 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Optimization of Multi-User NOMA-Assisted Cooperative THz-SIMO MEC Systems
Apr 08, 2023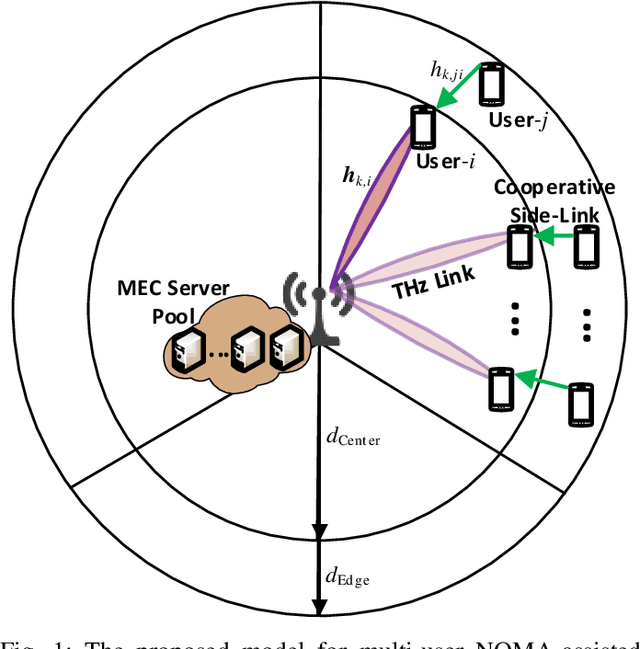
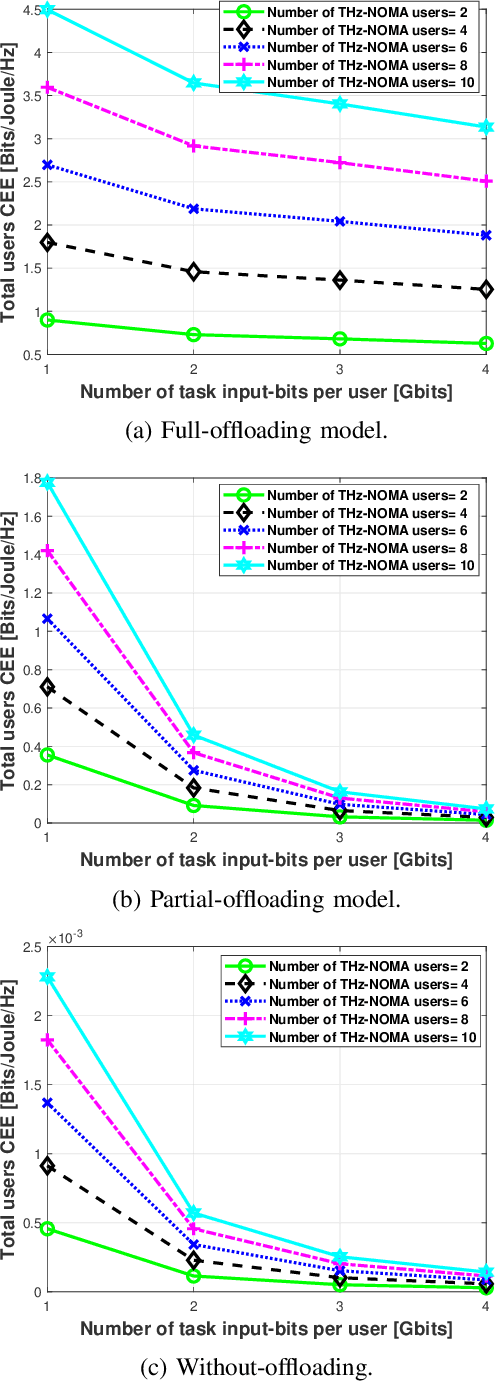
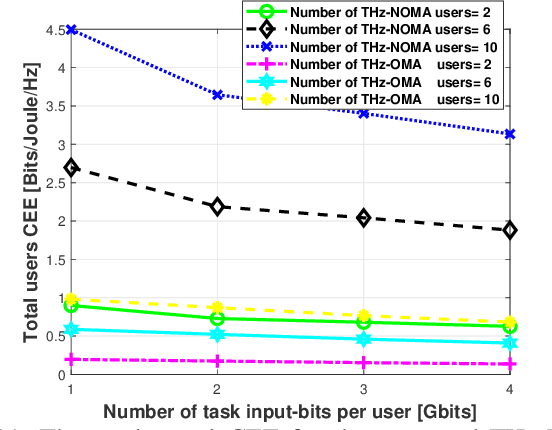
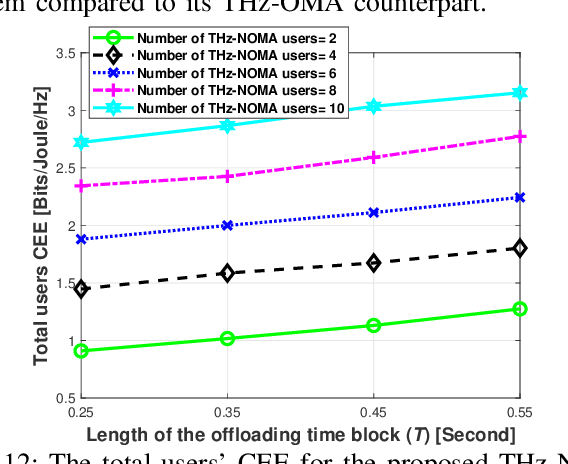
The various requirements in terms of data rates and latency in beyond 5G and 6G networks have motivated the integration of a variety of communications schemes and technologies to meet these requirements in such networks. Among these schemes are Terahertz (THz) communications, cooperative non-orthogonal multiple-access (NOMA)-enabled schemes, and mobile edge computing (MEC). THz communications offer abundant bandwidth for high-data-rate short-distance applications and NOMA-enabled schemes are promising schemes to realize the target spectral efficiencies and low latency requirements in future networks, while MEC would allow distributed processing and data offloading for the emerging applications in these networks. In this paper, an energy-efficient scheme of multi-user NOMA-assisted cooperative THz single-input multiple-output (SIMO) MEC systems is proposed to allow the uplink transmission of offloaded data from the far cell-edge users to the more computing resources in the base station (BS) through the cell-center users. To reinforce the performance of the proposed scheme, two optimization problems are formulated and solved, namely, the first problem minimizes the total users' energy consumption while the second problem maximizes the total users' computation energy efficiency (CEE) for the proposed scheme. In both problems, the NOMA user pairing, the BS receive beamforming, the transmission time allocation, and the NOMA transmission power allocation coefficients are optimized, while taking into account the full-offloading requirements of each user as well as the predefined latency constraint of the system. The obtained results reveal new insights into the performance and design of multi-user NOMA-assisted cooperative THz-SIMO MEC systems.
