? A Critical Look at the NLP-Pipeline Across 8 Human Languages
Jul 11, 2020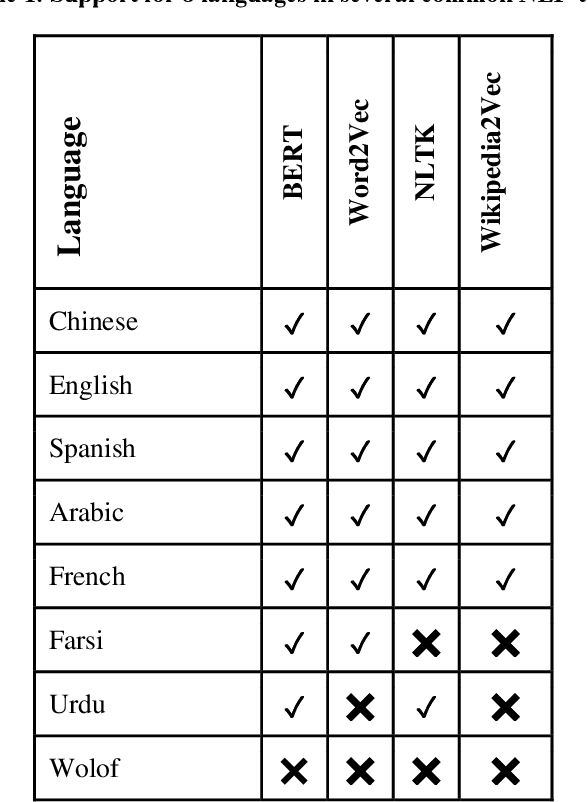
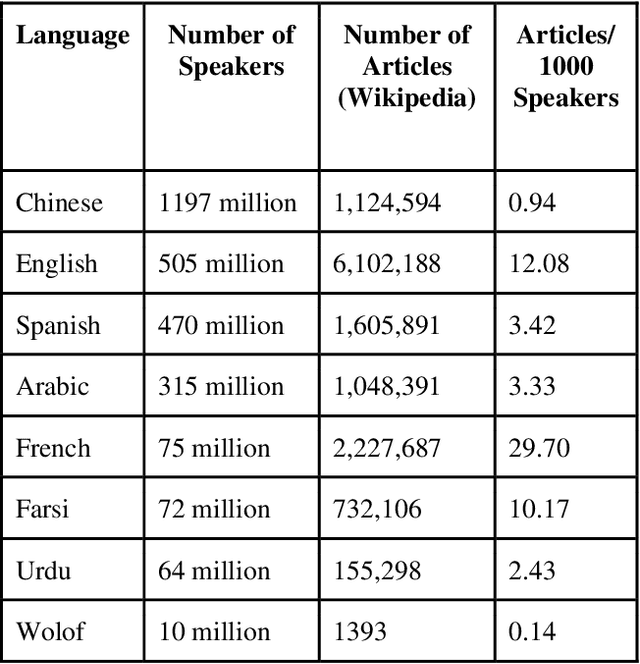
Natural Language Processing (NLP) is increasingly used as a key ingredient in critical decision-making systems such as resume parsers used in sorting a list of job candidates. NLP systems often ingest large corpora of human text, attempting to learn from past human behavior and decisions in order to produce systems that will make recommendations about our future world. Over 7000 human languages are being spoken today and the typical NLP pipeline underrepresents speakers of most of them while amplifying the voices of speakers of other languages. In this paper, a team including speakers of 8 languages - English, Chinese, Urdu, Farsi, Arabic, French, Spanish, and Wolof - takes a critical look at the typical NLP pipeline and how even when a language is technically supported, substantial caveats remain to prevent full participation. Despite huge and admirable investments in multilingual support in many tools and resources, we are still making NLP-guided decisions that systematically and dramatically underrepresent the voices of much of the world.