 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Traffic Characteristics Reveal an IoT Devices Identity
Feb 25, 2024


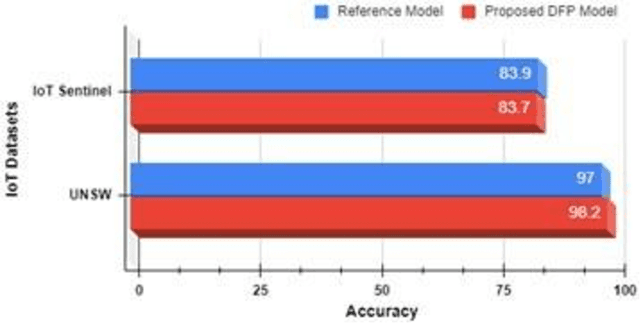
Internet of Things (IoT) is one of the technological advancements of the twenty-first century which can improve living standards. However, it also imposes new types of security challenges, including device authentication, traffic types classification, and malicious traffic identification, in the network domain. Traditionally, internet protocol (IP) and media access control (MAC) addresses are utilized for identifying network-connected devices in a network, whilst these addressing schemes are prone to be compromised, including spoofing attacks and MAC randomization. Therefore, device identification using only explicit identifiers is a challenging task. Accurate device identification plays a key role in securing a network. In this paper, a supervised machine learning-based device fingerprinting (DFP) model has been proposed for identifying network-connected IoT devices using only communication traffic characteristics (or implicit identifiers). A single transmission control protocol/internet protocol (TCP/IP) packet header features have been utilized for generating unique fingerprints, with the fingerprints represented as a vector of 22 features. Experimental results have shown that the proposed DFP method achieves over 98% in classifying individual IoT devices using the UNSW dataset with 22 smart-home IoT devices. This signifies that the proposed approach is invaluable to network operators in making their networks more secure.
A Hypergraph-Based Approach to Recommend Online Resources in a Library
Dec 02, 2023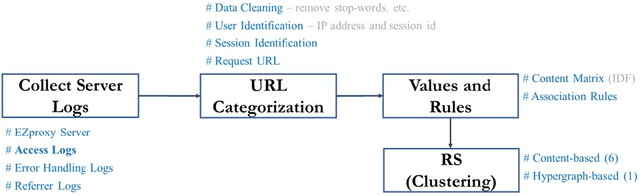

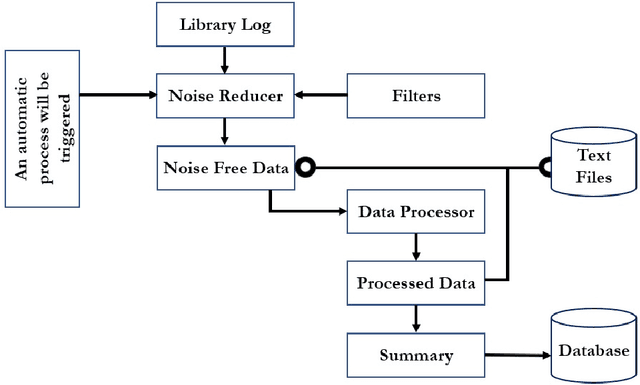
When users in a digital library read or browse online resources, it generates an immense amount of data. If the underlying system can recommend items, such as books and journals, to the users, it will help them to find the related items. This research analyzes a digital library's usage data to recommend items to its users, and it uses different clustering algorithms to design the recommender system. We have used content-based clustering, including hierarchical, expectation maximization (EM), K-mean, FarthestFirst, and density-based clustering algorithms, and user access pattern-based clustering, which uses a hypergraph-based approach to generate the clusters. This research shows that the recommender system designed using the hypergraph algorithm generates the most accurate recommendation model compared to those designed using the content-based clustering approaches.
Attention at SemEval-2023 Task 10: Explainable Detection of Online Sexism
Apr 10, 2023
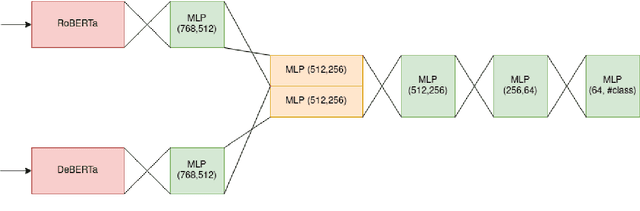


