 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItem Recommendation Using User Feedback Data and Item Profile
Jun 28, 2022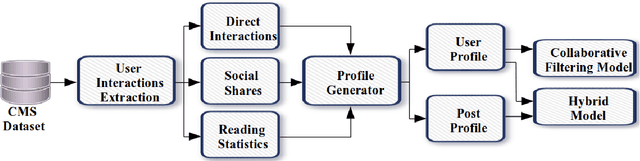
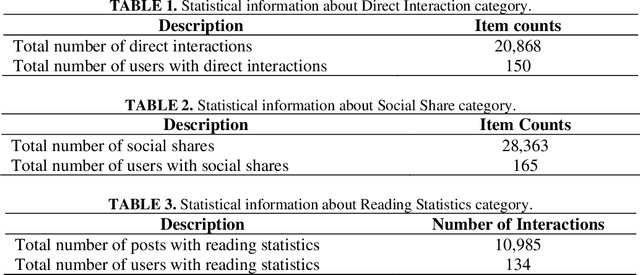
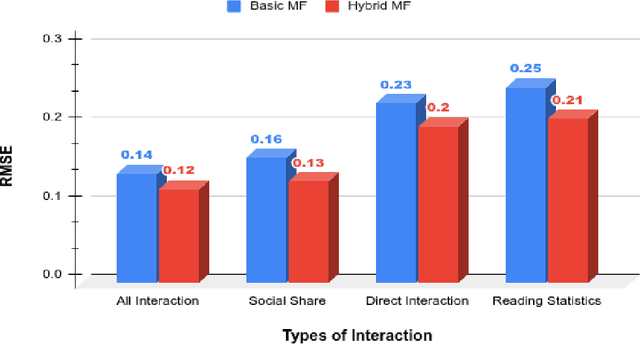
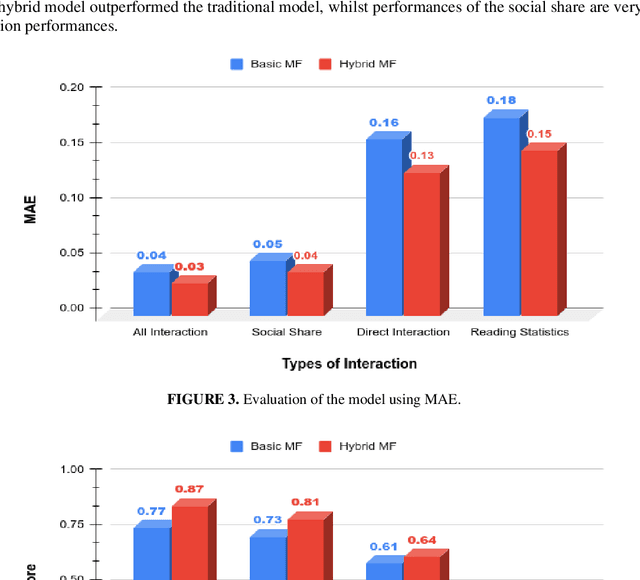
Matrix factorization (MS) is a collaborative filtering (CF) based approach, which is widely used for recommendation systems (RS). In this research work, we deal with the content recommendation problem for users in a content management system (CMS) based on users' feedback data. The CMS is applied for publishing and pushing curated content to the employees of a company or an organization. Here, we have used the user's feedback data and content data to solve the content recommendation problem. We prepare individual user profiles and then generate recommendation results based on different categories, including Direct Interaction, Social Share, and Reading Statistics, of user's feedback data. Subsequently, we analyze the effect of the different categories on the recommendation results. The results have shown that different categories of feedback data have different impacts on recommendation accuracy. The best performance achieves if we include all types of data for the recommendation task. We also incorporate content similarity as a regularization term into an MF model for designing a hybrid model. Experimental results have shown that the proposed hybrid model demonstrates better performance compared with the traditional MF-based models.
Explainable and High-Performance Hate and Offensive Speech Detection
Jun 26, 2022



The spread of information through social media platforms can create environments possibly hostile to vulnerable communities and silence certain groups in society. To mitigate such instances, several models have been developed to detect hate and offensive speech. Since detecting hate and offensive speech in social media platforms could incorrectly exclude individuals from social media platforms, which can reduce trust, there is a need to create explainable and interpretable models. Thus, we build an explainable and interpretable high performance model based on the XGBoost algorithm, trained on Twitter data. For unbalanced Twitter data, XGboost outperformed the LSTM, AutoGluon, and ULMFiT models on hate speech detection with an F1 score of 0.75 compared to 0.38 and 0.37, and 0.38 respectively. When we down-sampled the data to three separate classes of approximately 5000 tweets, XGBoost performed better than LSTM, AutoGluon, and ULMFiT; with F1 scores for hate speech detection of 0.79 vs 0.69, 0.77, and 0.66 respectively. XGBoost also performed better than LSTM, AutoGluon, and ULMFiT in the down-sampled version for offensive speech detection with F1 score of 0.83 vs 0.88, 0.82, and 0.79 respectively. We use Shapley Additive Explanations (SHAP) on our XGBoost models' outputs to makes it explainable and interpretable compared to LSTM, AutoGluon and ULMFiT that are black-box models.