Optimization of FPGA-based CNN Accelerators Using Metaheuristics
Sep 22, 2022In recent years, convolutional neural networks (CNNs) have demonstrated their ability to solve problems in many fields and with accuracy that was not possible before. However, this comes with extensive computational requirements, which made general CPUs unable to deliver the desired real-time performance. At the same time, FPGAs have seen a surge in interest for accelerating CNN inference. This is due to their ability to create custom designs with different levels of parallelism. Furthermore, FPGAs provide better performance per watt compared to GPUs. The current trend in FPGA-based CNN accelerators is to implement multiple convolutional layer processors (CLPs), each of which is tailored for a subset of layers. However, the growing complexity of CNN architectures makes optimizing the resources available on the target FPGA device to deliver optimal performance more challenging. In this paper, we present a CNN accelerator and an accompanying automated design methodology that employs metaheuristics for partitioning available FPGA resources to design a Multi-CLP accelerator. Specifically, the proposed design tool adopts simulated annealing (SA) and tabu search (TS) algorithms to find the number of CLPs required and their respective configurations to achieve optimal performance on a given target FPGA device. Here, the focus is on the key specifications and hardware resources, including digital signal processors, block RAMs, and off-chip memory bandwidth. Experimental results and comparisons using four well-known benchmark CNNs are presented demonstrating that the proposed acceleration framework is both encouraging and promising. The SA-/TS-based Multi-CLP achieves 1.31x - 2.37x higher throughput than the state-of-the-art Single-/Multi-CLP approaches in accelerating AlexNet, SqueezeNet 1.1, VGGNet, and GoogLeNet architectures on the Xilinx VC707 and VC709 FPGA boards.
