 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAVERO: Unlocking Fine-Grained Semantics for Video-Language Compositionality
Aug 18, 2024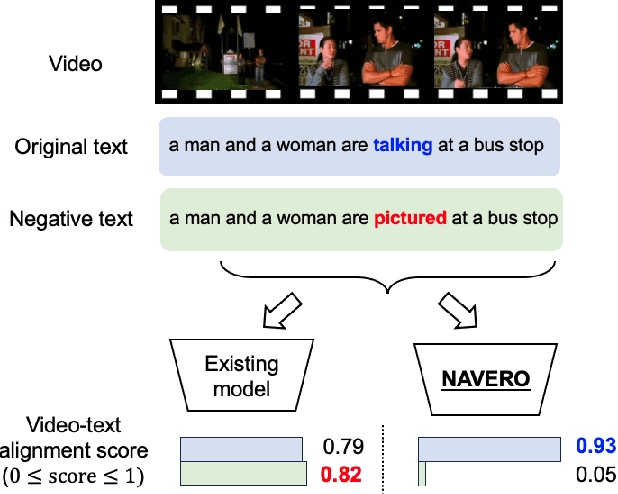
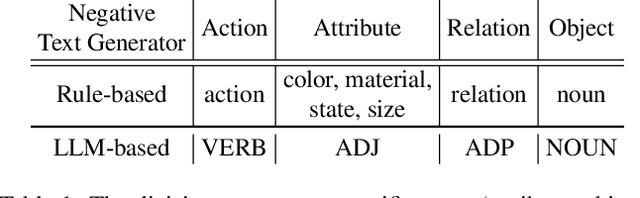
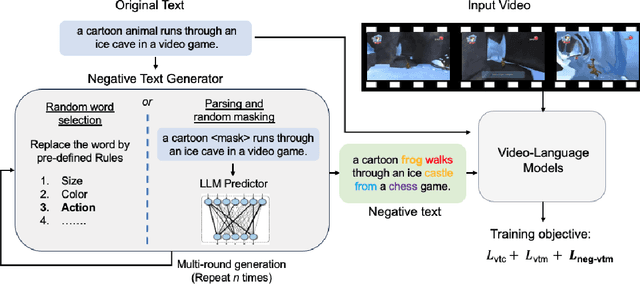
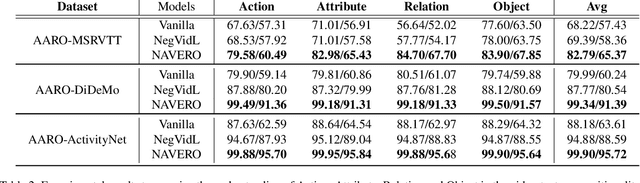
We study the capability of Video-Language (VidL) models in understanding compositions between objects, attributes, actions and their relations. Composition understanding becomes particularly challenging for video data since the compositional relations rapidly change over time in videos. We first build a benchmark named AARO to evaluate composition understanding related to actions on top of spatial concepts. The benchmark is constructed by generating negative texts with incorrect action descriptions for a given video and the model is expected to pair a positive text with its corresponding video. Furthermore, we propose a training method called NAVERO which utilizes video-text data augmented with negative texts to enhance composition understanding. We also develop a negative-augmented visual-language matching loss which is used explicitly to benefit from the generated negative text. We compare NAVERO with other state-of-the-art methods in terms of compositional understanding as well as video-text retrieval performance. NAVERO achieves significant improvement over other methods for both video-language and image-language composition understanding, while maintaining strong performance on traditional text-video retrieval tasks.