 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAVERO: Unlocking Fine-Grained Semantics for Video-Language Compositionality
Aug 18, 2024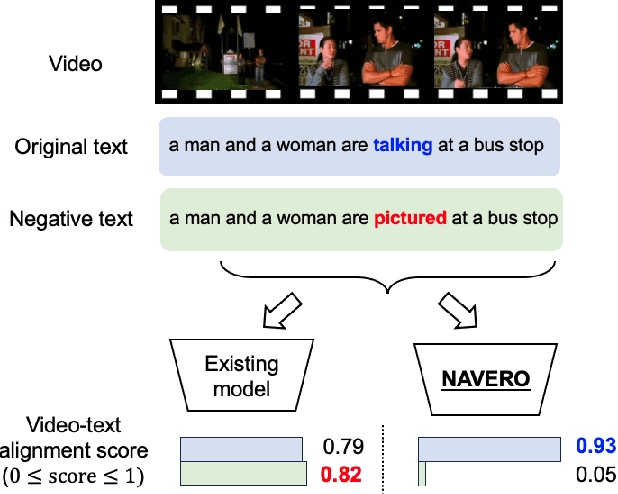
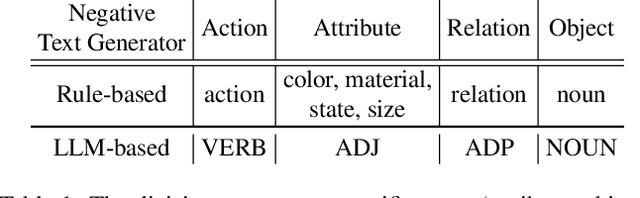
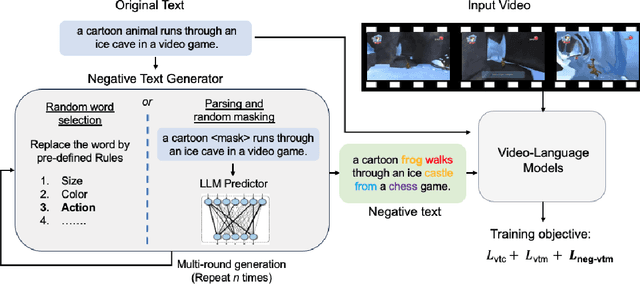
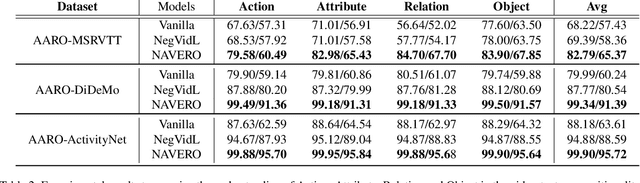
We study the capability of Video-Language (VidL) models in understanding compositions between objects, attributes, actions and their relations. Composition understanding becomes particularly challenging for video data since the compositional relations rapidly change over time in videos. We first build a benchmark named AARO to evaluate composition understanding related to actions on top of spatial concepts. The benchmark is constructed by generating negative texts with incorrect action descriptions for a given video and the model is expected to pair a positive text with its corresponding video. Furthermore, we propose a training method called NAVERO which utilizes video-text data augmented with negative texts to enhance composition understanding. We also develop a negative-augmented visual-language matching loss which is used explicitly to benefit from the generated negative text. We compare NAVERO with other state-of-the-art methods in terms of compositional understanding as well as video-text retrieval performance. NAVERO achieves significant improvement over other methods for both video-language and image-language composition understanding, while maintaining strong performance on traditional text-video retrieval tasks.
Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge
May 30, 2023

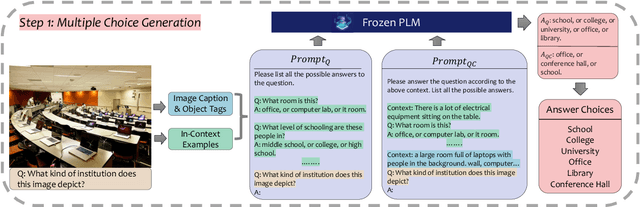
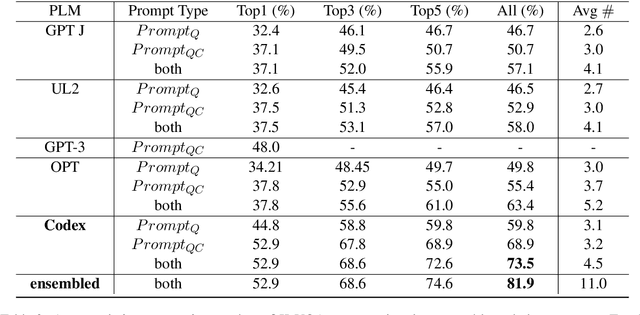
The open-ended Visual Question Answering (VQA) task requires AI models to jointly reason over visual and natural language inputs using world knowledge. Recently, pre-trained Language Models (PLM) such as GPT-3 have been applied to the task and shown to be powerful world knowledge sources. However, these methods suffer from low knowledge coverage caused by PLM bias -- the tendency to generate certain tokens over other tokens regardless of prompt changes, and high dependency on the PLM quality -- only models using GPT-3 can achieve the best result. To address the aforementioned challenges, we propose RASO: a new VQA pipeline that deploys a generate-then-select strategy guided by world knowledge for the first time. Rather than following the de facto standard to train a multi-modal model that directly generates the VQA answer, RASO first adopts PLM to generate all the possible answers, and then trains a lightweight answer selection model for the correct answer. As proved in our analysis, RASO expands the knowledge coverage from in-domain training data by a large margin. We provide extensive experimentation and show the effectiveness of our pipeline by advancing the state-of-the-art by 4.1% on OK-VQA, without additional computation cost. Code and models are released at http://cogcomp.org/page/publication_view/1010
Masked Vision and Language Modeling for Multi-modal Representation Learning
Aug 03, 2022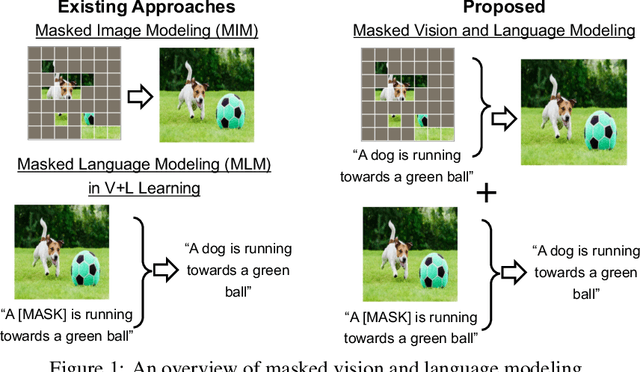
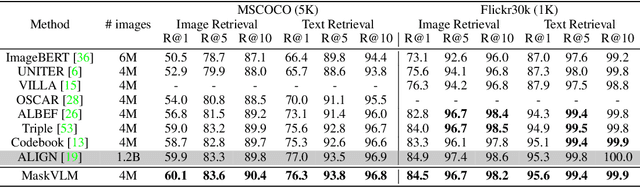
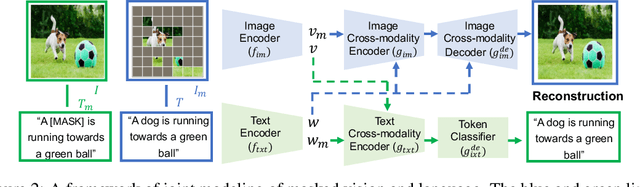
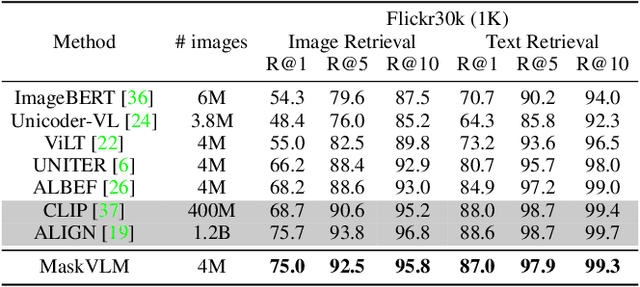
In this paper, we study how to use masked signal modeling in vision and language (V+L) representation learning. Instead of developing masked language modeling (MLM) and masked image modeling (MIM) independently, we propose to build joint masked vision and language modeling, where the masked signal of one modality is reconstructed with the help from another modality. This is motivated by the nature of image-text paired data that both of the image and the text convey almost the same information but in different formats. The masked signal reconstruction of one modality conditioned on another modality can also implicitly learn cross-modal alignment between language tokens and image patches. Our experiments on various V+L tasks show that the proposed method not only achieves state-of-the-art performances by using a large amount of data, but also outperforms the other competitors by a significant margin in the regimes of limited training data.
