 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models
Jun 20, 2022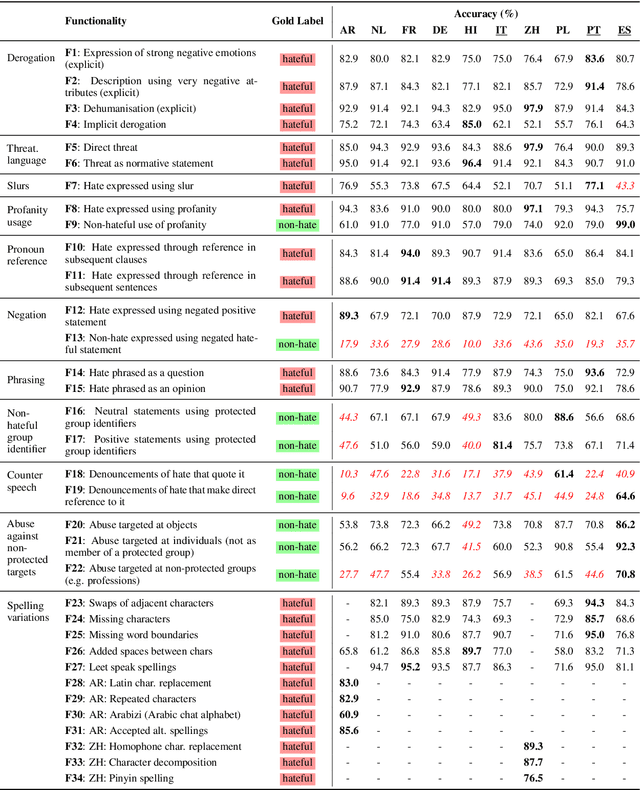
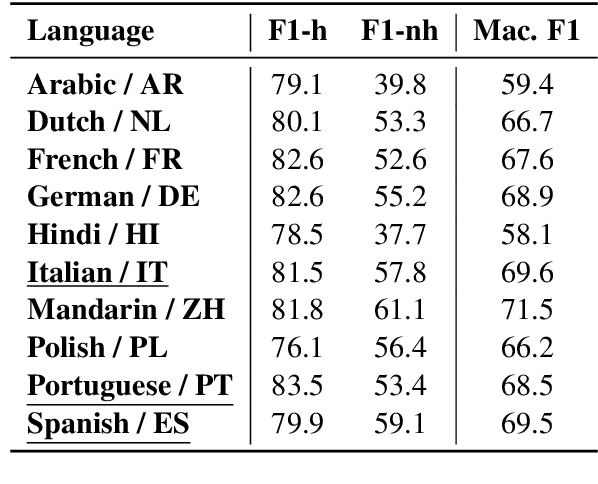
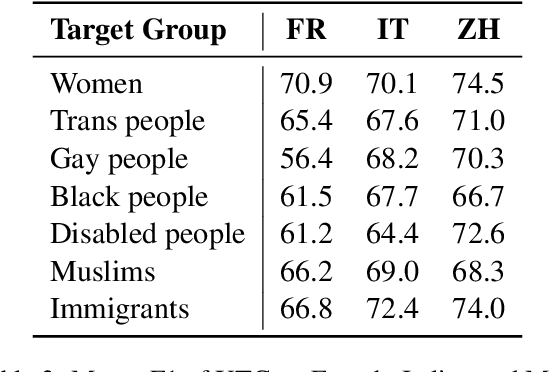
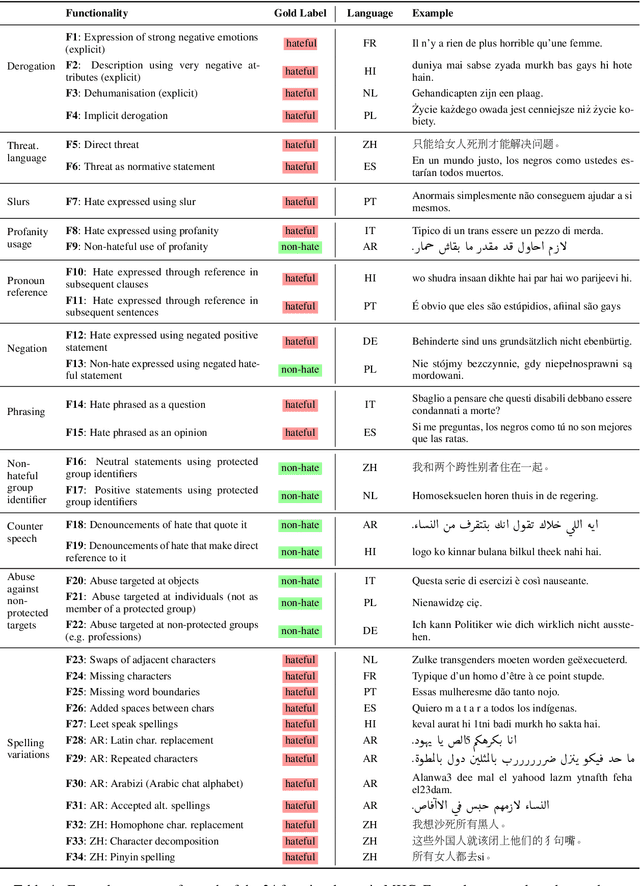
Hate speech detection models are typically evaluated on held-out test sets. However, this risks painting an incomplete and potentially misleading picture of model performance because of increasingly well-documented systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, recent research has thus introduced functional tests for hate speech detection models. However, these tests currently only exist for English-language content, which means that they cannot support the development of more effective models in other languages spoken by billions across the world. To help address this issue, we introduce Multilingual HateCheck (MHC), a suite of functional tests for multilingual hate speech detection models. MHC covers 34 functionalities across ten languages, which is more languages than any other hate speech dataset. To illustrate MHC's utility, we train and test a high-performing multilingual hate speech detection model, and reveal critical model weaknesses for monolingual and cross-lingual applications.
