 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCoGNet: Recurrent Context-Guided Network for 3D MRI Prostate Segmentation
Jun 24, 2025Prostate gland segmentation from T2-weighted MRI is a critical yet challenging task in clinical prostate cancer assessment. While deep learning-based methods have significantly advanced automated segmentation, most conventional approaches-particularly 2D convolutional neural networks (CNNs)-fail to leverage inter-slice anatomical continuity, limiting their accuracy and robustness. Fully 3D models offer improved spatial coherence but require large amounts of annotated data, which is often impractical in clinical settings. To address these limitations, we propose a hybrid architecture that models MRI sequences as spatiotemporal data. Our method uses a deep, pretrained DeepLabV3 backbone to extract high-level semantic features from each MRI slice and a recurrent convolutional head, built with ConvLSTM layers, to integrate information across slices while preserving spatial structure. This combination enables context-aware segmentation with improved consistency, particularly in data-limited and noisy imaging conditions. We evaluate our method on the PROMISE12 benchmark under both clean and contrast-degraded test settings. Compared to state-of-the-art 2D and 3D segmentation models, our approach demonstrates superior performance in terms of precision, recall, Intersection over Union (IoU), and Dice Similarity Coefficient (DSC), highlighting its potential for robust clinical deployment.
A Large-scale Benchmark on Geological Fault Delineation Models: Domain Shift, Training Dynamics, Generalizability, Evaluation and Inferential Behavior
May 13, 2025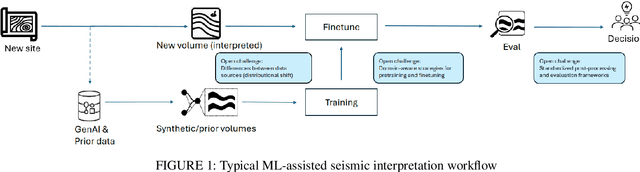
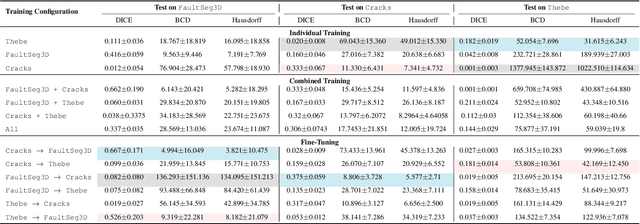
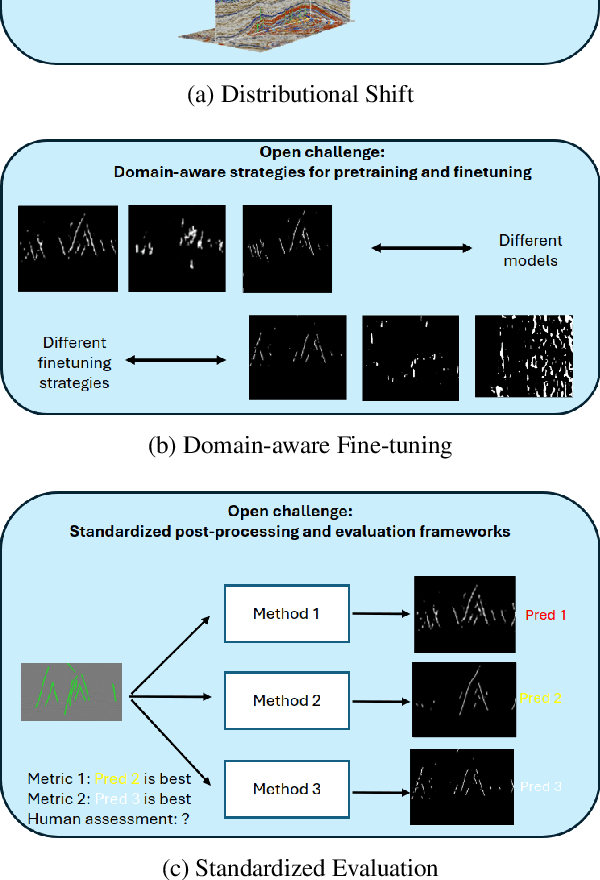
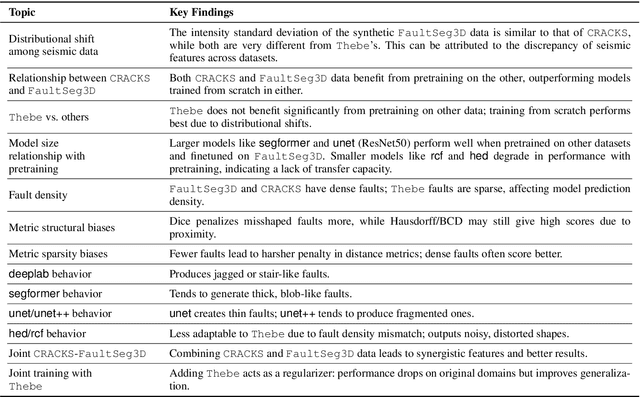
Machine learning has taken a critical role in seismic interpretation workflows, especially in fault delineation tasks. However, despite the recent proliferation of pretrained models and synthetic datasets, the field still lacks a systematic understanding of the generalizability limits of these models across seismic data representing a variety of geologic, acquisition and processing settings. Distributional shifts between different data sources, limitations in fine-tuning strategies and labeled data accessibility, and inconsistent evaluation protocols all represent major roadblocks in the deployment of reliable and robust models in real-world exploration settings. In this paper, we present the first large-scale benchmarking study explicitly designed to provide answers and guidelines for domain shift strategies in seismic interpretation. Our benchmark encompasses over $200$ models trained and evaluated on three heterogeneous datasets (synthetic and real data) including FaultSeg3D, CRACKS, and Thebe. We systematically assess pretraining, fine-tuning, and joint training strategies under varying degrees of domain shift. Our analysis highlights the fragility of current fine-tuning practices, the emergence of catastrophic forgetting, and the challenges of interpreting performance in a systematic manner. We establish a robust experimental baseline to provide insights into the tradeoffs inherent to current fault delineation workflows, and shed light on directions for developing more generalizable, interpretable and effective machine learning models for seismic interpretation. The insights and analyses reported provide a set of guidelines on the deployment of fault delineation models within seismic interpretation workflows.
