 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesarcasm detection and quantification in arabic tweets
Aug 03, 2021
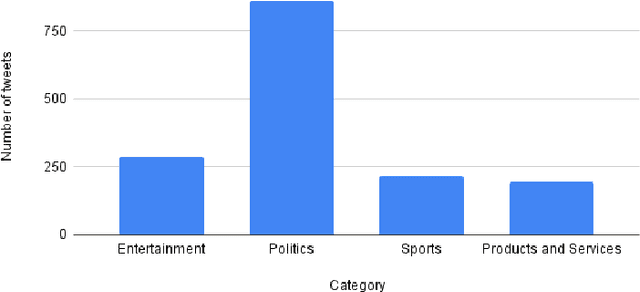
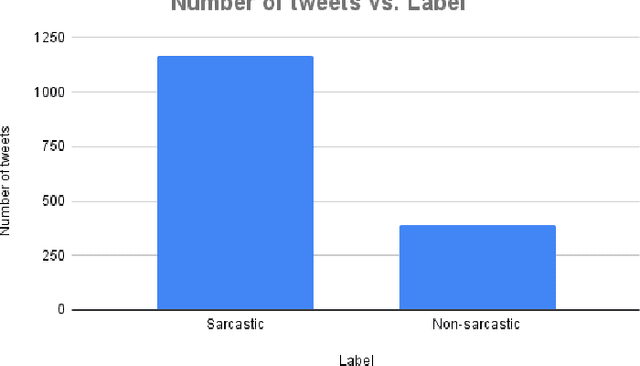

The role of predicting sarcasm in the text is known as automatic sarcasm detection. Given the prevalence and challenges of sarcasm in sentiment-bearing text, this is a critical phase in most sentiment analysis tasks. With the increasing popularity and usage of different social media platforms among users around the world, people are using sarcasm more and more in their day-to-day conversations, social media posts and tweets, and it is considered as a way for people to express their sentiment about some certain topics or issues. As a result of the increasing popularity, researchers started to focus their research endeavors on detecting sarcasm from a text in different languages especially the English language. However, the task of sarcasm detection is a challenging task due to the nature of sarcastic texts; which can be relative and significantly differs from one person to another depending on the topic, region, the user's mentality and other factors. In addition to these challenges, sarcasm detection in the Arabic language has its own challenges due to the complexity of the Arabic language, such as being morphologically rich, with many dialects that significantly vary between each other, while also being lowly resourced. In recent years, only few research attempts started tackling the task of sarcasm detection in Arabic, including creating and collecting corpora, organizing workshops and establishing baseline models. This paper intends to create a new humanly annotated Arabic corpus for sarcasm detection collected from tweets, and implementing a new approach for sarcasm detection and quantification in Arabic tweets. The annotation technique followed in this paper is unique in sarcasm detection and the proposed approach tackles the problem as a regression problem instead of classification; i.e., the model attempts to predict the level of sarcasm instead of binary classification.