Patient Aware Active Learning for Fine-Grained OCT Classification
Jun 27, 2022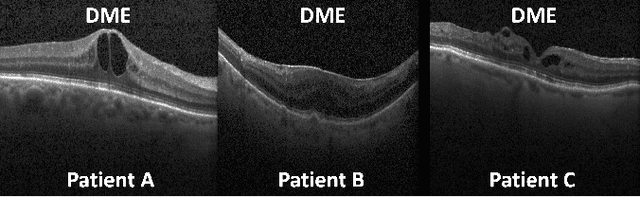

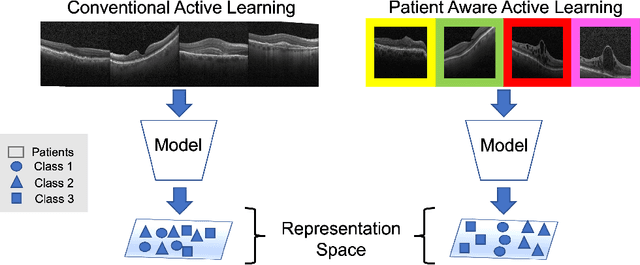
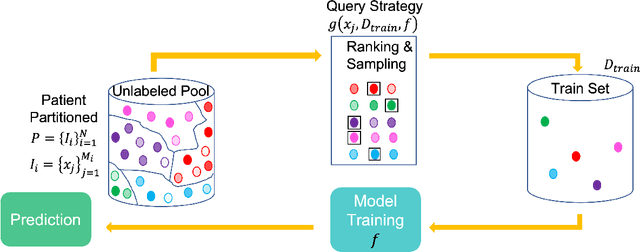
This paper considers making active learning more sensible from a medical perspective. In practice, a disease manifests itself in different forms across patient cohorts. Existing frameworks have primarily used mathematical constructs to engineer uncertainty or diversity-based methods for selecting the most informative samples. However, such algorithms do not present themselves naturally as usable by the medical community and healthcare providers. Thus, their deployment in clinical settings is very limited, if any. For this purpose, we propose a framework that incorporates clinical insights into the sample selection process of active learning that can be incorporated with existing algorithms. Our medically interpretable active learning framework captures diverse disease manifestations from patients to improve generalization performance of OCT classification. After comprehensive experiments, we report that incorporating patient insights within the active learning framework yields performance that matches or surpasses five commonly used paradigms on two architectures with a dataset having imbalanced patient distributions. Also, the framework integrates within existing medical practices and thus can be used by healthcare providers.
X-DETR: A Versatile Architecture for Instance-wise Vision-Language Tasks
Apr 12, 2022


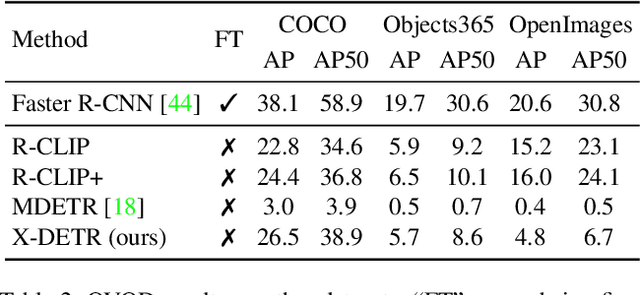
In this paper, we study the challenging instance-wise vision-language tasks, where the free-form language is required to align with the objects instead of the whole image. To address these tasks, we propose X-DETR, whose architecture has three major components: an object detector, a language encoder, and vision-language alignment. The vision and language streams are independent until the end and they are aligned using an efficient dot-product operation. The whole network is trained end-to-end, such that the detector is optimized for the vision-language tasks instead of an off-the-shelf component. To overcome the limited size of paired object-language annotations, we leverage other weak types of supervision to expand the knowledge coverage. This simple yet effective architecture of X-DETR shows good accuracy and fast speeds for multiple instance-wise vision-language tasks, e.g., 16.4 AP on LVIS detection of 1.2K categories at ~20 frames per second without using any LVIS annotation during training.