FxP-QNet: A Post-Training Quantizer for the Design of Mixed Low-Precision DNNs with Dynamic Fixed-Point Representation
Mar 22, 2022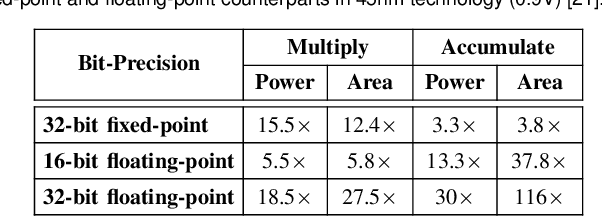

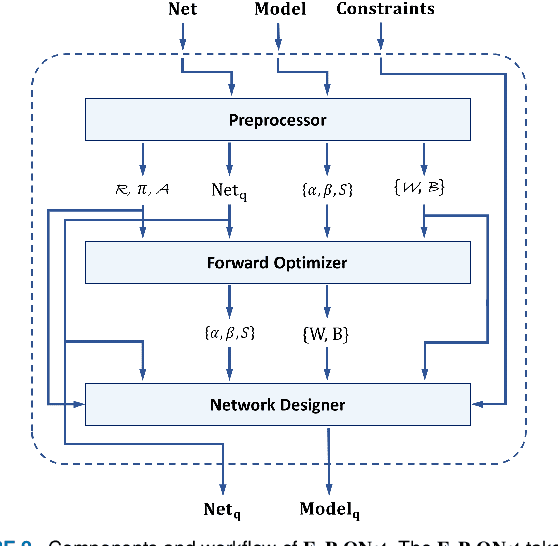
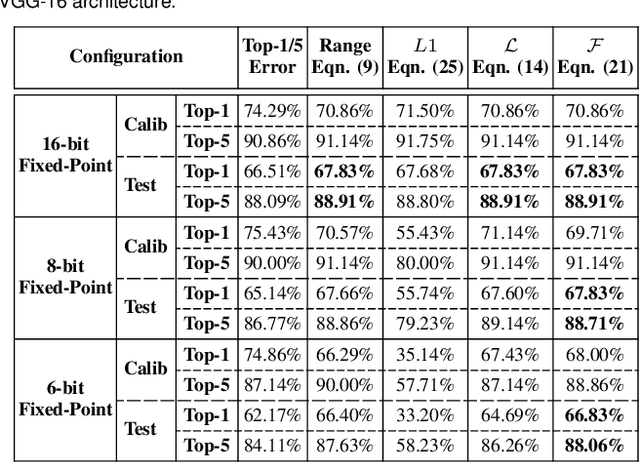
Deep neural networks (DNNs) have demonstrated their effectiveness in a wide range of computer vision tasks, with the state-of-the-art results obtained through complex and deep structures that require intensive computation and memory. Now-a-days, efficient model inference is crucial for consumer applications on resource-constrained platforms. As a result, there is much interest in the research and development of dedicated deep learning (DL) hardware to improve the throughput and energy efficiency of DNNs. Low-precision representation of DNN data-structures through quantization would bring great benefits to specialized DL hardware. However, the rigorous quantization leads to a severe accuracy drop. As such, quantization opens a large hyper-parameter space at bit-precision levels, the exploration of which is a major challenge. In this paper, we propose a novel framework referred to as the Fixed-Point Quantizer of deep neural Networks (FxP-QNet) that flexibly designs a mixed low-precision DNN for integer-arithmetic-only deployment. Specifically, the FxP-QNet gradually adapts the quantization level for each data-structure of each layer based on the trade-off between the network accuracy and the low-precision requirements. Additionally, it employs post-training self-distillation and network prediction error statistics to optimize the quantization of floating-point values into fixed-point numbers. Examining FxP-QNet on state-of-the-art architectures and the benchmark ImageNet dataset, we empirically demonstrate the effectiveness of FxP-QNet in achieving the accuracy-compression trade-off without the need for training. The results show that FxP-QNet-quantized AlexNet, VGG-16, and ResNet-18 reduce the overall memory requirements of their full-precision counterparts by 7.16x, 10.36x, and 6.44x with less than 0.95%, 0.95%, and 1.99% accuracy drop, respectively.
