 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Structures of Representation for the Robustness of Semantic Segmentation to Input Corruption
Sep 02, 2020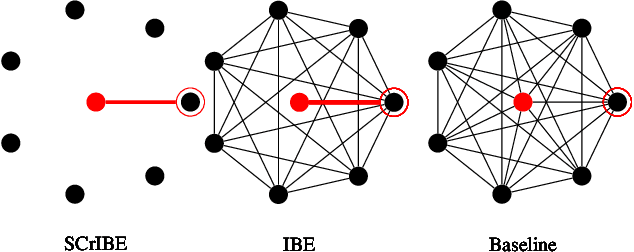
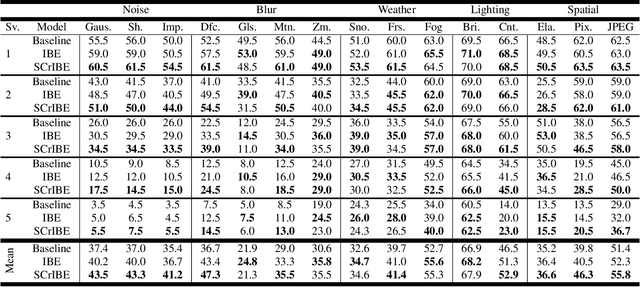

Semantic segmentation is a scene understanding task at the heart of safety-critical applications where robustness to corrupted inputs is essential. Implicit Background Estimation (IBE) has demonstrated to be a promising technique to improve the robustness to out-of-distribution inputs for semantic segmentation models for little to no cost. In this paper, we provide analysis comparing the structures learned as a result of optimization objectives that use Softmax, IBE, and Sigmoid in order to improve understanding their relationship to robustness. As a result of this analysis, we propose combining Sigmoid with IBE (SCrIBE) to improve robustness. Finally, we demonstrate that SCrIBE exhibits superior segmentation performance aggregated across all corruptions and severity levels with a mIOU of 42.1 compared to both IBE 40.3 and the Softmax Baseline 37.5.
Novelty Detection Through Model-Based Characterization of Neural Networks
Aug 13, 2020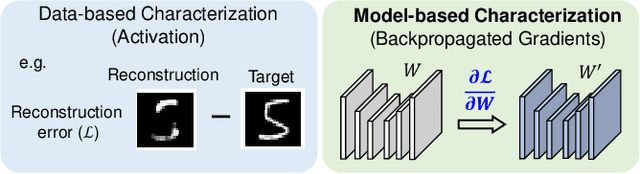
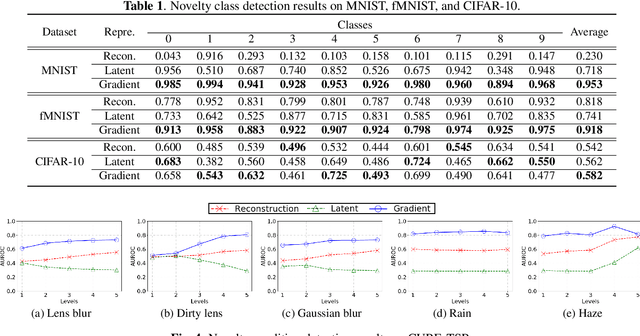
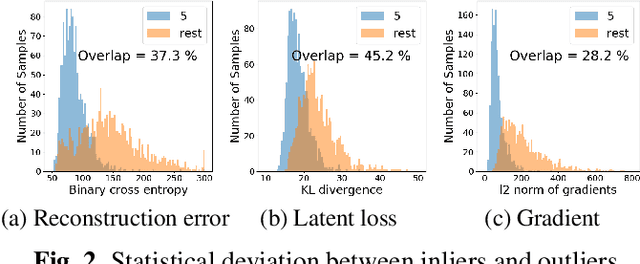
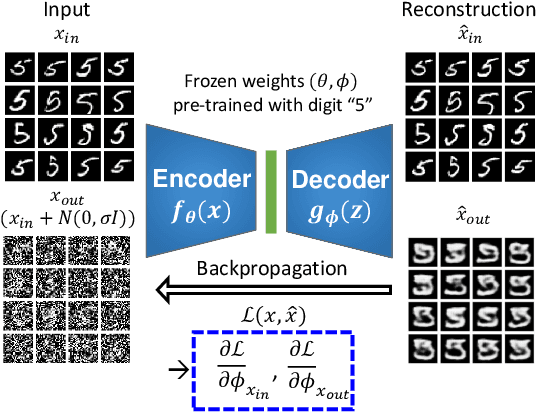
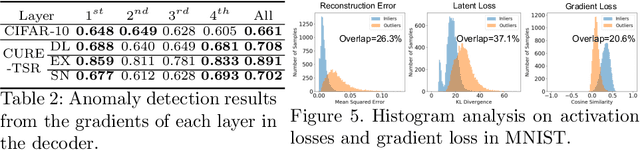
In this paper, we propose a model-based characterization of neural networks to detect novel input types and conditions. Novelty detection is crucial to identify abnormal inputs that can significantly degrade the performance of machine learning algorithms. Majority of existing studies have focused on activation-based representations to detect abnormal inputs, which limits the characterization of abnormality from a data perspective. However, a model perspective can also be informative in terms of the novelties and abnormalities. To articulate the significance of the model perspective in novelty detection, we utilize backpropagated gradients. We conduct a comprehensive analysis to compare the representation capability of gradients with that of activation and show that the gradients outperform the activation in novel class and condition detection. We validate our approach using four image recognition datasets including MNIST, Fashion-MNIST, CIFAR-10, and CURE-TSR. We achieve a significant improvement on all four datasets with an average AUROC of 0.953, 0.918, 0.582, and 0.746, respectively.