Is Machine Learning Speaking my Language? A Critical Look at the NLP-Pipeline Across 8 Human Languages
Jul 11, 2020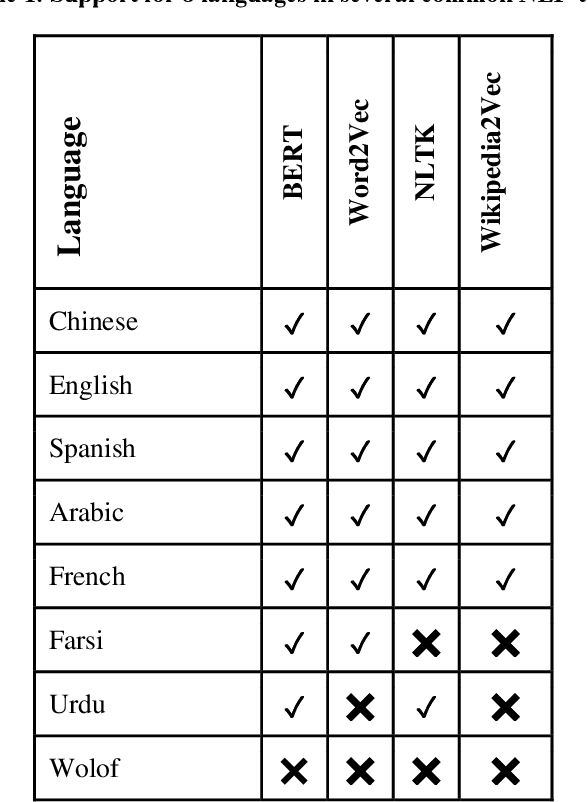
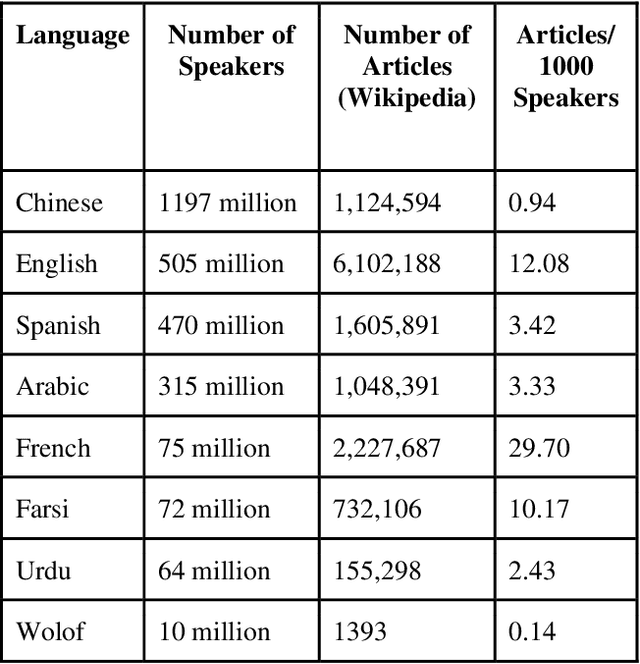
Natural Language Processing (NLP) is increasingly used as a key ingredient in critical decision-making systems such as resume parsers used in sorting a list of job candidates. NLP systems often ingest large corpora of human text, attempting to learn from past human behavior and decisions in order to produce systems that will make recommendations about our future world. Over 7000 human languages are being spoken today and the typical NLP pipeline underrepresents speakers of most of them while amplifying the voices of speakers of other languages. In this paper, a team including speakers of 8 languages - English, Chinese, Urdu, Farsi, Arabic, French, Spanish, and Wolof - takes a critical look at the typical NLP pipeline and how even when a language is technically supported, substantial caveats remain to prevent full participation. Despite huge and admirable investments in multilingual support in many tools and resources, we are still making NLP-guided decisions that systematically and dramatically underrepresent the voices of much of the world.