The 2ST-UNet for Pneumothorax Segmentation in Chest X-Rays using ResNet34 as a Backbone for U-Net
Sep 06, 2020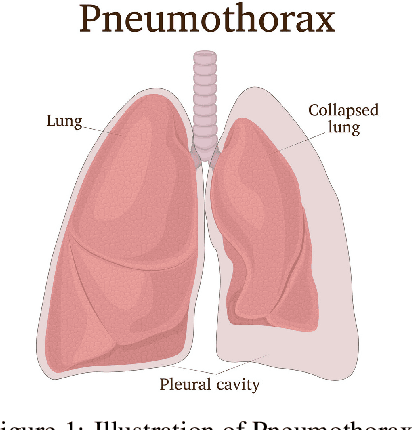
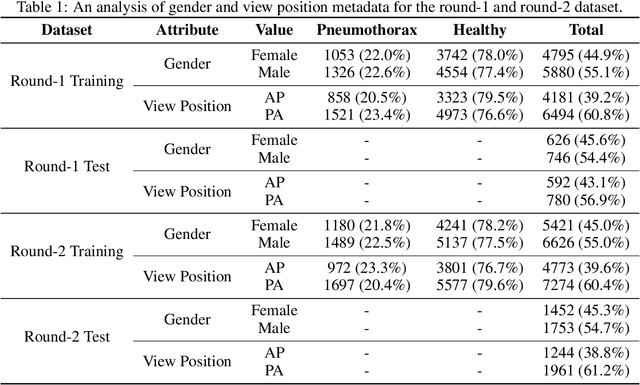
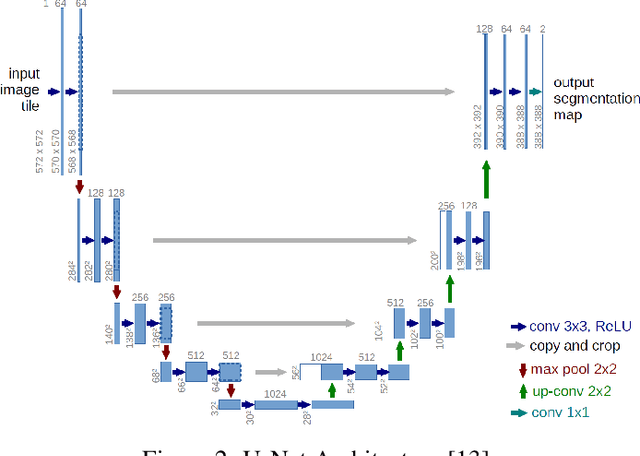

Pneumothorax, also called a collapsed lung, refers to the presence of the air in the pleural space between the lung and chest wall. It can be small (no need for treatment), or large and causes death if it is not identified and treated on time. It is easily seen and identified by experts using a chest X-ray. Although this method is mostly error-free, it is time-consuming and needs expert radiologists. Recently, Computer Vision has been providing great assistance in detecting and segmenting pneumothorax. In this paper, we propose a 2-Stage Training system (2ST-UNet) to segment images with pneumothorax. This system is built based on U-Net with Residual Networks (ResNet-34) backbone that is pre-trained on the ImageNet dataset. We start with training the network at a lower resolution before we load the trained model weights to retrain the network with a higher resolution. Moreover, we utilize different techniques including Stochastic Weight Averaging (SWA), data augmentation, and Test-Time Augmentation (TTA). We use the chest X-ray dataset that is provided by the 2019 SIIM-ACR Pneumothorax Segmentation Challenge, which contains 12,047 training images and 3,205 testing images. Our experiments show that 2-Stage Training leads to better and faster network convergence. Our method achieves 0.8356 mean Dice Similarity Coefficient (DSC) placing it among the top 9% of models with a rank of 124 out of 1,475.
Predicting Helpfulness of Online Reviews
Aug 23, 2020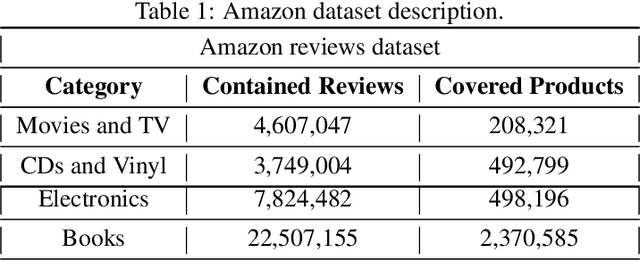

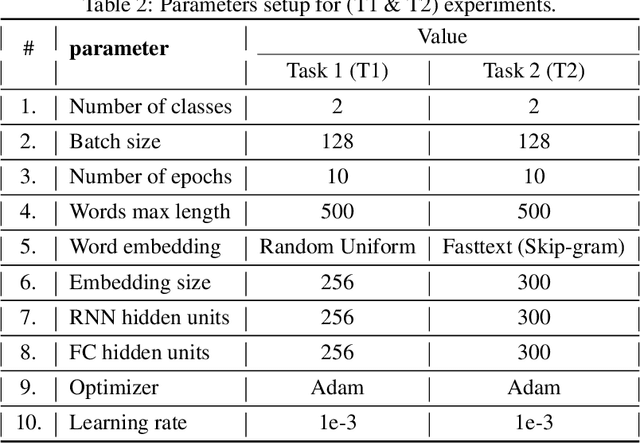
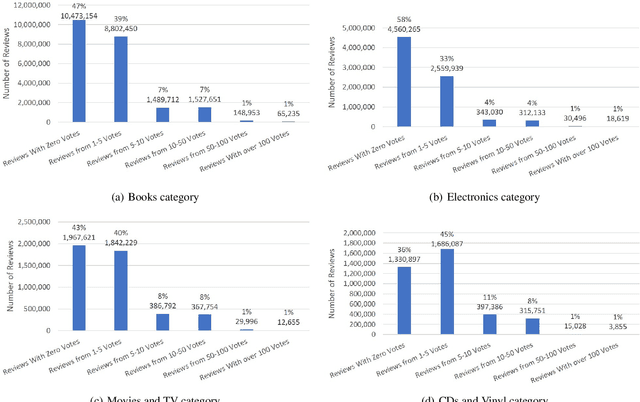