A Gating Model for Bias Calibration in Generalized Zero-shot Learning
Mar 08, 2022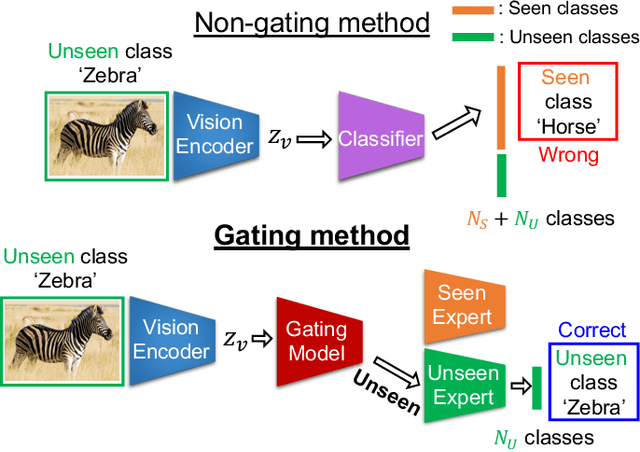
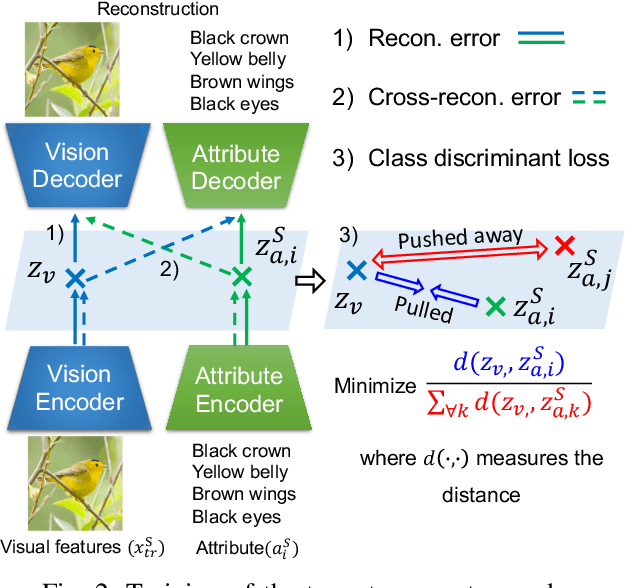
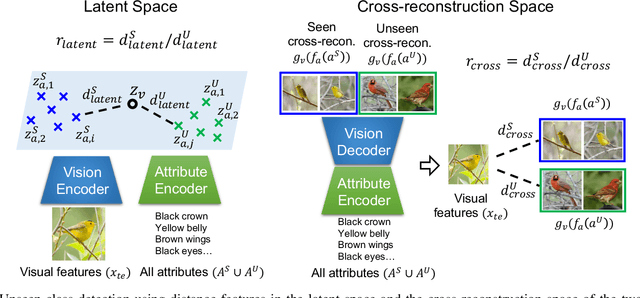

Generalized zero-shot learning (GZSL) aims at training a model that can generalize to unseen class data by only using auxiliary information. One of the main challenges in GZSL is a biased model prediction toward seen classes caused by overfitting on only available seen class data during training. To overcome this issue, we propose a two-stream autoencoder-based gating model for GZSL. Our gating model predicts whether the query data is from seen classes or unseen classes, and utilizes separate seen and unseen experts to predict the class independently from each other. This framework avoids comparing the biased prediction scores for seen classes with the prediction scores for unseen classes. In particular, we measure the distance between visual and attribute representations in the latent space and the cross-reconstruction space of the autoencoder. These distances are utilized as complementary features to characterize unseen classes at different levels of data abstraction. Also, the two-stream autoencoder works as a unified framework for the gating model and the unseen expert, which makes the proposed method computationally efficient. We validate our proposed method in four benchmark image recognition datasets. In comparison with other state-of-the-art methods, we achieve the best harmonic mean accuracy in SUN and AWA2, and the second best in CUB and AWA1. Furthermore, our base model requires at least 20% less number of model parameters than state-of-the-art methods relying on generative models.