A Review of Open Source Software Tools for Time Series Analysis
Mar 10, 2022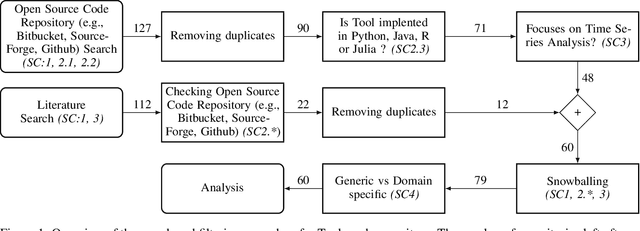
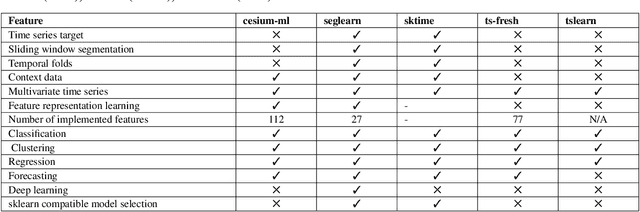
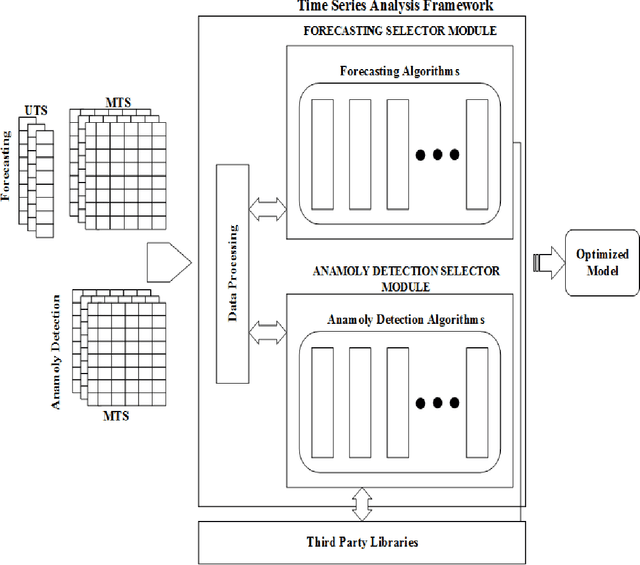

Time series data is used in a wide range of real world applications. In a variety of domains , detailed analysis of time series data (via Forecasting and Anomaly Detection) leads to a better understanding of how events associated with a specific time instance behave. Time Series Analysis (TSA) is commonly performed with plots and traditional models. Machine Learning (ML) approaches , on the other hand , have seen an increase in the state of the art for Forecasting and Anomaly Detection because they provide comparable results when time and data constraints are met. A number of time series toolboxes are available that offer rich interfaces to specific model classes (ARIMA/filters , neural networks) or framework interfaces to isolated time series modelling tasks (forecasting , feature extraction , annotation , classification). Nonetheless , open source machine learning capabilities for time series remain limited , and existing libraries are frequently incompatible with one another. The goal of this paper is to provide a concise and user friendly overview of the most important open source tools for time series analysis. This article examines two related toolboxes (1) forecasting and (2) anomaly detection. This paper describes a typical Time Series Analysis (TSA) framework with an architecture and lists the main features of TSA framework. The tools are categorized based on the criteria of analysis tasks completed , data preparation methods employed , and evaluation methods for results generated. This paper presents quantitative analysis and discusses the current state of actively developed open source Time Series Analysis frameworks. Overall , this article considered 60 time series analysis tools , and 32 of which provided forecasting modules , and 21 packages included anomaly detection.