Contrastive Explanations in Neural Networks
Aug 01, 2020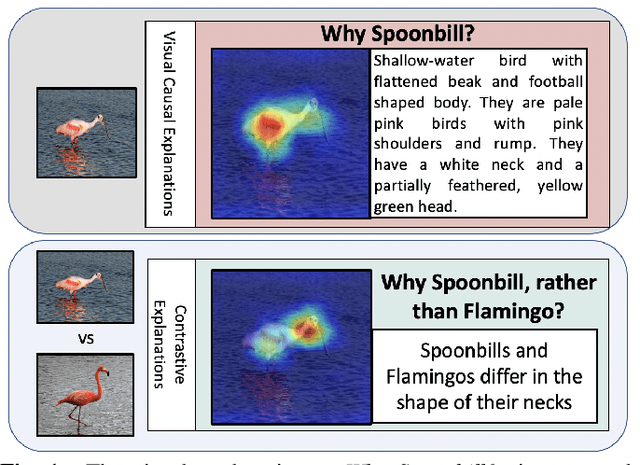
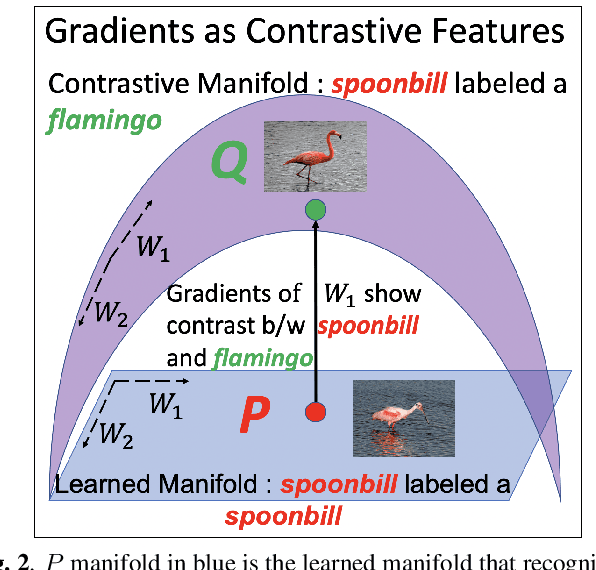
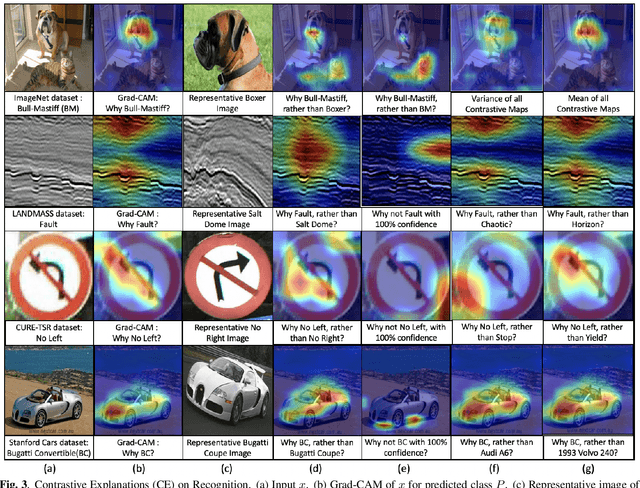

Visual explanations are logical arguments based on visual features that justify the predictions made by neural networks. Current modes of visual explanations answer questions of the form $`Why \text{ } P?'$. These $Why$ questions operate under broad contexts thereby providing answers that are irrelevant in some cases. We propose to constrain these $Why$ questions based on some context $Q$ so that our explanations answer contrastive questions of the form $`Why \text{ } P, \text{} rather \text{ } than \text{ } Q?'$. In this paper, we formalize the structure of contrastive visual explanations for neural networks. We define contrast based on neural networks and propose a methodology to extract defined contrasts. We then use the extracted contrasts as a plug-in on top of existing $`Why \text{ } P?'$ techniques, specifically Grad-CAM. We demonstrate their value in analyzing both networks and data in applications of large-scale recognition, fine-grained recognition, subsurface seismic analysis, and image quality assessment.