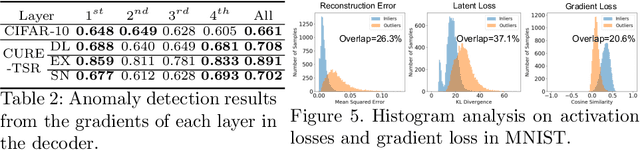
Novelty Detection Through Model-Based Characterization of Neural Networks
Aug 13, 2020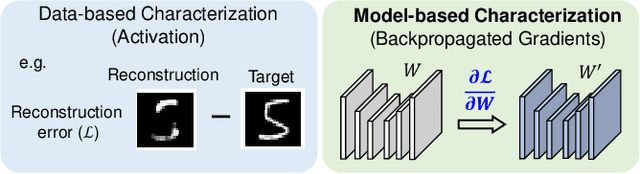
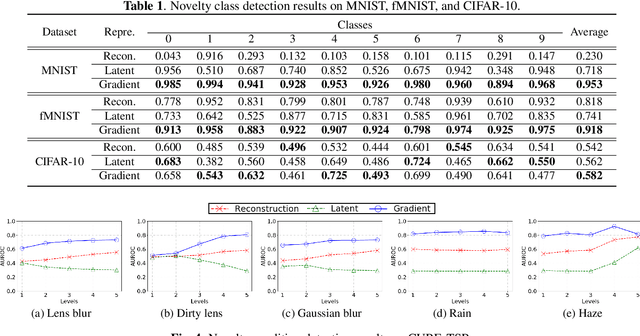
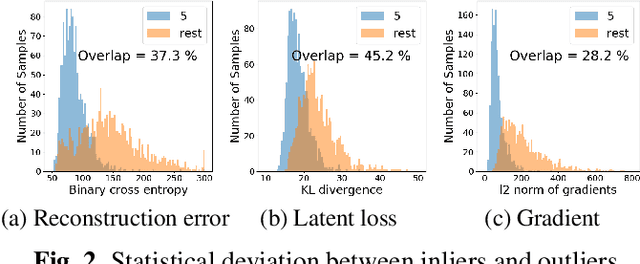
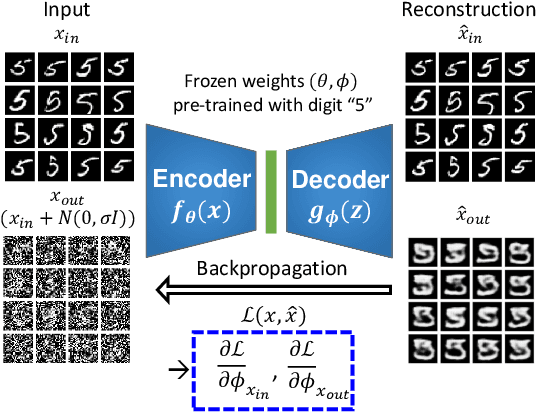
In this paper, we propose a model-based characterization of neural networks to detect novel input types and conditions. Novelty detection is crucial to identify abnormal inputs that can significantly degrade the performance of machine learning algorithms. Majority of existing studies have focused on activation-based representations to detect abnormal inputs, which limits the characterization of abnormality from a data perspective. However, a model perspective can also be informative in terms of the novelties and abnormalities. To articulate the significance of the model perspective in novelty detection, we utilize backpropagated gradients. We conduct a comprehensive analysis to compare the representation capability of gradients with that of activation and show that the gradients outperform the activation in novel class and condition detection. We validate our approach using four image recognition datasets including MNIST, Fashion-MNIST, CIFAR-10, and CURE-TSR. We achieve a significant improvement on all four datasets with an average AUROC of 0.953, 0.918, 0.582, and 0.746, respectively.