CRACKS: Crowdsourcing Resources for Analysis and Categorization of Key Subsurface faults
Aug 20, 2024



Crowdsourcing annotations has created a paradigm shift in the availability of labeled data for machine learning. Availability of large datasets has accelerated progress in common knowledge applications involving visual and language data. However, specialized applications that require expert labels lag in data availability. One such application is fault segmentation in subsurface imaging. Detecting, tracking, and analyzing faults has broad societal implications in predicting fluid flows, earthquakes, and storing excess atmospheric CO$_2$. However, delineating faults with current practices is a labor-intensive activity that requires precise analysis of subsurface imaging data by geophysicists. In this paper, we propose the $\texttt{CRACKS}$ dataset to detect and segment faults in subsurface images by utilizing crowdsourced resources. We leverage Amazon Mechanical Turk to obtain fault delineations from sections of the Netherlands North Sea subsurface images from (i) $26$ novices who have no exposure to subsurface data and were shown a video describing and labeling faults, (ii) $8$ practitioners who have previously interacted and worked on subsurface data, (iii) one geophysicist to label $7636$ faults in the region. Note that all novices, practitioners, and the expert segment faults on the same subsurface volume with disagreements between and among the novices and practitioners. Additionally, each fault annotation is equipped with the confidence level of the annotator. The paper provides benchmarks on detecting and segmenting the expert labels, given the novice and practitioner labels. Additional details along with the dataset links and codes are available at $\href{https://alregib.ece.gatech.edu/cracks-crowdsourcing-resources-for-analysis-and-categorization-of-key-subsurface-faults/}{link}$.
Explainable Machine Learning for Hydrocarbon Prospect Risking
Dec 15, 2022Hydrocarbon prospect risking is a critical application in geophysics predicting well outcomes from a variety of data including geological, geophysical, and other information modalities. Traditional routines require interpreters to go through a long process to arrive at the probability of success of specific outcomes. AI has the capability to automate the process but its adoption has been limited thus far owing to a lack of transparency in the way complicated, black box models generate decisions. We demonstrate how LIME -- a model-agnostic explanation technique -- can be used to inject trust in model decisions by uncovering the model's reasoning process for individual predictions. It generates these explanations by fitting interpretable models in the local neighborhood of specific datapoints being queried. On a dataset of well outcomes and corresponding geophysical attribute data, we show how LIME can induce trust in model's decisions by revealing the decision-making process to be aligned to domain knowledge. Further, it has the potential to debug mispredictions made due to anomalous patterns in the data or faulty training datasets.
