 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dialect Arabic BERT for Country-Level Dialect Identification
Jul 10, 2020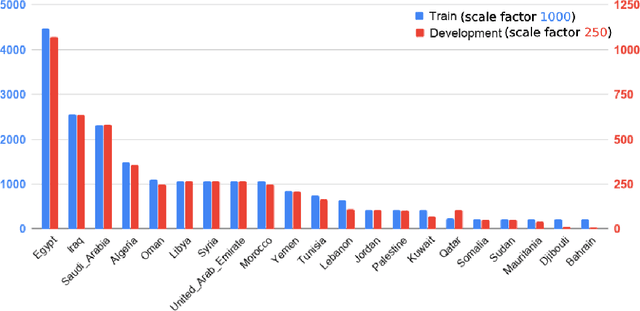
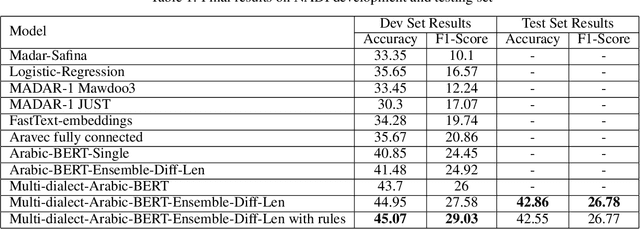
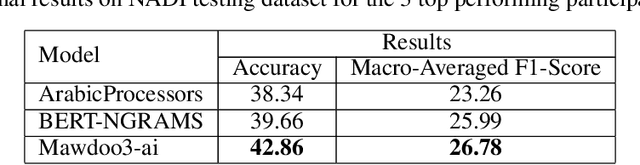
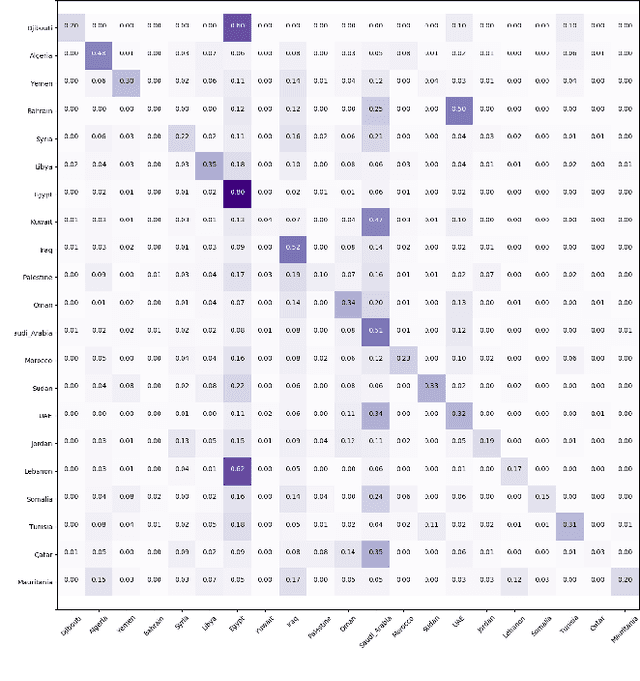
Arabic dialect identification is a complex problem for a number of inherent properties of the language itself. In this paper, we present the experiments conducted, and the models developed by our competing team, Mawdoo3 AI, along the way to achieving our winning solution to subtask 1 of the Nuanced Arabic Dialect Identification (NADI) shared task. The dialect identification subtask provides 21,000 country-level labeled tweets covering all 21 Arab countries. An unlabeled corpus of 10M tweets from the same domain is also presented by the competition organizers for optional use. Our winning solution itself came in the form of an ensemble of different training iterations of our pre-trained BERT model, which achieved a micro-averaged F1-score of 26.78% on the subtask at hand. We publicly release the pre-trained language model component of our winning solution under the name of Multi-dialect-Arabic-BERT model, for any interested researcher out there.
Tha3aroon at NSURL-2019 Task 8: Semantic Question Similarity in Arabic
Dec 28, 2019