Contrastive Explanations in Neural Networks
Aug 01, 2020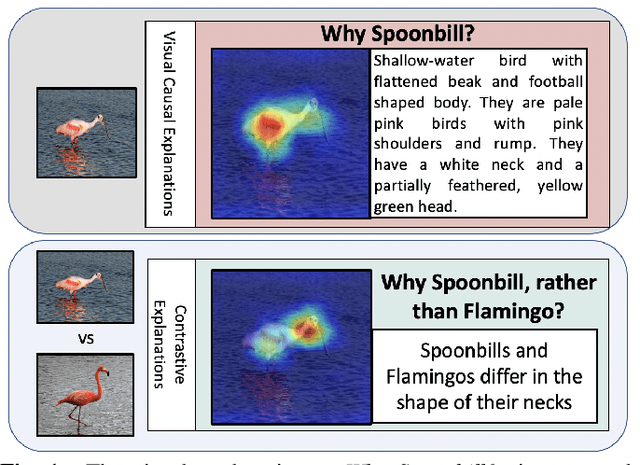
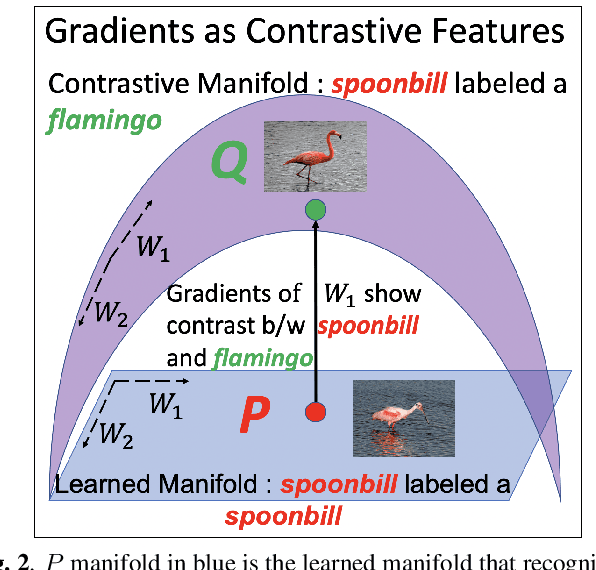
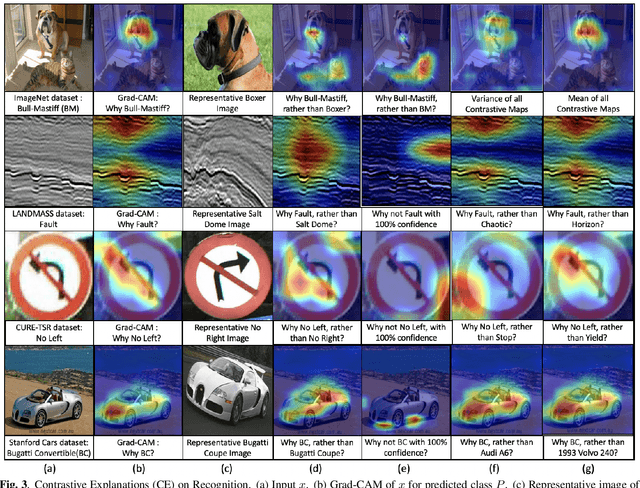

Visual explanations are logical arguments based on visual features that justify the predictions made by neural networks. Current modes of visual explanations answer questions of the form $`Why \text{ } P?'$. These $Why$ questions operate under broad contexts thereby providing answers that are irrelevant in some cases. We propose to constrain these $Why$ questions based on some context $Q$ so that our explanations answer contrastive questions of the form $`Why \text{ } P, \text{} rather \text{ } than \text{ } Q?'$. In this paper, we formalize the structure of contrastive visual explanations for neural networks. We define contrast based on neural networks and propose a methodology to extract defined contrasts. We then use the extracted contrasts as a plug-in on top of existing $`Why \text{ } P?'$ techniques, specifically Grad-CAM. We demonstrate their value in analyzing both networks and data in applications of large-scale recognition, fine-grained recognition, subsurface seismic analysis, and image quality assessment.