In this paper, we have worked on interpretability, trust, and understanding of the decisions made by models in the form of classification tasks. The task is divided into 3 subtasks. The first task consists of determining Binary Sexism Detection. The second task describes the Category of Sexism. The third task describes a more Fine-grained Category of Sexism. Our work explores solving these tasks as a classification problem by fine-tuning transformer-based architecture. We have performed several experiments with our architecture, including combining multiple transformers, using domain adaptive pretraining on the unlabelled dataset provided by Reddit and Gab, Joint learning, and taking different layers of transformers as input to a classification head. Our system (with team name Attention) was able to achieve a macro F1 score of 0.839 for task A, 0.5835 macro F1 score for task B and 0.3356 macro F1 score for task C at the Codalab SemEval Competition. Later we improved the accuracy of Task B to 0.6228 and Task C to 0.3693 in the test set.
Item Recommendation Using User Feedback Data and Item Profile
Jun 28, 2022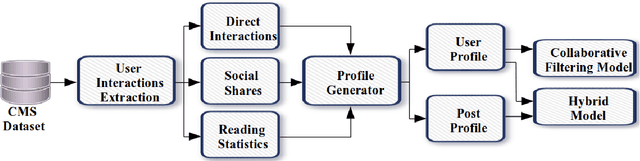
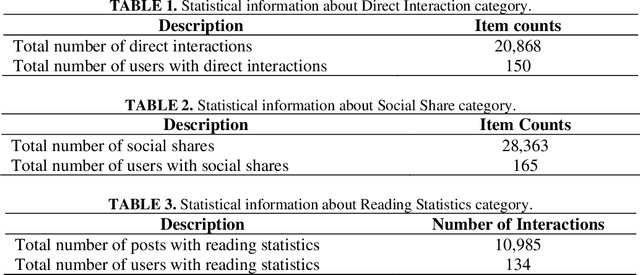
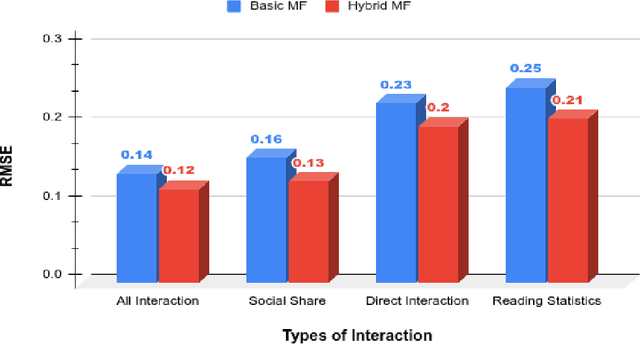
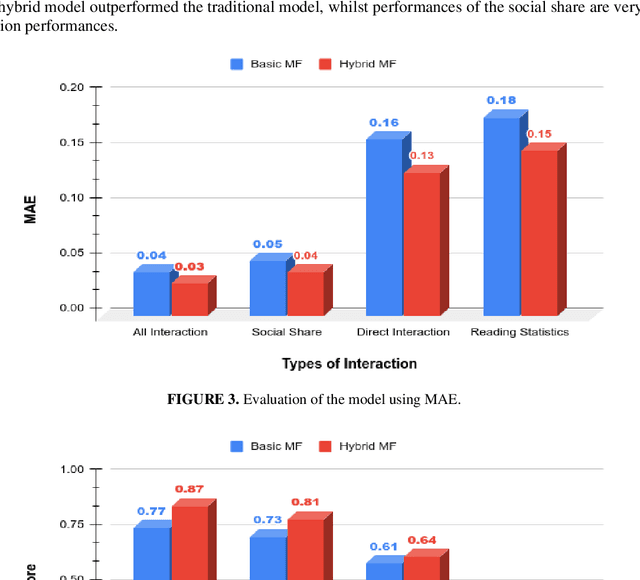
Matrix factorization (MS) is a collaborative filtering (CF) based approach, which is widely used for recommendation systems (RS). In this research work, we deal with the content recommendation problem for users in a content management system (CMS) based on users' feedback data. The CMS is applied for publishing and pushing curated content to the employees of a company or an organization. Here, we have used the user's feedback data and content data to solve the content recommendation problem. We prepare individual user profiles and then generate recommendation results based on different categories, including Direct Interaction, Social Share, and Reading Statistics, of user's feedback data. Subsequently, we analyze the effect of the different categories on the recommendation results. The results have shown that different categories of feedback data have different impacts on recommendation accuracy. The best performance achieves if we include all types of data for the recommendation task. We also incorporate content similarity as a regularization term into an MF model for designing a hybrid model. Experimental results have shown that the proposed hybrid model demonstrates better performance compared with the traditional MF-based models.