 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting Negative Flips in Active Learning using Validation Sets
Nov 16, 2024The performance of active learning algorithms can be improved in two ways. The often used and intuitive way is by reducing the overall error rate within the test set. The second way is to ensure that correct predictions are not forgotten when the training set is increased in between rounds. The former is measured by the accuracy of the model and the latter is captured in negative flips between rounds. Negative flips are samples that are correctly predicted when trained with the previous/smaller dataset and incorrectly predicted after additional samples are labeled. In this paper, we discuss improving the performance of active learning algorithms both in terms of prediction accuracy and negative flips. The first observation we make in this paper is that negative flips and overall error rates are decoupled and reducing one does not necessarily imply that the other is reduced. Our observation is important as current active learning algorithms do not consider negative flips directly and implicitly assume the opposite. The second observation is that performing targeted active learning on subsets of the unlabeled pool has a significant impact on the behavior of the active learning algorithm and influences both negative flips and prediction accuracy. We then develop ROSE - a plug-in algorithm that utilizes a small labeled validation set to restrict arbitrary active learning acquisition functions to negative flips within the unlabeled pool. We show that integrating a validation set results in a significant performance boost in terms of accuracy, negative flip rate reduction, or both.
Effective Data Selection for Seismic Interpretation through Disagreement
Jun 01, 2024This paper presents a discussion on data selection for deep learning in the field of seismic interpretation. In order to achieve a robust generalization to the target volume, it is crucial to identify the specific samples are the most informative to the training process. The selection of the training set from a target volume is a critical factor in determining the effectiveness of the deep learning algorithm for interpreting seismic volumes. This paper proposes the inclusion of interpretation disagreement as a valuable and intuitive factor in the process of selecting training sets. The development of a novel data selection framework is inspired by established practices in seismic interpretation. The framework we have developed utilizes representation shifts to effectively model interpretation disagreement within neural networks. Additionally, it incorporates the disagreement measure to enhance attention towards geologically interesting regions throughout the data selection workflow. By combining this approach with active learning, a well-known machine learning paradigm for data selection, we arrive at a comprehensive and innovative framework for training set selection in seismic interpretation. In addition, we offer a specific implementation of our proposed framework, which we have named ATLAS. This implementation serves as a means for data selection. In this study, we present the results of our comprehensive experiments, which clearly indicate that ATLAS consistently surpasses traditional active learning frameworks in the field of seismic interpretation. Our findings reveal that ATLAS achieves improvements of up to 12% in mean intersection-over-union.
Transitional Uncertainty with Layered Intermediate Predictions
May 25, 2024In this paper, we discuss feature engineering for single-pass uncertainty estimation. For accurate uncertainty estimates, neural networks must extract differences in the feature space that quantify uncertainty. This could be achieved by current single-pass approaches that maintain feature distances between data points as they traverse the network. While initial results are promising, maintaining feature distances within the network representations frequently inhibits information compression and opposes the learning objective. We study this effect theoretically and empirically to arrive at a simple conclusion: preserving feature distances in the output is beneficial when the preserved features contribute to learning the label distribution and act in opposition otherwise. We then propose Transitional Uncertainty with Layered Intermediate Predictions (TULIP) as a simple approach to address the shortcomings of current single-pass estimators. Specifically, we implement feature preservation by extracting features from intermediate representations before information is collapsed by subsequent layers. We refer to the underlying preservation mechanism as transitional feature preservation. We show that TULIP matches or outperforms current single-pass methods on standard benchmarks and in practical settings where these methods are less reliable (imbalances, complex architectures, medical modalities).