E-commerce dominates a large part of the world's economy with many websites dedicated to online selling products. The vast majority of e-commerce websites provide their customers with the ability to express their opinions about the products/services they purchase. These feedback in the form of reviews represent a rich source of information about the users' experiences and level of satisfaction, which is of great benefit to both the producer and the consumer. However, not all of these reviews are helpful/useful. The traditional way of determining the helpfulness of a review is through the feedback from human users. However, such a method does not necessarily cover all reviews. Moreover, it has many issues like bias, high cost, etc. Thus, there is a need to automate this process. This paper presents a set of machine learning (ML) models to predict the helpfulness online reviews. Mainly, three approaches are used: a supervised learning approach (using ML as well as deep learning (DL) models), a semi-supervised approach (that combines DL models with word embeddings), and pre-trained word embedding models that uses transfer learning (TL). The latter two approaches are among the unique aspects of this paper as they follow the recent trend of utilizing unlabeled text. The results show that the proposed DL approaches have superiority over the traditional existing ones. Moreover, the semi-supervised has a remarkable performance compared with the other ones.
Tha3aroon at NSURL-2019 Task 8: Semantic Question Similarity in Arabic
Dec 28, 2019

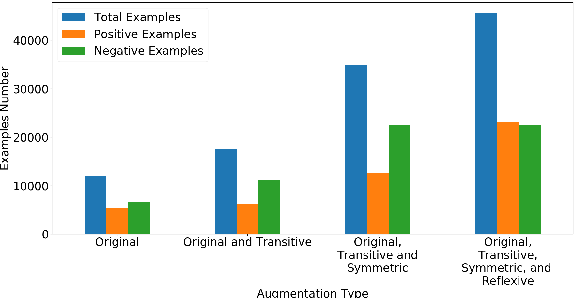
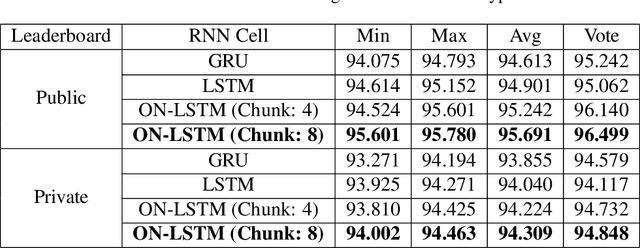
In this paper, we describe our team's effort on the semantic text question similarity task of NSURL 2019. Our top performing system utilizes several innovative data augmentation techniques to enlarge the training data. Then, it takes ELMo pre-trained contextual embeddings of the data and feeds them into an ON-LSTM network with self-attention. This results in sequence representation vectors that are used to predict the relation between the question pairs. The model is ranked in the 1st place with 96.499 F1-score (same as the second place F1-score) and the 2nd place with 94.848 F1-score (differs by 1.076 F1-score from the first place) on the public and private leaderboards, respectively.