On the Achievable Max-Min User Rates in Multi-Carrier Centralized NOMA-VLC Networks
May 26, 2021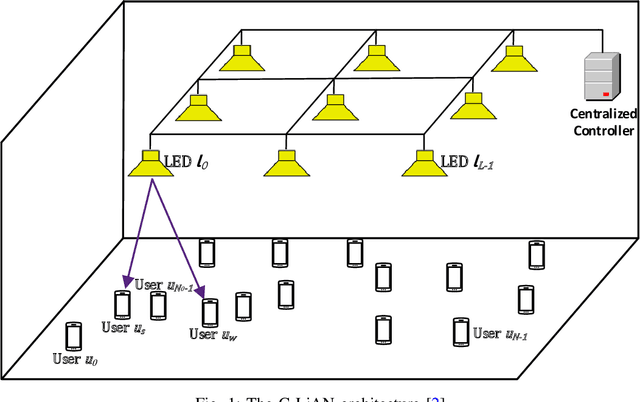
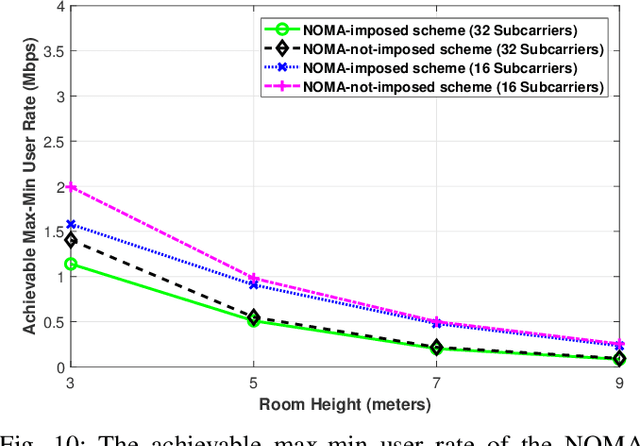
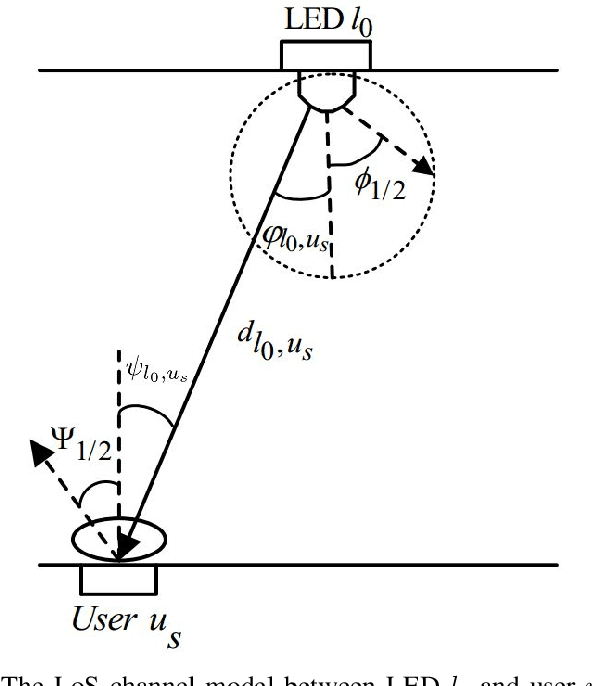
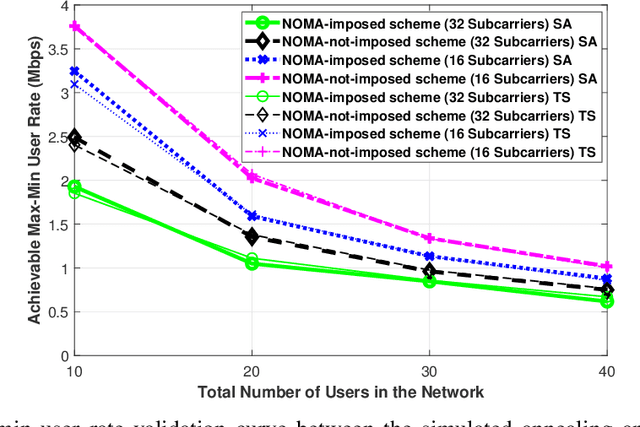
Visible light communications (VLC) is gaining interest as one of the enablers of short-distance, high-data-rate applications, in future beyond 5G networks. Moreover, non-orthogonal multiple-access (NOMA)-enabled schemes have recently emerged as a promising multiple-access scheme for these networks that would allow realization of the target spectral efficiency and user fairness requirements. The integration of NOMA in the widely adopted orthogonal frequency-division multiplexing (OFDM)-based VLC networks would require an optimal resource allocation for the pair or the cluster of users sharing the same subcarrier(s). In this paper, the max-min rate of a multi-cell indoor centralized VLC network is maximized through optimizing user pairing, subcarrier allocation, and power allocation. The