 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Corpus Metadata to Detect Template-based Translation: An Exploratory Case Study of the Egyptian Arabic Wikipedia Edition
Mar 31, 2024Wikipedia articles (content pages) are commonly used corpora in Natural Language Processing (NLP) research, especially in low-resource languages other than English. Yet, a few research studies have studied the three Arabic Wikipedia editions, Arabic Wikipedia (AR), Egyptian Arabic Wikipedia (ARZ), and Moroccan Arabic Wikipedia (ARY), and documented issues in the Egyptian Arabic Wikipedia edition regarding the massive automatic creation of its articles using template-based translation from English to Arabic without human involvement, overwhelming the Egyptian Arabic Wikipedia with articles that do not only have low-quality content but also with articles that do not represent the Egyptian people, their culture, and their dialect. In this paper, we aim to mitigate the problem of template translation that occurred in the Egyptian Arabic Wikipedia by identifying these template-translated articles and their characteristics through exploratory analysis and building automatic detection systems. We first explore the content of the three Arabic Wikipedia editions in terms of density, quality, and human contributions and utilize the resulting insights to build multivariate machine learning classifiers leveraging articles' metadata to detect the template-translated articles automatically. We then publicly deploy and host the best-performing classifier, XGBoost, as an online application called EGYPTIAN WIKIPEDIA SCANNER and release the extracted, filtered, and labeled datasets to the research community to benefit from our datasets and the online, web-based detection system.
Is Machine Learning Speaking my Language? A Critical Look at the NLP-Pipeline Across 8 Human Languages
Jul 11, 2020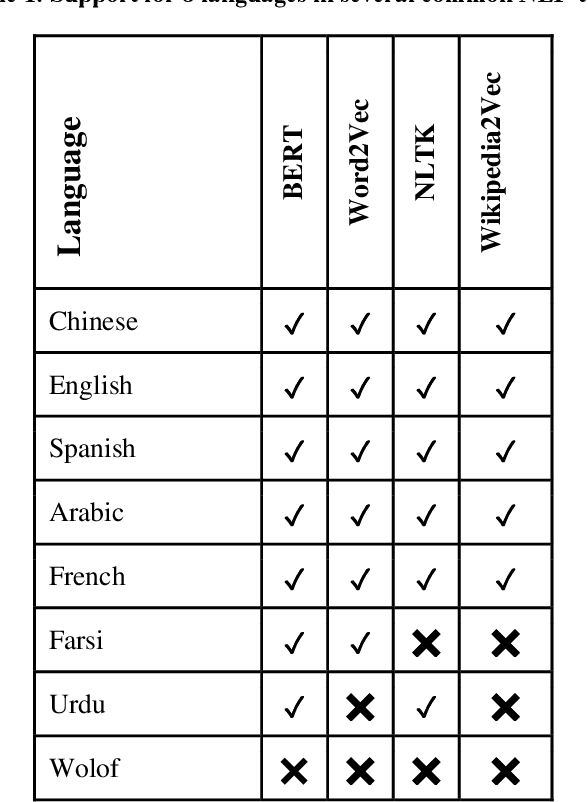
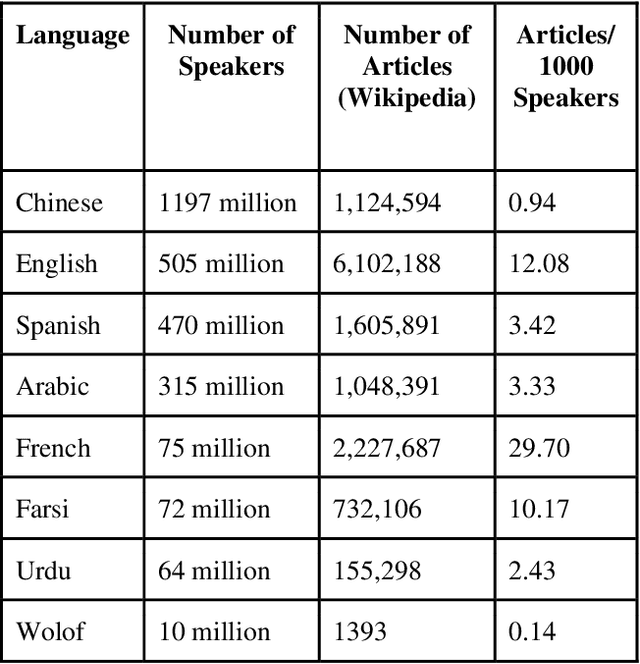
Natural Language Processing (NLP) is increasingly used as a key ingredient in critical decision-making systems such as resume parsers used in sorting a list of job candidates. NLP systems often ingest large corpora of human text, attempting to learn from past human behavior and decisions in order to produce systems that will make recommendations about our future world. Over 7000 human languages are being spoken today and the typical NLP pipeline underrepresents speakers of most of them while amplifying the voices of speakers of other languages. In this paper, a team including speakers of 8 languages - English, Chinese, Urdu, Farsi, Arabic, French, Spanish, and Wolof - takes a critical look at the typical NLP pipeline and how even when a language is technically supported, substantial caveats remain to prevent full participation. Despite huge and admirable investments in multilingual support in many tools and resources, we are still making NLP-guided decisions that systematically and dramatically underrepresent the voices of much of the world.