 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaqyim: Evaluating Arabic NLP Tasks Using ChatGPT Models
Jun 28, 2023



Large language models (LLMs) have demonstrated impressive performance on various downstream tasks without requiring fine-tuning, including ChatGPT, a chat-based model built on top of LLMs such as GPT-3.5 and GPT-4. Despite having a lower training proportion compared to English, these models also exhibit remarkable capabilities in other languages. In this study, we assess the performance of GPT-3.5 and GPT-4 models on seven distinct Arabic NLP tasks: sentiment analysis, translation, transliteration, paraphrasing, part of speech tagging, summarization, and diacritization. Our findings reveal that GPT-4 outperforms GPT-3.5 on five out of the seven tasks. Furthermore, we conduct an extensive analysis of the sentiment analysis task, providing insights into how LLMs achieve exceptional results on a challenging dialectal dataset. Additionally, we introduce a new Python interface https://github.com/ARBML/Taqyim that facilitates the evaluation of these tasks effortlessly.
Masader Plus: A New Interface for Exploring +500 Arabic NLP Datasets
Aug 01, 2022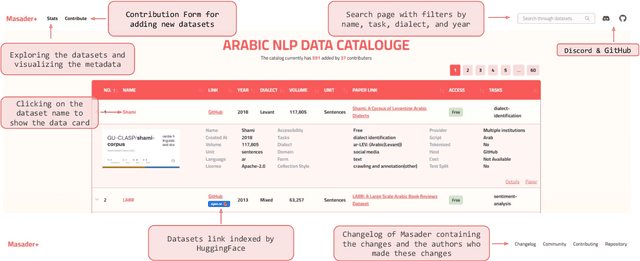
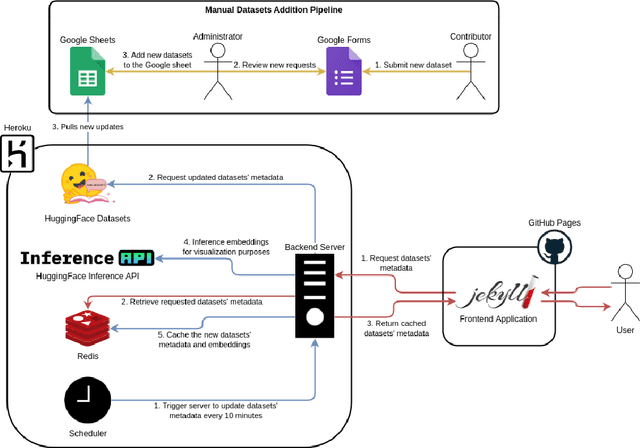
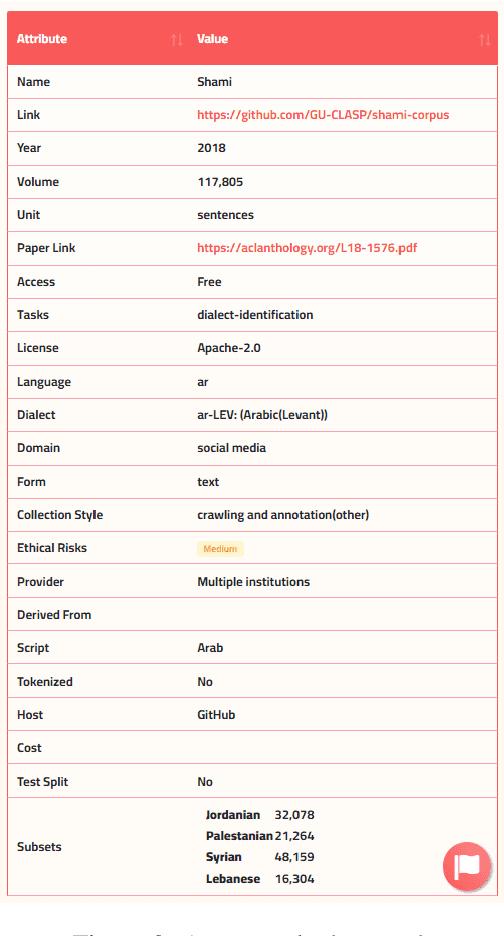
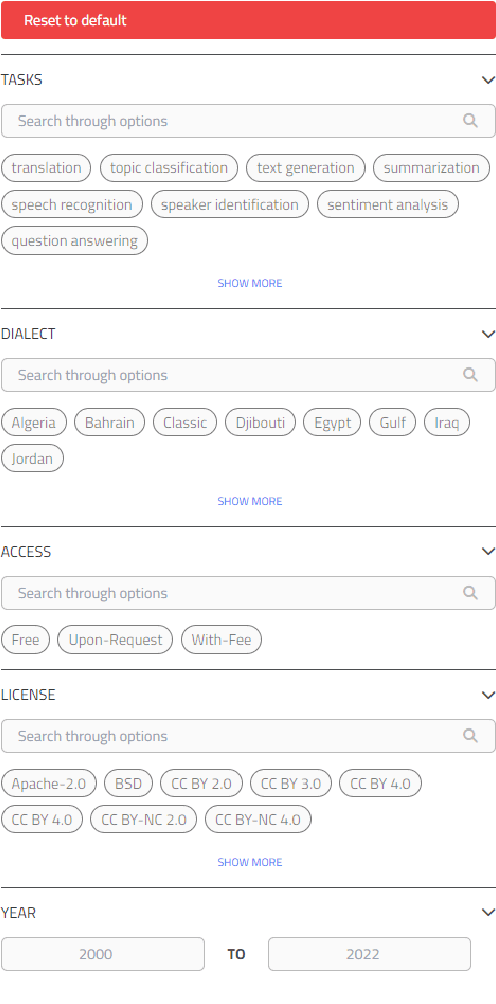