Neural Arabic Text Diacritization: State of the Art Results and a Novel Approach for Machine Translation
Nov 08, 2019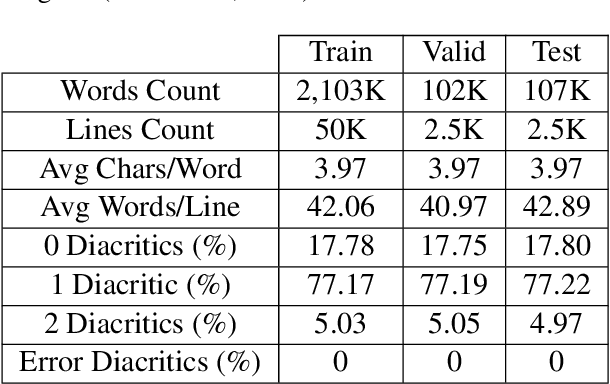
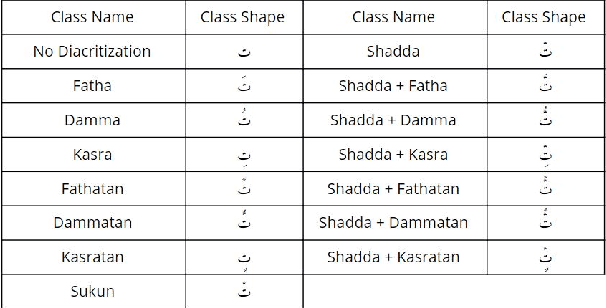

In this work, we present several deep learning models for the automatic diacritization of Arabic text. Our models are built using two main approaches, viz. Feed-Forward Neural Network (FFNN) and Recurrent Neural Network (RNN), with several enhancements such as 100-hot encoding, embeddings, Conditional Random Field (CRF) and Block-Normalized Gradient (BNG). The models are tested on the only freely available benchmark dataset and the results show that our models are either better or on par with other models, which require language-dependent post-processing steps, unlike ours. Moreover, we show that diacritics in Arabic can be used to enhance the models of NLP tasks such as Machine Translation (MT) by proposing the Translation over Diacritization (ToD) approach.
Arabic Text Diacritization Using Deep Neural Networks
Apr 25, 2019
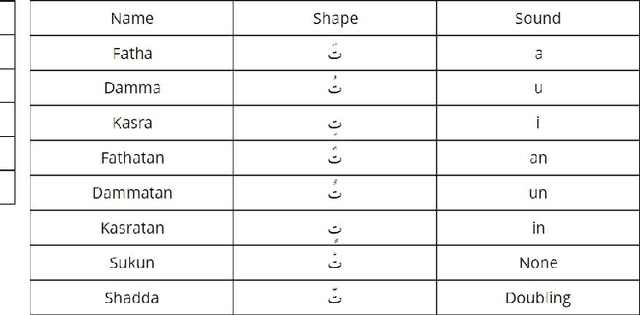


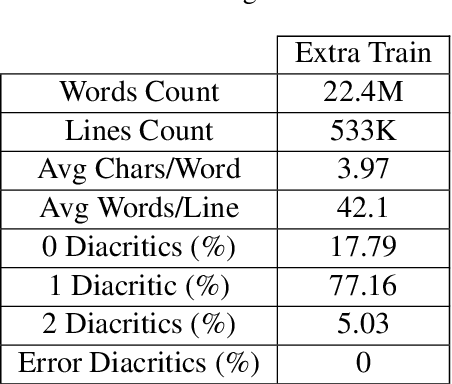
Diacritization of Arabic text is both an interesting and a challenging problem at the same time with various applications ranging from speech synthesis to helping students learning the Arabic language. Like many other tasks or problems in Arabic language processing, the weak efforts invested into this problem and the lack of available (open-source) resources hinder the progress towards solving this problem. This work provides a critical review for the currently existing systems, measures and resources for Arabic text diacritization. Moreover, it introduces a much-needed free-for-all cleaned dataset that can be easily used to benchmark any work on Arabic diacritization. Extracted from the Tashkeela Corpus, the dataset consists of 55K lines containing about 2.3M words. After constructing the dataset, existing tools and systems are tested on it. The results of the experiments show that the neural Shakkala system significantly outperforms traditional rule-based approaches and other closed-source tools with a Diacritic Error Rate (DER) of 2.88% compared with 13.78%, which the best DER for the non-neural approach (obtained by the Mishkal tool).