Man-recon: manifold learning for reconstruction with deep autoencoder for smart seismic interpretation
Dec 15, 2022Deep learning can extract rich data representations if provided sufficient quantities of labeled training data. For many tasks however, annotating data has significant costs in terms of time and money, owing to the high standards of subject matter expertise required, for example in medical and geophysical image interpretation tasks. Active Learning can identify the most informative training examples for the interpreter to train, leading to higher efficiency. We propose an Active learning method based on jointly learning representations for supervised and unsupervised tasks. The learned manifold structure is later utilized to identify informative training samples most dissimilar from the learned manifold from the error profiles on the unsupervised task. We verify the efficiency of the proposed method on a seismic facies segmentation dataset from the Netherlands F3 block survey, significantly outperforming contemporary methods to achieve the highest mean Intersection-Over-Union value of 0.773.
Patient Aware Active Learning for Fine-Grained OCT Classification
Jun 27, 2022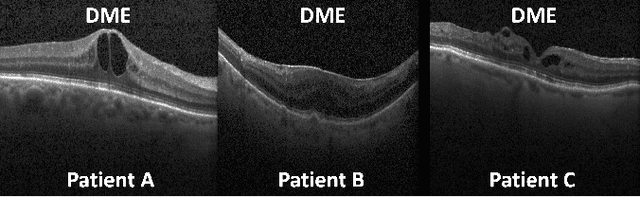

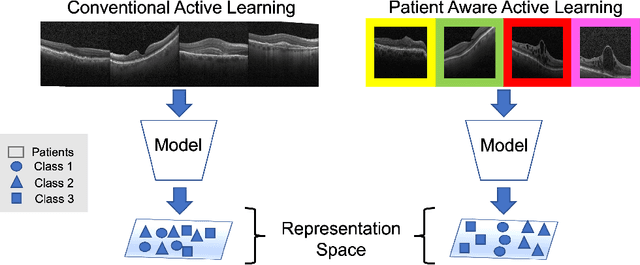
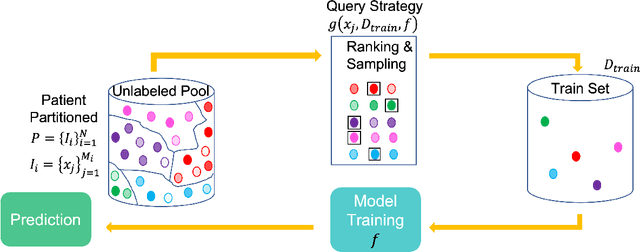
This paper considers making active learning more sensible from a medical perspective. In practice, a disease manifests itself in different forms across patient cohorts. Existing frameworks have primarily used mathematical constructs to engineer uncertainty or diversity-based methods for selecting the most informative samples. However, such algorithms do not present themselves naturally as usable by the medical community and healthcare providers. Thus, their deployment in clinical settings is very limited, if any. For this purpose, we propose a framework that incorporates clinical insights into the sample selection process of active learning that can be incorporated with existing algorithms. Our medically interpretable active learning framework captures diverse disease manifestations from patients to improve generalization performance of OCT classification. After comprehensive experiments, we report that incorporating patient insights within the active learning framework yields performance that matches or surpasses five commonly used paradigms on two architectures with a dataset having imbalanced patient distributions. Also, the framework integrates within existing medical practices and thus can be used by healthcare providers.