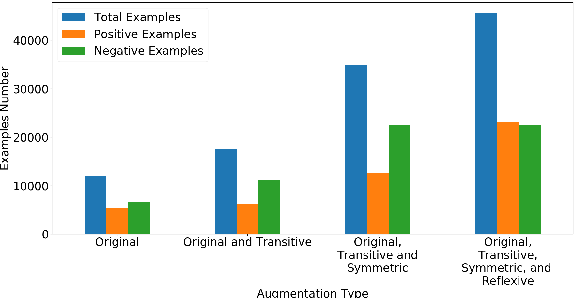
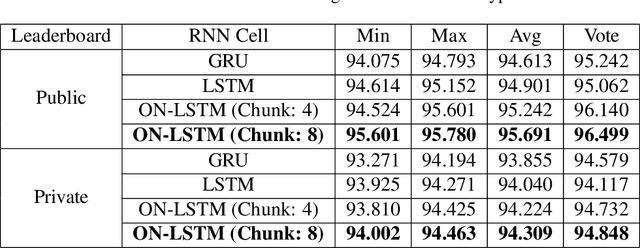
In this paper, we describe our team's effort on the semantic text question similarity task of NSURL 2019. Our top performing system utilizes several innovative data augmentation techniques to enlarge the training data. Then, it takes ELMo pre-trained contextual embeddings of the data and feeds them into an ON-LSTM network with self-attention. This results in sequence representation vectors that are used to predict the relation between the question pairs. The model is ranked in the 1st place with 96.499 F1-score (same as the second place F1-score) and the 2nd place with 94.848 F1-score (differs by 1.076 F1-score from the first place) on the public and private leaderboards, respectively.
Neural Arabic Text Diacritization: State of the Art Results and a Novel Approach for Machine Translation
Nov 08, 2019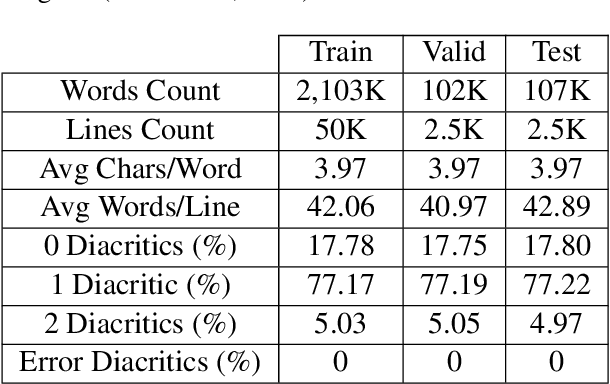

In this work, we present several deep learning models for the automatic diacritization of Arabic text. Our models are built using two main approaches, viz. Feed-Forward Neural Network (FFNN) and Recurrent Neural Network (RNN), with several enhancements such as 100-hot encoding, embeddings, Conditional Random Field (CRF) and Block-Normalized Gradient (BNG). The models are tested on the only freely available benchmark dataset and the results show that our models are either better or on par with other models, which require language-dependent post-processing steps, unlike ours. Moreover, we show that diacritics in Arabic can be used to enhance the models of NLP tasks such as Machine Translation (MT) by proposing the Translation over Diacritization (ToD) approach.
Arabic Text Diacritization Using Deep Neural Networks
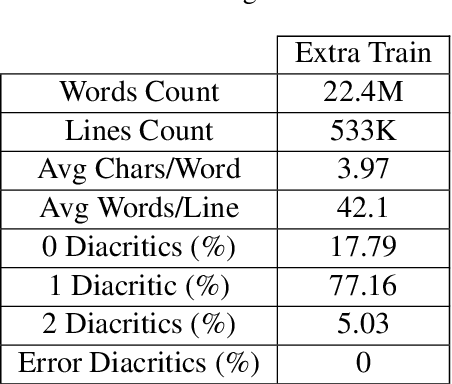
Apr 25, 2019
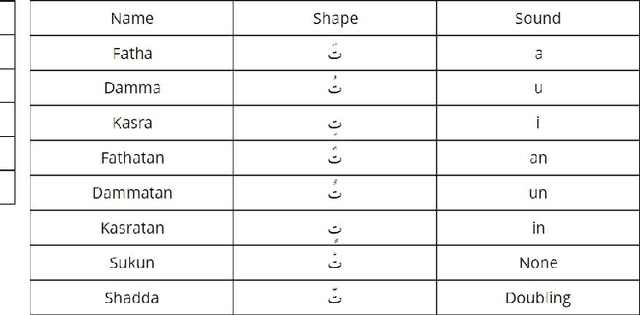


Diacritization of Arabic text is both an interesting and a challenging problem at the same time with various applications ranging from speech synthesis to helping students learning the Arabic language. Like many other tasks or problems in Arabic language processing, the weak efforts invested into this problem and the lack of available (open-source) resources hinder the progress towards solving this problem. This work provides a critical review for the currently existing systems, measures and resources for Arabic text diacritization. Moreover, it introduces a much-needed free-for-all cleaned dataset that can be easily used to benchmark any work on Arabic diacritization. Extracted from the Tashkeela Corpus, the dataset consists of 55K lines containing about 2.3M words. After constructing the dataset, existing tools and systems are tested on it. The results of the experiments show that the neural Shakkala system significantly outperforms traditional rule-based approaches and other closed-source tools with a Diacritic Error Rate (DER) of 2.88% compared with 13.78%, which the best DER for the non-neural approach (obtained by the Mishkal tool).