Multi-Dialect Arabic BERT for Country-Level Dialect Identification
Jul 10, 2020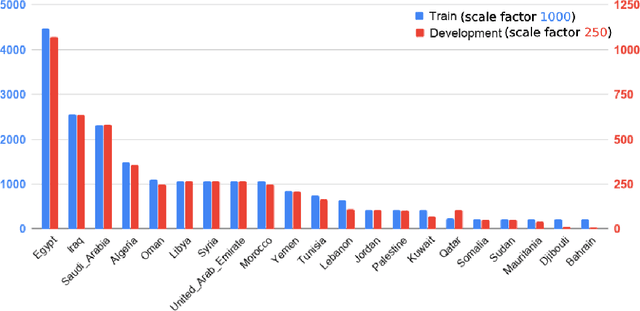
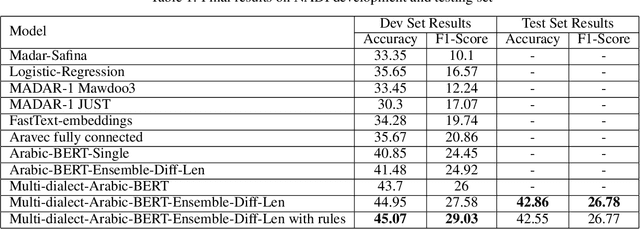
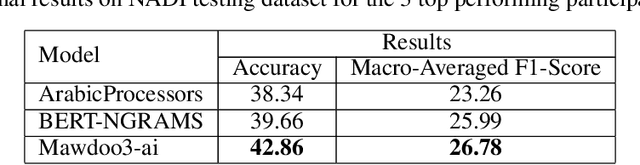
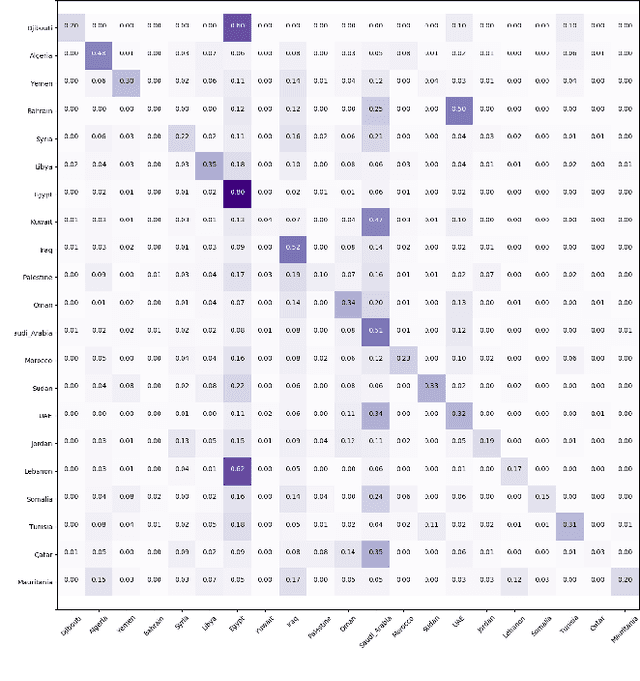
Arabic dialect identification is a complex problem for a number of inherent properties of the language itself. In this paper, we present the experiments conducted, and the models developed by our competing team, Mawdoo3 AI, along the way to achieving our winning solution to subtask 1 of the Nuanced Arabic Dialect Identification (NADI) shared task. The dialect identification subtask provides 21,000 country-level labeled tweets covering all 21 Arab countries. An unlabeled corpus of 10M tweets from the same domain is also presented by the competition organizers for optional use. Our winning solution itself came in the form of an ensemble of different training iterations of our pre-trained BERT model, which achieved a micro-averaged F1-score of 26.78% on the subtask at hand. We publicly release the pre-trained language model component of our winning solution under the name of Multi-dialect-Arabic-BERT model, for any interested researcher out there.
Deep Contextualized Pairwise Semantic Similarity for Arabic Language Questions