On the Use of Emojis to Train Emotion Classifiers
Feb 26, 2019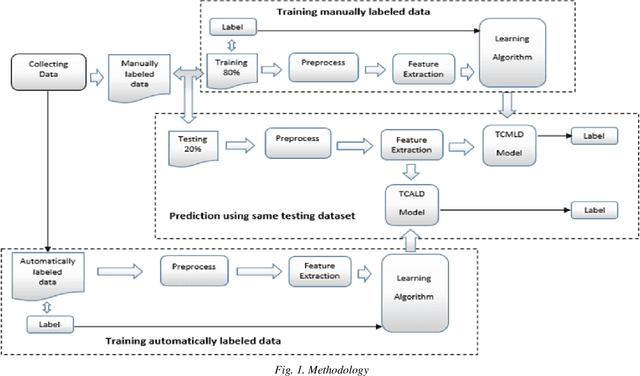
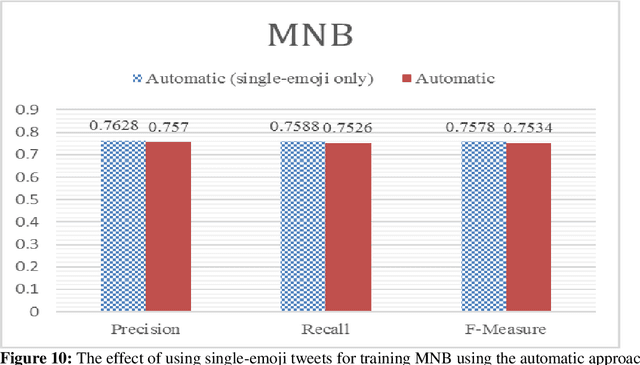
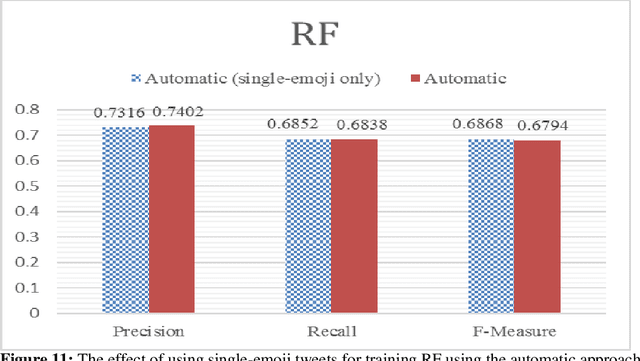
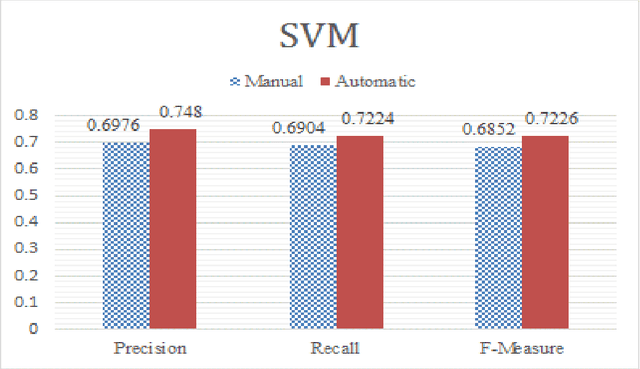
Nowadays, the automatic detection of emotions is employed by many applications in different fields like security informatics, e-learning, humor detection, targeted advertising, etc. Many of these applications focus on social media and treat this problem as a classification problem, which requires preparing training data. The typical method for annotating the training data by human experts is considered time consuming, labor intensive and sometimes prone to error. Moreover, such an approach is not easily extensible to new domains/languages since such extensions require annotating new training data. In this study, we propose a distant supervised learning approach where the training sentences are automatically annotated based on the emojis they have. Such training data would be very cheap to produce compared with the manually created training data, thus, much larger training data can be easily obtained. On the other hand, this training data would naturally have lower quality as it may contain some errors in the annotation. Nonetheless, we experimentally show that training classifiers on cheap, large and possibly erroneous data annotated using this approach leads to more accurate results compared with training the same classifiers on the more expensive, much smaller and error-free manually annotated training data. Our experiments are conducted on an in-house dataset of emotional Arabic tweets and the classifiers we consider are: Support Vector Machine (SVM), Multinomial Naive