 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Contextualized Pairwise Semantic Similarity for Arabic Language Questions
Paper and Code
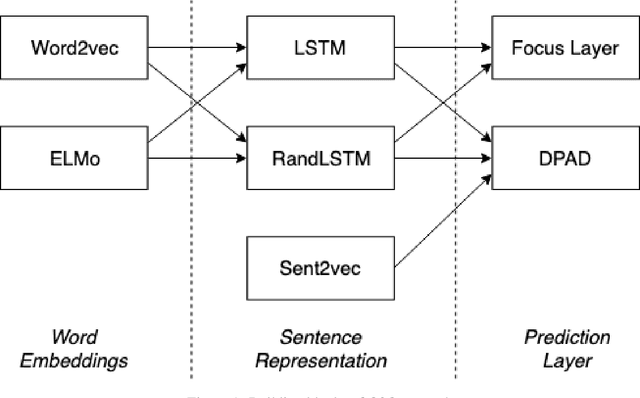
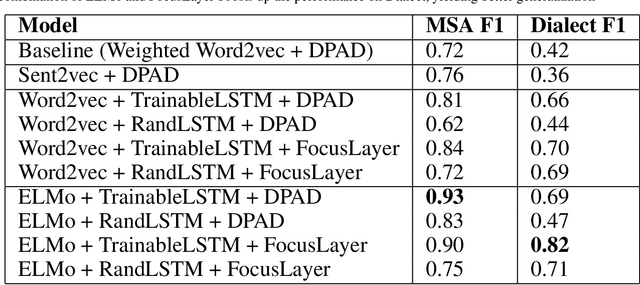
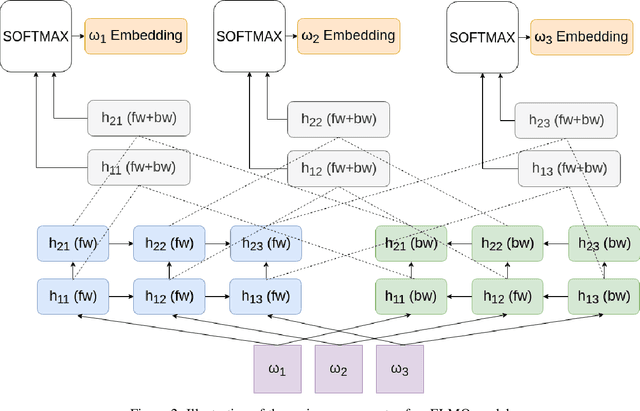

Question semantic similarity is a challenging and active research problem that is very useful in many NLP applications, such as detecting duplicate questions in community question answering platforms such as Quora. Arabic is considered to be an under-resourced language, has many dialects, and rich in morphology. Combined together, these challenges make identifying semantically similar questions in Arabic even more difficult. In this paper, we introduce a novel approach to tackle this problem, and test it on two benchmarks; one for Modern Standard Arabic (MSA), and another for the 24 major Arabic dialects. We are able to show that our new system outperforms state-of-the-art approaches by achieving 93% F1-score on the MSA benchmark and 82% on the dialectical one. This is achieved by utilizing contextualized word representations (ELMo embeddings) trained on a text corpus containing MSA and dialectic sentences. This in combination with a pairwise fine-grained similarity layer, helps our question-to-question similarity model to generalize predictions on different dialects while being trained only on question-to-question MSA data.