Spatiotemporal Modeling of Seismic Images for Acoustic Impedance Estimation
Jun 28, 2020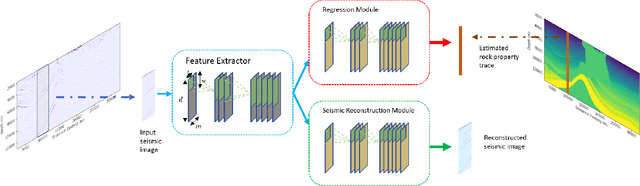
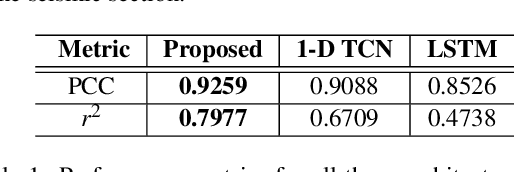
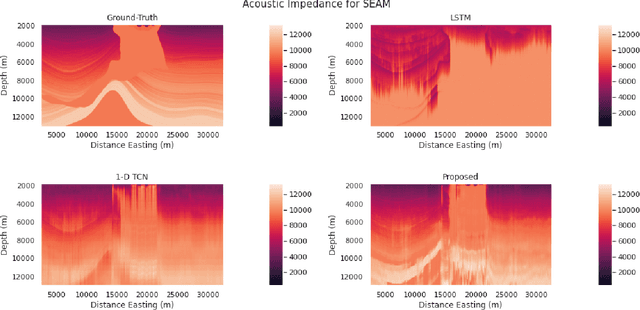
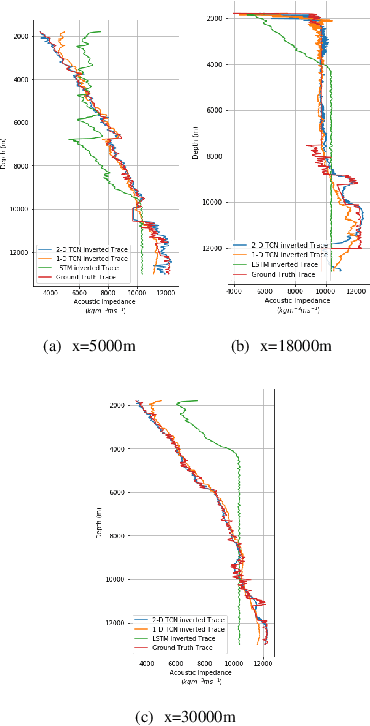
Seismic inversion refers to the process of estimating reservoir rock properties from seismic reflection data. Conventional and machine learning-based inversion workflows usually work in a trace-by-trace fashion on seismic data, utilizing little to no information from the spatial structure of seismic images. We propose a deep learning-based seismic inversion workflow that models each seismic trace not only temporally but also spatially. This utilizes information-relatedness in seismic traces in depth and spatial directions to make efficient rock property estimations. We empirically compare our proposed workflow with some other sequence modeling-based neural networks that model seismic data only temporally. Our results on the SEAM dataset demonstrate that, compared to the other architectures used in the study, the proposed workflow is able to achieve the best performance, with an average $r^{2}$ coefficient of 79.77\%.
Deep Contextualized Pairwise Semantic Similarity for Arabic Language Questions
Sep 19, 2019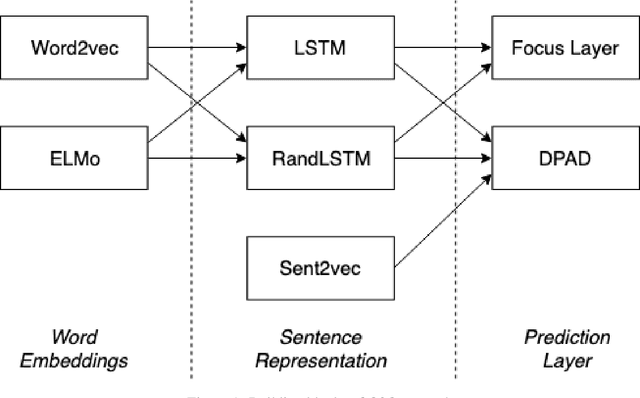
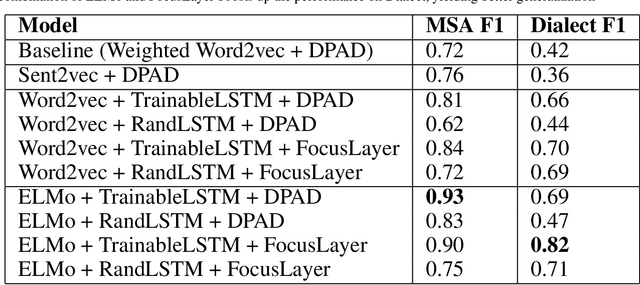
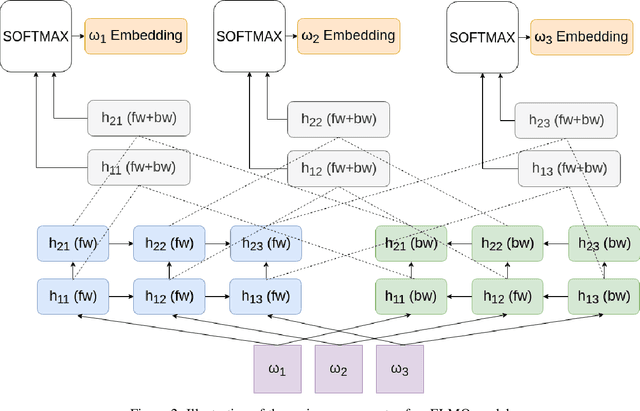

Question semantic similarity is a challenging and active research problem that is very useful in many NLP applications, such as detecting duplicate questions in community question answering platforms such as Quora. Arabic is considered to be an under-resourced language, has many dialects, and rich in