joint complex optimization problem is tackled using a low-complexity solution. At first, the user pairing is assumed to follow the divide-and-next-largest-difference user-pairing algorithm (D-NLUPA) that can ensure fairness among the different clusters. Then, subcarrier allocation and power allocation are solved iteratively through both the Simulated Annealing (SA) meta-heuristic algorithm and the bisection method. The obtained results quantify the achievable max-min user rates for the different relevant variants of NOMA-enabled schemes and shed new light on both the performance and design of multi-user multi-carrier NOMA-enabled centralized VLC networks.
Energy-Efficient Coverage Enhancement of Indoor THz-MISO Systems: An FD-NOMA Approach
Apr 12, 2021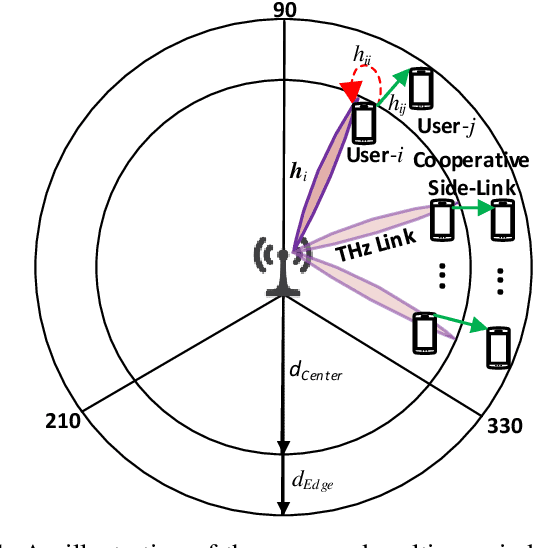
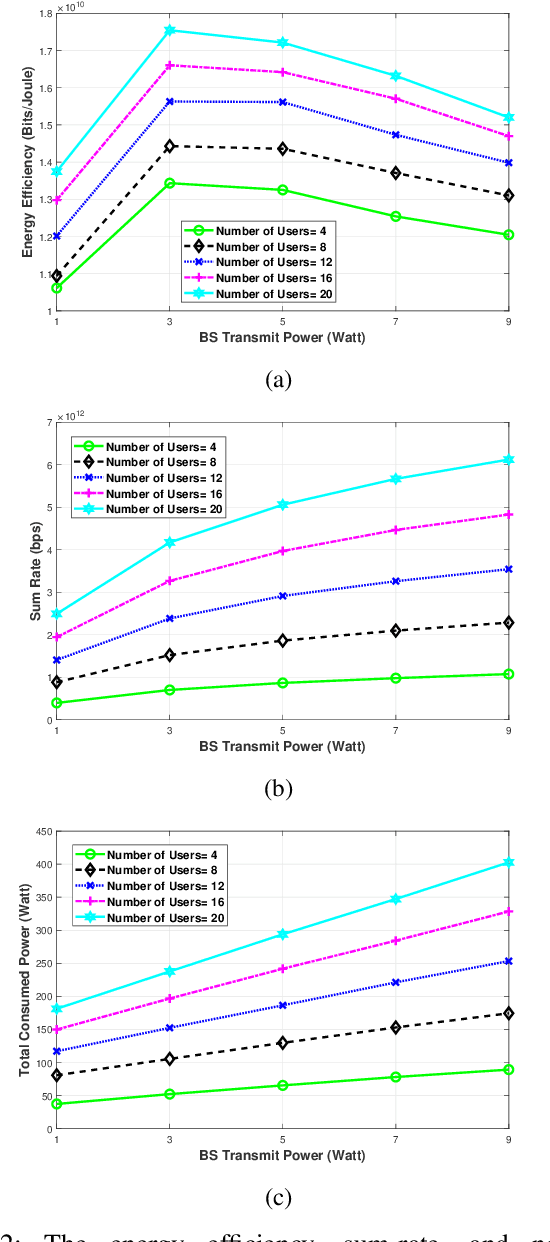
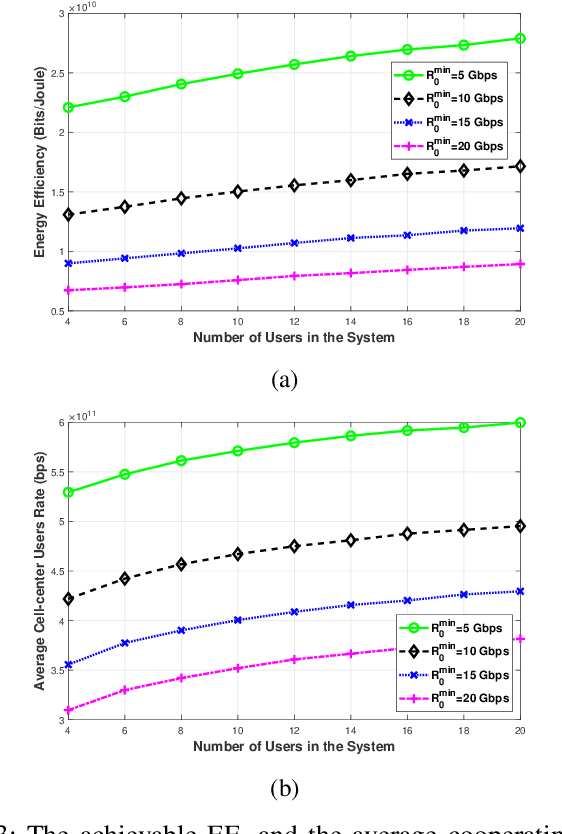
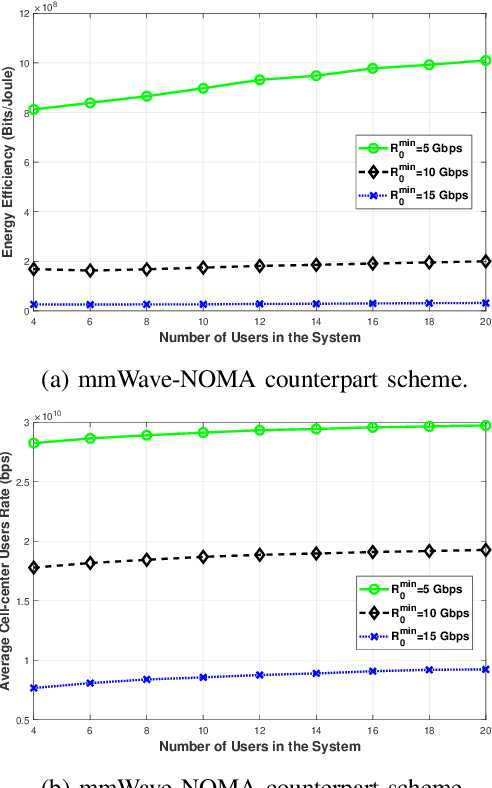
Terahertz (THz) communication is gaining more interest as one of the envisioned enablers of high-data-rate short-distance indoor applications in beyond 5G networks. Moreover, non-orthogonal multiple-access (NOMA)-enabled schemes are promising schemes to realize the target spectral efficiency, low latency, and user fairness requirements in future networks. In this paper, an energy-efficient cooperative NOMA (CNOMA) scheme that guarantees the minimum required rate for cell-edge users in an indoor THz-MISO communications network, is proposed. The proposed cooperative scheme consists of three stages: (i) beamforming stage that allocates BS beams to THz cooperating cell-center users using analog beamforming with the aid of the cosine similarity metric, (ii) user pairing stage that is tackled using the Hungarian algorithm, and (iii) a power allocation stage for the BS THz-NOMA transmit power as well as the cooperation power of the cooperating cell-center users, which is optimized in a sequential manner. The obtained results quantify the EE of the proposed scheme and shed new light on both the performance and design of multi-user THz-NOMA-enabled networks.
FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review
Jan 01, 2019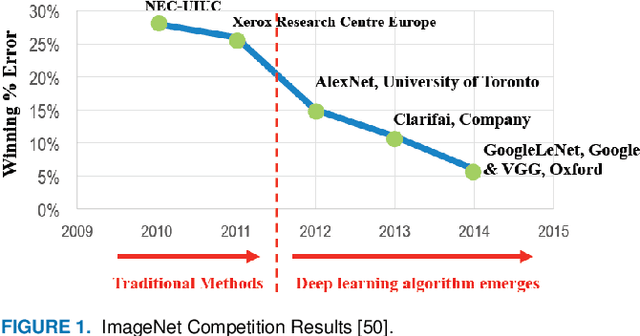
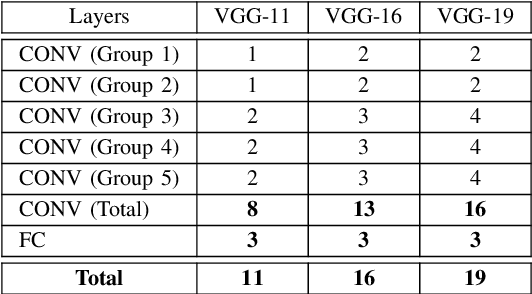
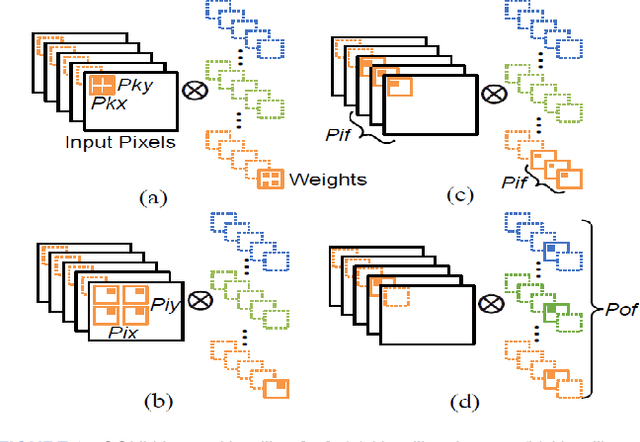
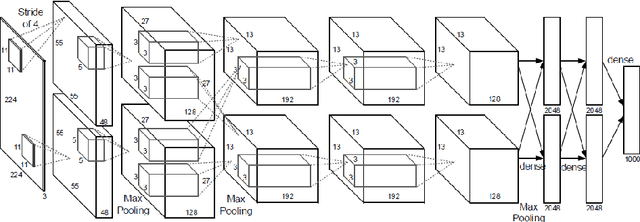
Due to recent advances in digital technologies, and availability of credible data, an area of artificial intelligence, deep learning, has emerged, and has demonstrated its ability and effectiveness in solving complex learning problems not possible before. In particular, convolution neural networks (CNNs) have demonstrated their effectiveness in image detection and recognition applications. However, they require intensive CPU operations and memory bandwidth that make general CPUs fail to achieve desired performance levels. Consequently, hardware accelerators that use application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), and graphic processing units (GPUs) have been employed to improve the throughput of CNNs. More precisely, FPGAs have been recently adopted for accelerating the implementation of deep learning networks due to their ability to maximize parallelism as well as due to their energy efficiency. In this paper, we review recent existing techniques for accelerating deep learning networks on FPGAs. We highlight the key features employed by the various techniques for improving the acceleration performance. In addition, we provide recommendations for enhancing the utilization of FPGAs for CNNs acceleration. The techniques investigated in this paper represent the recent trends in FPGA-based accelerators of deep learning networks. Thus, this review is expected to direct the future advances on efficient hardware accelerators and to be useful for deep learning researchers.