 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Explanations in Neural Networks
Paper and Code
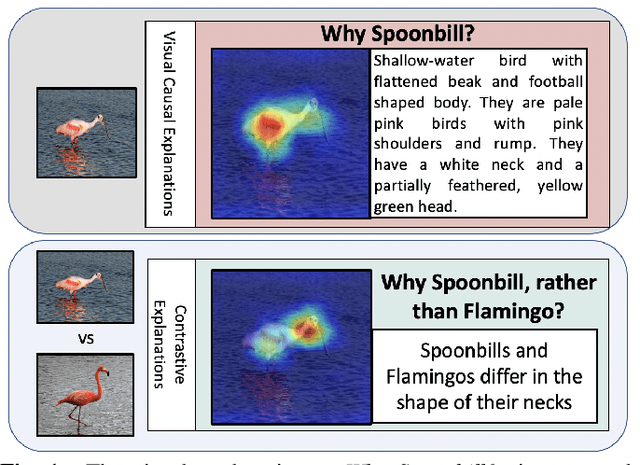
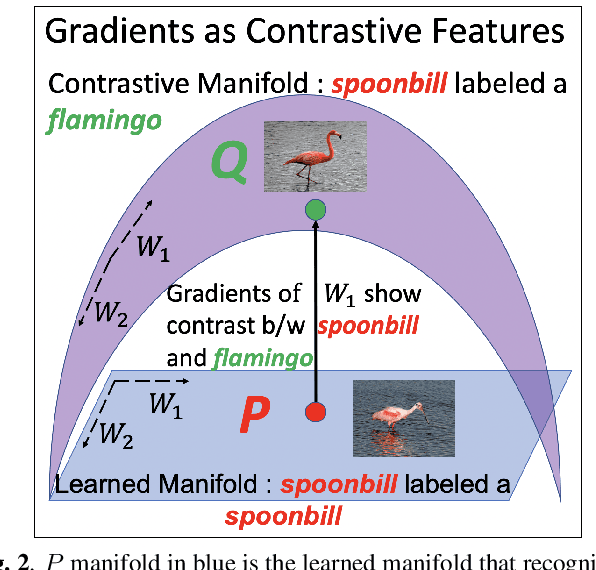
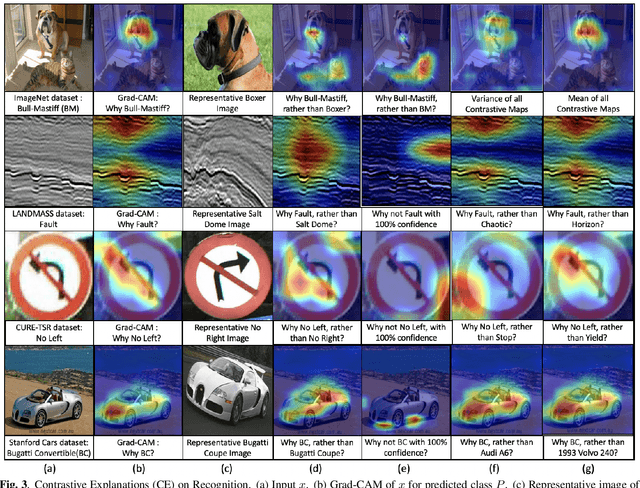

Visual explanations are logical arguments based on visual features that justify the predictions made by neural networks. Current modes of visual explanations answer questions of the form $`Why \text{ } P?'$. These $Why$ questions operate under broad contexts thereby providing answers that are irrelevant in some cases. We propose to constrain these $Why$ questions based on some context $Q$ so that our explanations answer contrastive questions of the form $`Why \text{ } P, \text{} rather \text{ } than \text{ } Q?'$. In this paper, we formalize the structure of contrastive visual explanations for neural networks. We define contrast based on neural networks and propose a methodology to extract defined contrasts. We then use the extracted contrasts as a plug-in on top of existing $`Why \text{ } P?'$ techniques, specifically Grad-CAM. We demonstrate their value in analyzing both networks and data in applications of large-scale recognition, fine-grained recognition, subsurface seismic analysis, and image quality assessment.