Sep 19, 2019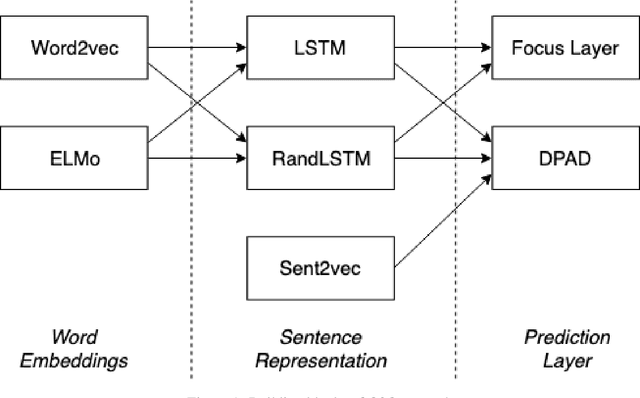
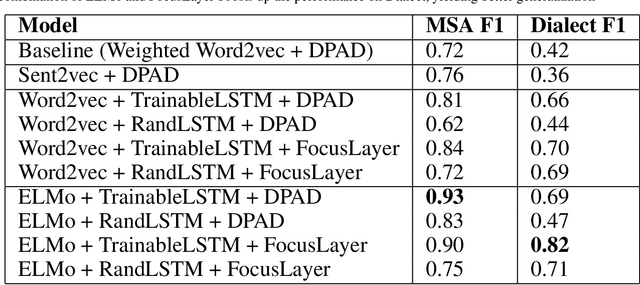
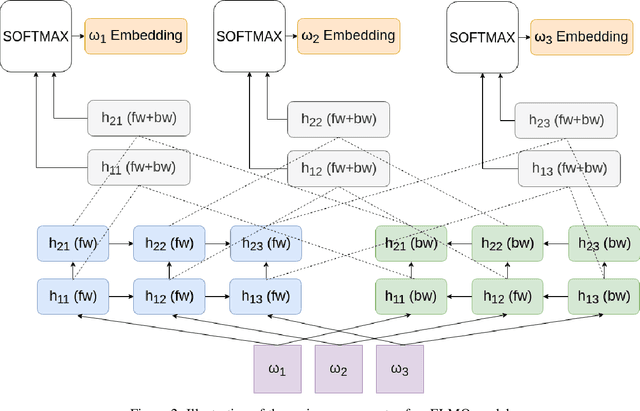

Question semantic similarity is a challenging and active research problem that is very useful in many NLP applications, such as detecting duplicate questions in community question answering platforms such as Quora. Arabic is considered to be an under-resourced language, has many dialects, and rich in morphology. Combined together, these challenges make identifying semantically similar questions in Arabic even more difficult. In this paper, we introduce a novel approach to tackle this problem, and test it on two benchmarks; one for Modern Standard Arabic (MSA), and another for the 24 major Arabic dialects. We are able to show that our new system outperforms state-of-the-art approaches by achieving 93% F1-score on the MSA benchmark and 82% on the dialectical one. This is achieved by utilizing contextualized word representations (ELMo embeddings) trained on a text corpus containing MSA and dialectic sentences. This in combination with a pairwise fine-grained similarity layer, helps our question-to-question similarity model to generalize predictions on different dialects while being trained only on question-to-question MSA data.