Backpropagated Gradient Representations for Anomaly Detection
Jul 18, 2020
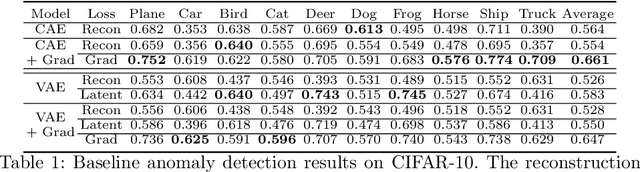
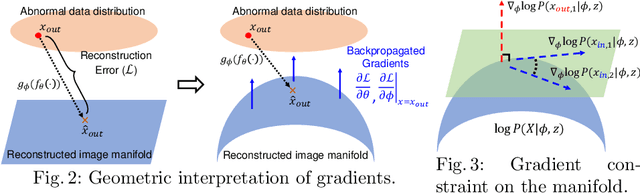
Learning representations that clearly distinguish between normal and abnormal data is key to the success of anomaly detection. Most of existing anomaly detection algorithms use activation representations from forward propagation while not exploiting gradients from backpropagation to characterize data. Gradients capture model updates required to represent data. Anomalies require more drastic model updates to fully represent them compared to normal data. Hence, we propose the utilization of backpropagated gradients as representations to characterize model behavior on anomalies and, consequently, detect such anomalies. We show that the proposed method using gradient-based representations achieves state-of-the-art anomaly detection performance in benchmark image recognition datasets. Also, we highlight the computational efficiency and the simplicity of the proposed method in comparison with other state-of-the-art methods relying on adversarial networks or autoregressive models, which require at least 27 times more model parameters than the proposed method.
Distorted Representation Space Characterization Through Backpropagated Gradients
Aug 27, 2019

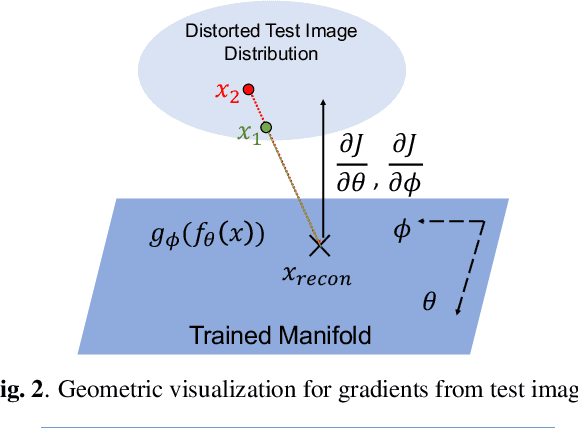
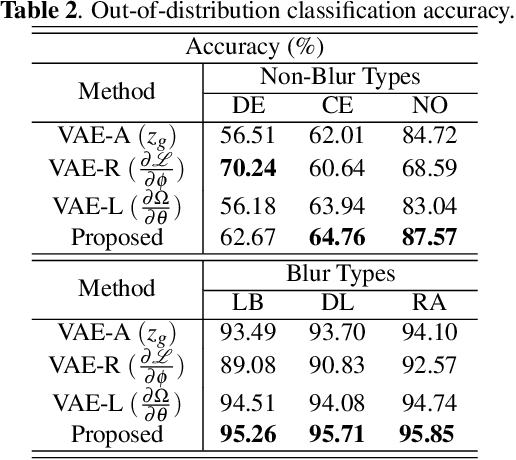
In this paper, we utilize weight gradients from backpropagation to characterize the representation space learned by deep learning algorithms. We demonstrate the utility of such gradients in applications including perceptual image quality assessment and out-of-distribution classification. The applications are chosen to validate the effectiveness of gradients as features when the test image distribution is distorted from the train image distribution. In both applications, the proposed gradient based features outperform activation features. In image quality assessment, the proposed approach is compared with other state of the art approaches and is generally the top performing method on TID 2013 and MULTI-LIVE databases in terms of accuracy, consistency, linearity, and monotonic behavior. Finally, we analyze the effect of regularization on gradients using CURE-TSR dataset for out-of-distribution classification.