Backpropagated Gradient Representations for Anomaly Detection
Jul 18, 2020
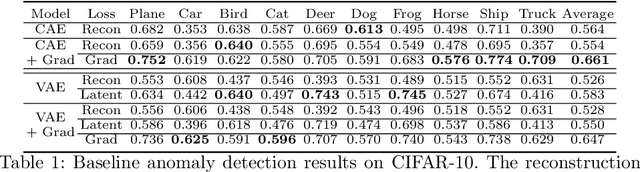
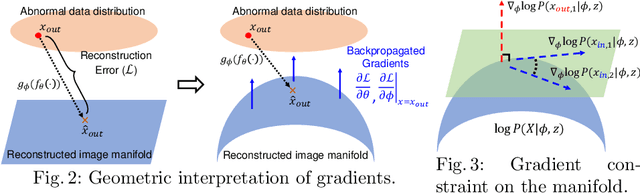
Learning representations that clearly distinguish between normal and abnormal data is key to the success of anomaly detection. Most of existing anomaly detection algorithms use activation representations from forward propagation while not exploiting gradients from backpropagation to characterize data. Gradients capture model updates required to represent data. Anomalies require more drastic model updates to fully represent them compared to normal data. Hence, we propose the utilization of backpropagated gradients as representations to characterize model behavior on anomalies and, consequently, detect such anomalies. We show that the proposed method using gradient-based representations achieves state-of-the-art anomaly detection performance in benchmark image recognition datasets. Also, we highlight the computational efficiency and the simplicity of the proposed method in comparison with other state-of-the-art methods relying on adversarial networks or autoregressive models, which require at least 27 times more model parameters than the proposed method.
Traffic Sign Detection under Challenging Conditions: A Deeper Look Into Performance Variations and Spectral Characteristics
Aug 29, 2019


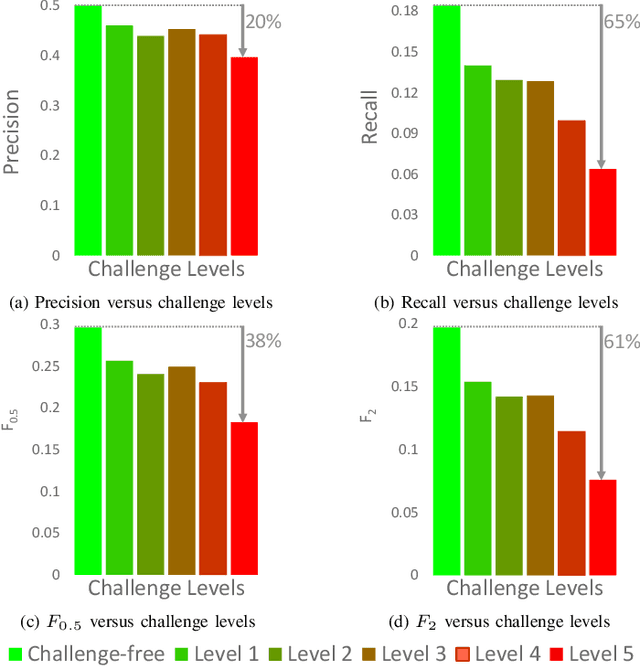
Traffic signs are critical for maintaining the safety and efficiency of our roads. Therefore, we need to carefully assess the capabilities and limitations of automated traffic sign detection systems. Existing traffic sign datasets are limited in terms of type and severity of challenging conditions. Metadata corresponding to these conditions are unavailable and it is not possible to investigate the effect of a single factor because of simultaneous changes in numerous conditions. To overcome the shortcomings in existing datasets, we introduced the CURE-TSD-Real dataset, which is based on simulated challenging conditions that correspond to adversaries that can occur in real-world environments and systems. We test the performance of two benchmark algorithms and show that severe conditions can result in an average performance degradation of 29% in precision and 68% in recall. We investigate the effect of challenging conditions through spectral analysis and show that challenging conditions can lead to distinct magnitude spectrum characteristics. Moreover, we show that mean magnitude spectrum of changes in video sequences under challenging conditions can be an indicator of detection performance. CURE-TSD-Real dataset is available online at https://github.com/olivesgatech/CURE-TSD.