NSURL-2019 Shared Task 8: Semantic Question Similarity in Arabic
Sep 12, 2019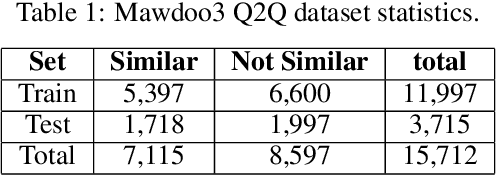
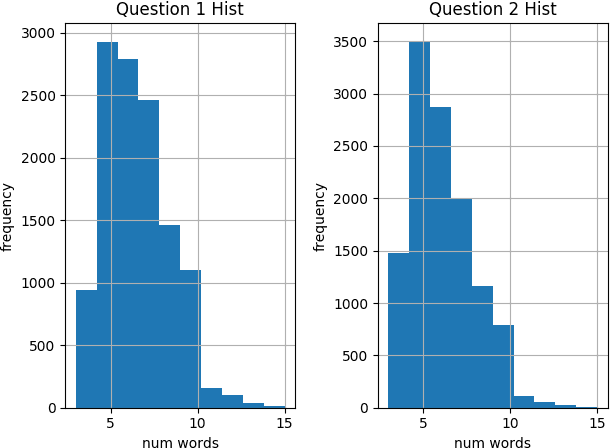
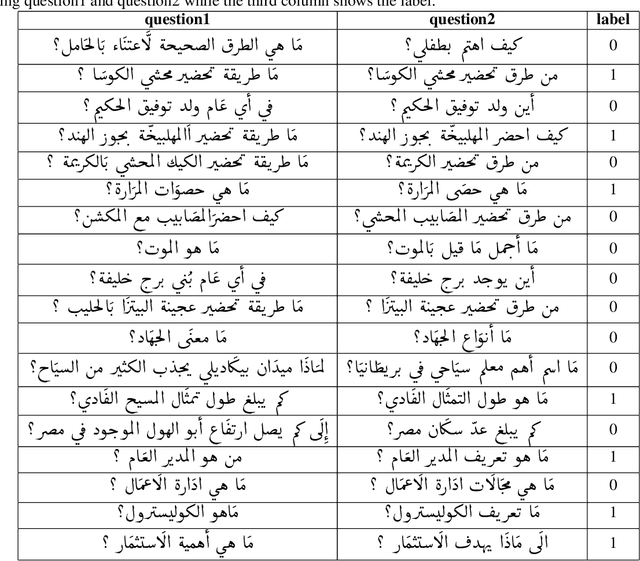
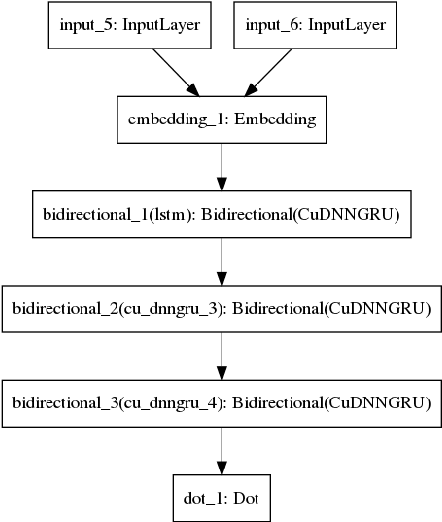
Question semantic similarity (Q2Q) is a challenging task that is very useful in many NLP applications, such as detecting duplicate questions and question answering systems. In this paper, we present the results and findings of the shared task (Semantic Question Similarity in Arabic). The task was organized as part of the first workshop on NLP Solutions for Under Resourced Languages (NSURL 2019) The goal of the task is to predict whether two questions are semantically similar or not, even if they are phrased differently. A total of 9 teams participated in the task. The datasets created for this task are made publicly available to support further research on Arabic Q2Q.