Masader (Alyafeai et al., 2021) created a metadata structure to be used for cataloguing Arabic NLP datasets. However, developing an easy way to explore such a catalogue is a challenging task. In order to give the optimal experience for users and researchers exploring the catalogue, several design and user experience challenges must be resolved. Furthermore, user interactions with the website may provide an easy approach to improve the catalogue. In this paper, we introduce Masader Plus, a web interface for users to browse Masader. We demonstrate data exploration, filtration, and a simple API that allows users to examine datasets from the backend. Masader Plus can be explored using this link https://arbml.github.io/masader. A video recording explaining the interface can be found here https://www.youtube.com/watch?v=SEtdlSeqchk.
Tha3aroon at NSURL-2019 Task 8: Semantic Question Similarity in Arabic
Dec 28, 2019

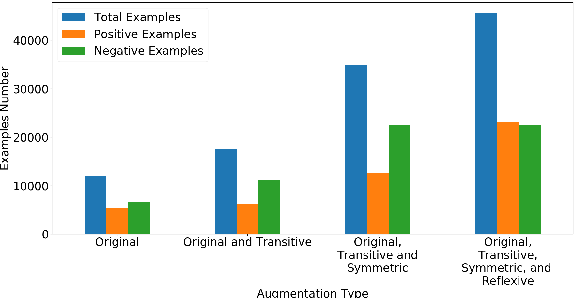
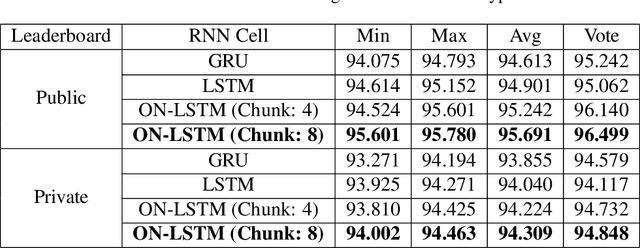
In this paper, we describe our team's effort on the semantic text question similarity task of NSURL 2019. Our top performing system utilizes several innovative data augmentation techniques to enlarge the training data. Then, it takes ELMo pre-trained contextual embeddings of the data and feeds them into an ON-LSTM network with self-attention. This results in sequence representation vectors that are used to predict the relation between the question pairs. The model is ranked in the 1st place with 96.499 F1-score (same as the second place F1-score) and the 2nd place with 94.848 F1-score (differs by 1.076 F1-score from the first place) on the public and private leaderboards, respectively.