FOCAL: A Cost-Aware Video Dataset for Active Learning
Nov 17, 2023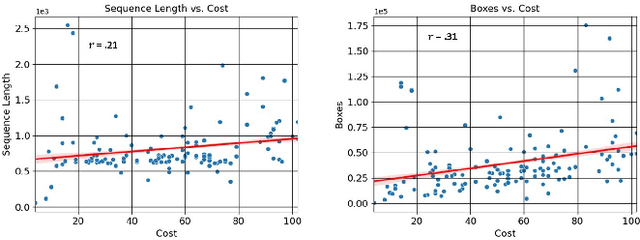
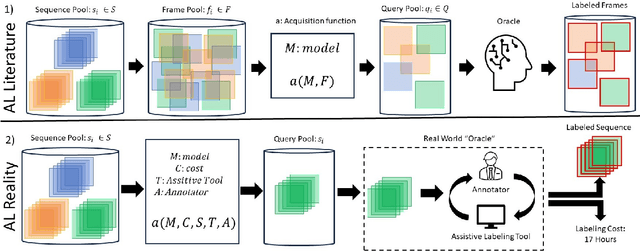
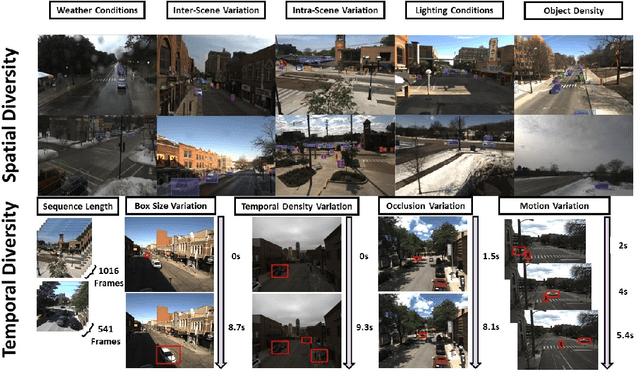
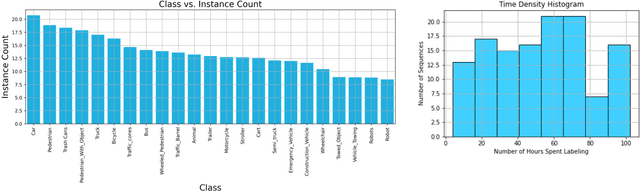
In this paper, we introduce the FOCAL (Ford-OLIVES Collaboration on Active Learning) dataset which enables the study of the impact of annotation-cost within a video active learning setting. Annotation-cost refers to the time it takes an annotator to label and quality-assure a given video sequence. A practical motivation for active learning research is to minimize annotation-cost by selectively labeling informative samples that will maximize performance within a given budget constraint. However, previous work in video active learning lacks real-time annotation labels for accurately assessing cost minimization and instead operates under the assumption that annotation-cost scales linearly with the amount of data to annotate. This assumption does not take into account a variety of real-world confounding factors that contribute to a nonlinear cost such as the effect of an assistive labeling tool and the variety of interactions within a scene such as occluded objects, weather, and motion of objects. FOCAL addresses this discrepancy by providing real annotation-cost labels for 126 video sequences across 69 unique city scenes with a variety of weather, lighting, and seasonal conditions. We also introduce a set of conformal active learning algorithms that take advantage of the sequential structure of video data in order to achieve a better trade-off between annotation-cost and performance while also reducing floating point operations (FLOPS) overhead by at least 77.67%. We show how these approaches better reflect how annotations on videos are done in practice through a sequence selection framework. We further demonstrate the advantage of these approaches by introducing two performance-cost metrics and show that the best conformal active learning method is cheaper than the best traditional active learning method by 113 hours.
Example Forgetting: A Novel Approach to Explain and Interpret Deep Neural Networks in Seismic Interpretation
Feb 24, 2023In recent years, deep neural networks have significantly impacted the seismic interpretation process. Due to the simple implementation and low interpretation costs, deep neural networks are an attractive component for the common interpretation pipeline. However, neural networks are frequently met with distrust due to their property of producing semantically incorrect outputs when exposed to sections the model was not trained on. We address this issue by explaining model behaviour and improving generalization properties through example forgetting: First, we introduce a method that effectively relates semantically malfunctioned predictions to their respectful positions within the neural network representation manifold. More concrete, our method tracks how models "forget" seismic reflections during training and establishes a connection to the decision boundary proximity of the target class. Second, we use our analysis technique to identify frequently forgotten regions within the training volume and augment the training set with state-of-the-art style transfer techniques from computer vision. We show that our method improves the segmentation performance on underrepresented classes while significantly reducing the forgotten regions in the F3 volume in the Netherlands.
