 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesarcasm detection and quantification in arabic tweets
Aug 03, 2021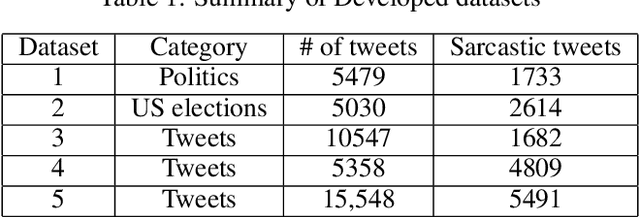
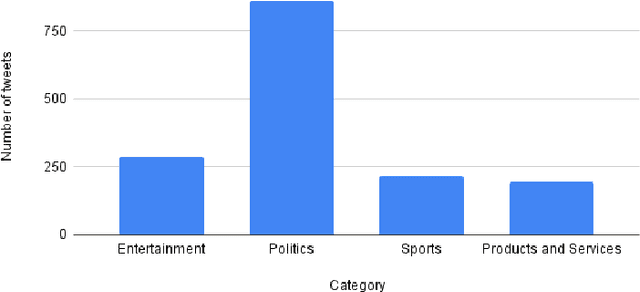
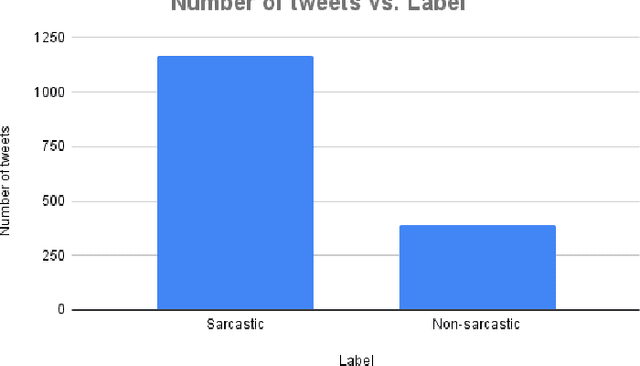

The role of predicting sarcasm in the text is known as automatic sarcasm detection. Given the prevalence and challenges of sarcasm in sentiment-bearing text, this is a critical phase in most sentiment analysis tasks. With the increasing popularity and usage of different social media platforms among users around the world, people are using sarcasm more and more in their day-to-day conversations, social media posts and tweets, and it is considered as a way for people to express their sentiment about some certain topics or issues. As a result of the increasing popularity, researchers started to focus their research endeavors on detecting sarcasm from a text in different languages especially the English language. However, the task of sarcasm detection is a challenging task due to the nature of sarcastic texts; which can be relative and significantly differs from one person to another depending on the topic, region, the user's mentality and other factors. In addition to these challenges, sarcasm detection in the Arabic language has its own challenges due to the complexity of the Arabic language, such as being morphologically rich, with many dialects that significantly vary between each other, while also being lowly resourced. In recent years, only few research attempts started tackling the task of sarcasm detection in Arabic, including creating and collecting corpora, organizing workshops and establishing baseline models. This paper intends to create a new humanly annotated Arabic corpus for sarcasm detection collected from tweets, and implementing a new approach for sarcasm detection and quantification in Arabic tweets. The annotation technique followed in this paper is unique in sarcasm detection and the proposed approach tackles the problem as a regression problem instead of classification; i.e., the model attempts to predict the level of sarcasm instead of binary classification.