Neural Arabic Text Diacritization: State of the Art Results and a Novel Approach for Machine Translation
Nov 08, 2019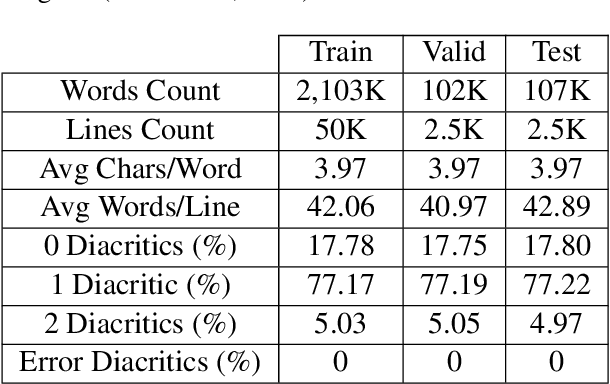
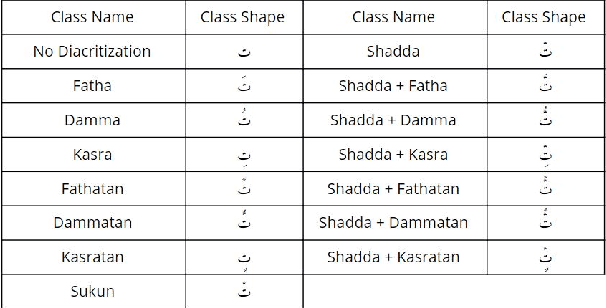

In this work, we present several deep learning models for the automatic diacritization of Arabic text. Our models are built using two main approaches, viz. Feed-Forward Neural Network (FFNN) and Recurrent Neural Network (RNN), with several enhancements such as 100-hot encoding, embeddings, Conditional Random Field (CRF) and Block-Normalized Gradient (BNG). The models are tested on the only freely available benchmark dataset and the results show that our models are either better or on par with other models, which require language-dependent post-processing steps, unlike ours. Moreover, we show that diacritics in Arabic can be used to enhance the models of NLP tasks such as Machine Translation (MT) by proposing the Translation over Diacritization (ToD) approach.
Arabic Text Diacritization Using Deep Neural Networks
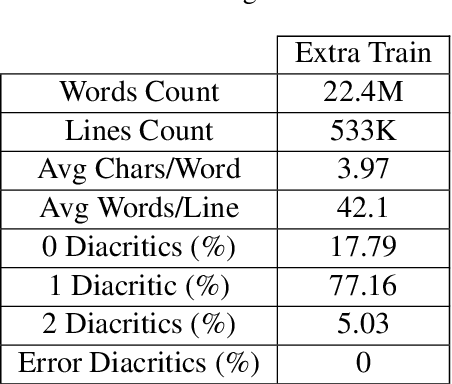
Apr 25, 2019
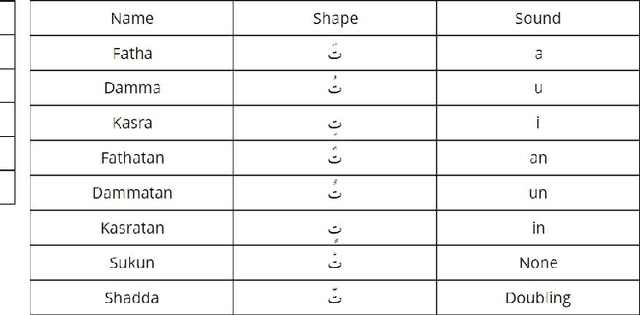


Diacritization of Arabic text is both an interesting and a challenging problem at the same time with various applications ranging from speech synthesis to helping students learning the Arabic language. Like many other tasks or problems in Arabic language processing, the weak efforts invested into this problem and the lack of available (open-source) resources hinder the progress towards solving this problem. This work provides a critical review for the currently existing systems, measures and resources for Arabic text diacritization. Moreover, it introduces a much-needed free-for-all cleaned dataset that can be easily used to benchmark any work on Arabic diacritization. Extracted from the Tashkeela Corpus, the dataset consists of 55K lines containing about 2.3M words. After constructing the dataset, existing tools and systems are tested on it. The results of the experiments show that the neural Shakkala system significantly outperforms traditional rule-based approaches and other closed-source tools with a Diacritic Error Rate (DER) of 2.88% compared with 13.78%, which the best DER for the non-neural approach (obtained by the Mishkal tool).