Bayes (MNB) and Random Forest (RF). In addition to experimenting with single classifiers, we also consider using an ensemble of classifiers. The results show that using an automatically annotated training data (that is only one order of magnitude larger than the manually annotated one) gives better results in almost all settings considered.
A detailed comparative study of open source deep learning frameworks
Feb 25, 2019
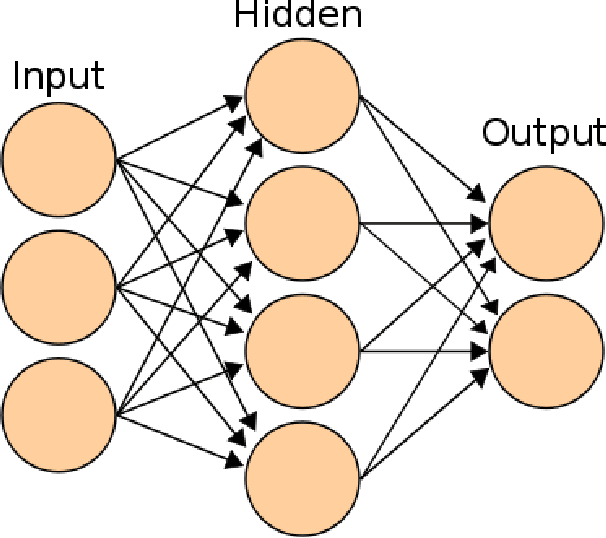
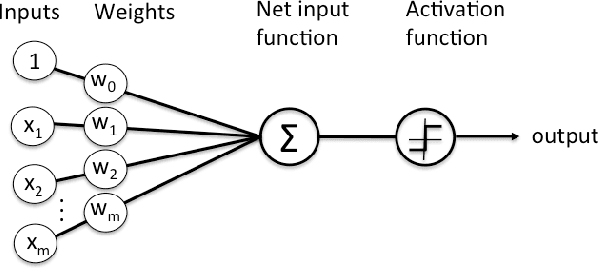

Deep Learning (DL) is one of the hottest trends in machine learning as DL approaches produced results superior to the state-of-the-art in problematic areas such as image processing and natural language processing (NLP). To foster the growth of DL, several open source frameworks appeared providing implementations of the most common DL algorithms. These frameworks vary in the algorithms they support and in the quality of their implementations. The purpose of this work is to provide a qualitative and quantitative comparison among three of the most popular and most comprehensive DL frameworks (namely Google's TensorFlow, University of Montreal's Theano and Microsoft's CNTK). The ultimate goal of this work is to help end users make an informed decision about the best DL framework that suits their needs and resources. To ensure that our study is as comprehensive as possible, we conduct several experiments using multiple benchmark datasets from different fields (image processing, NLP, etc.) and measure the performance of the frameworks' implementations of different DL algorithms. For most of our experiments, we find out that CNTK's implementations are superior to the other ones under consideration.