morphology. Combined together, these challenges make identifying semantically similar questions in Arabic even more difficult. In this paper, we introduce a novel approach to tackle this problem, and test it on two benchmarks; one for Modern Standard Arabic (MSA), and another for the 24 major Arabic dialects. We are able to show that our new system outperforms state-of-the-art approaches by achieving 93% F1-score on the MSA benchmark and 82% on the dialectical one. This is achieved by utilizing contextualized word representations (ELMo embeddings) trained on a text corpus containing MSA and dialectic sentences. This in combination with a pairwise fine-grained similarity layer, helps our question-to-question similarity model to generalize predictions on different dialects while being trained only on question-to-question MSA data.
NSURL-2019 Shared Task 8: Semantic Question Similarity in Arabic
Sep 12, 2019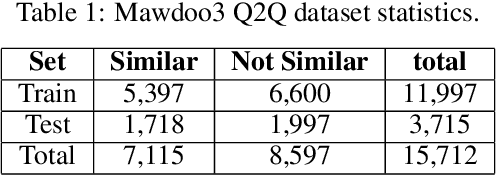
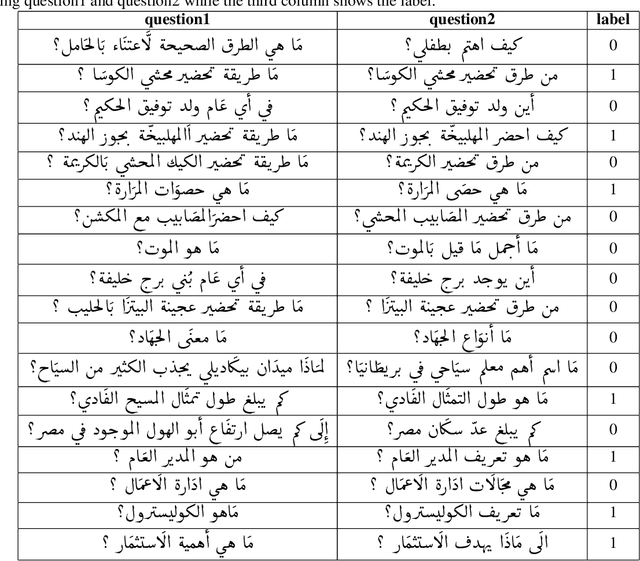
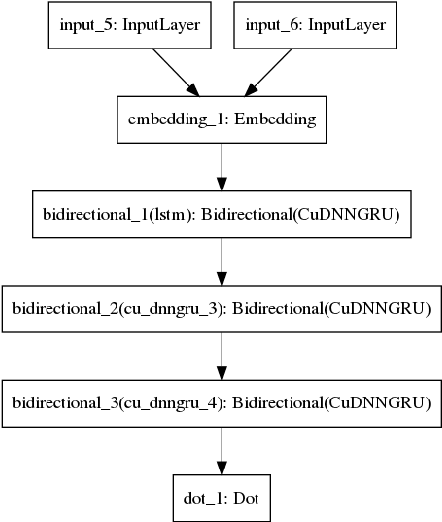
Question semantic similarity (Q2Q) is a challenging task that is very useful in many NLP applications, such as detecting duplicate questions and question answering systems. In this paper, we present the results and findings of the shared task (Semantic Question Similarity in Arabic). The task was organized as part of the first workshop on NLP Solutions for Under Resourced Languages (NSURL 2019) The goal of the task is to predict whether two questions are semantically similar or not, even if they are phrased differently. A total of 9 teams participated in the task. The datasets created for this task are made publicly available to support further research on Arabic Q2Q.