Gaussian Switch Sampling: A Second Order Approach to Active Learning
Feb 16, 2023In active learning, acquisition functions define informativeness directly on the representation position within the model manifold. However, for most machine learning models (in particular neural networks) this representation is not fixed due to the training pool fluctuations in between active learning rounds. Therefore, several popular strategies are sensitive to experiment parameters (e.g. architecture) and do not consider model robustness to out-of-distribution settings. To alleviate this issue, we propose a grounded second-order definition of information content and sample importance within the context of active learning. Specifically, we define importance by how often a neural network "forgets" a sample during training - artifacts of second order representation shifts. We show that our definition produces highly accurate importance scores even when the model representations are constrained by the lack of training data. Motivated by our analysis, we develop Gaussian Switch Sampling (GauSS). We show that GauSS is setup agnostic and robust to anomalous distributions with exhaustive experiments on three in-distribution benchmarks, three out-of-distribution benchmarks, and three different architectures. We report an improvement of up to 5% when compared against four popular query strategies.
Forgetful Active Learning with Switch Events: Efficient Sampling for Out-of-Distribution Data
Jan 12, 2023This paper considers deep out-of-distribution active learning. In practice, fully trained neural networks interact randomly with out-of-distribution (OOD) inputs and map aberrant samples randomly within the model representation space. Since data representations are direct manifestations of the training distribution, the data selection process plays a crucial role in outlier robustness. For paradigms such as active learning, this is especially challenging since protocols must not only improve performance on the training distribution most effectively but further render a robust representation space. However, existing strategies directly base the data selection on the data representation of the unlabeled data which is random for OOD samples by definition. For this purpose, we introduce forgetful active learning with switch events (FALSE) - a novel active learning protocol for out-of-distribution active learning. Instead of defining sample importance on the data representation directly, we formulate "informativeness" with learning difficulty during training. Specifically, we approximate how often the network "forgets" unlabeled samples and query the most "forgotten" samples for annotation. We report up to 4.5\% accuracy improvements in over 270 experiments, including four commonly used protocols, two OOD benchmarks, one in-distribution benchmark, and three different architectures.
Explaining Deep Models through Forgettable Learning Dynamics
Jan 10, 2023Even though deep neural networks have shown tremendous success in countless applications, explaining model behaviour or predictions is an open research problem. In this paper, we address this issue by employing a simple yet effective method by analysing the learning dynamics of deep neural networks in semantic segmentation tasks. Specifically, we visualize the learning behaviour during training by tracking how often samples are learned and forgotten in subsequent training epochs. This further allows us to derive important information about the proximity to the class decision boundary and identify regions that pose a particular challenge to the model. Inspired by this phenomenon, we present a novel segmentation method that actively uses this information to alter the data representation within the model by increasing the variety of difficult regions. Finally, we show that our method consistently reduces the amount of regions that are forgotten frequently. We further evaluate our method in light of the segmentation performance.
Patient Aware Active Learning for Fine-Grained OCT Classification
Jun 27, 2022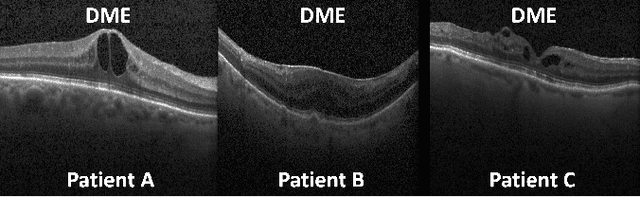

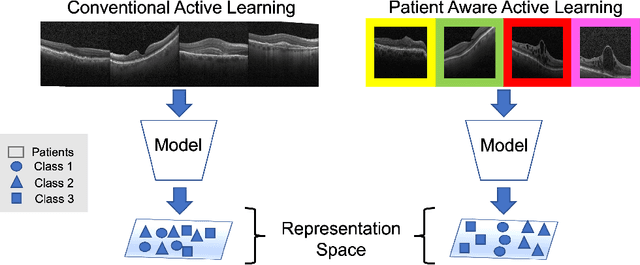
This paper considers making active learning more sensible from a medical perspective. In practice, a disease manifests itself in different forms across patient cohorts. Existing frameworks have primarily used mathematical constructs to engineer uncertainty or diversity-based methods for selecting the most informative samples. However, such algorithms do not present themselves naturally as usable by the medical community and healthcare providers. Thus, their deployment in clinical settings is very limited, if any. For this purpose, we propose a framework that incorporates clinical insights into the sample selection process of active learning that can be incorporated with existing algorithms. Our medically interpretable active learning framework captures diverse disease manifestations from patients to improve generalization performance of OCT classification. After comprehensive experiments, we report that incorporating patient insights within the active learning framework yields performance that matches or surpasses five commonly used paradigms on two architectures with a dataset having imbalanced patient distributions. Also, the framework integrates within existing medical practices and thus can be used by healthcare providers.