Distorted Representation Space Characterization Through Backpropagated Gradients
Aug 27, 2019

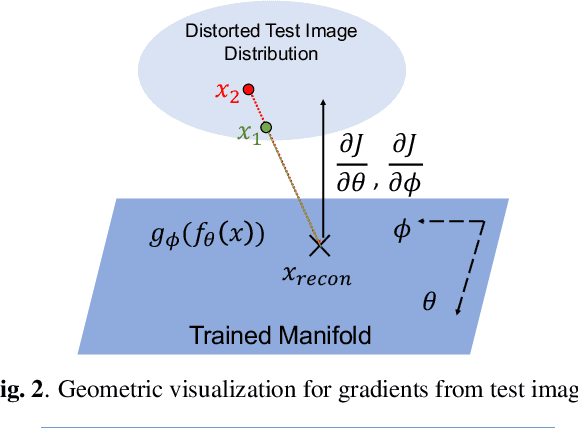
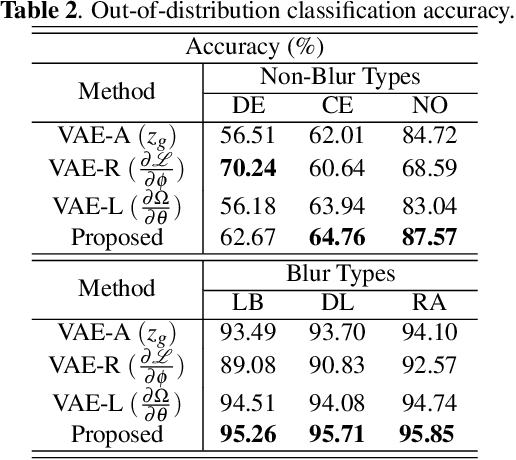
In this paper, we utilize weight gradients from backpropagation to characterize the representation space learned by deep learning algorithms. We demonstrate the utility of such gradients in applications including perceptual image quality assessment and out-of-distribution classification. The applications are chosen to validate the effectiveness of gradients as features when the test image distribution is distorted from the train image distribution. In both applications, the proposed gradient based features outperform activation features. In image quality assessment, the proposed approach is compared with other state of the art approaches and is generally the top performing method on TID 2013 and MULTI-LIVE databases in terms of accuracy, consistency, linearity, and monotonic behavior. Finally, we analyze the effect of regularization on gradients using CURE-TSR dataset for out-of-distribution classification.
Relative Afferent Pupillary Defect Screening through Transfer Learning
Aug 06, 2019
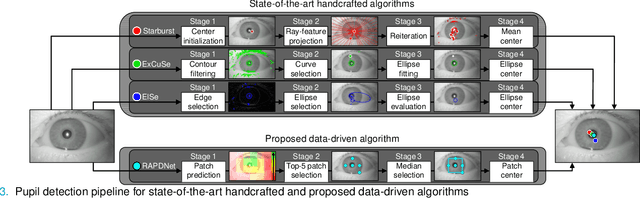

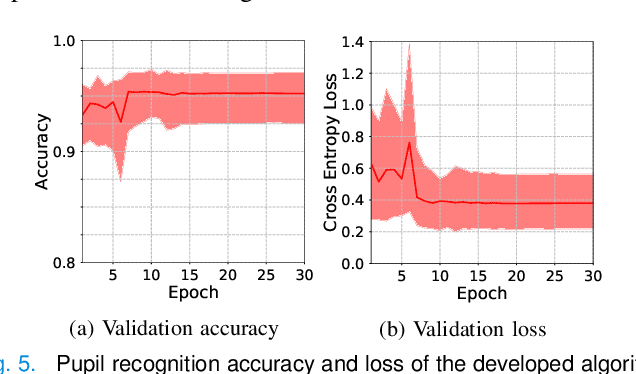
Abnormalities in pupillary light reflex can indicate optic nerve disorders that may lead to permanent visual loss if not diagnosed in an early stage. In this study, we focus on relative afferent pupillary defect (RAPD), which is based on the difference between the reactions of the eyes when they are exposed to light stimuli. Incumbent RAPD assessment methods are based on subjective practices that can lead to unreliable measurements. To eliminate subjectivity and obtain reliable measurements, we introduced an automated framework to detect RAPD. For validation, we conducted a clinical study with lab-on-a-headset, which can perform automated light reflex test. In addition to benchmarking handcrafted algorithms, we proposed a transfer learning-based approach that transformed a deep learning-based generic object recognition algorithm into a pupil detector. Based on the conducted experiments, proposed algorithm RAPDNet can achieve a sensitivity and a specificity of 90.6% over 64 test cases in a balanced set, which corresponds to an AUC of 0.929 in ROC analysis. According to our benchmark with three handcrafted algorithms and nine performance metrics, RAPDNet outperforms all other algorithms in every performance category.
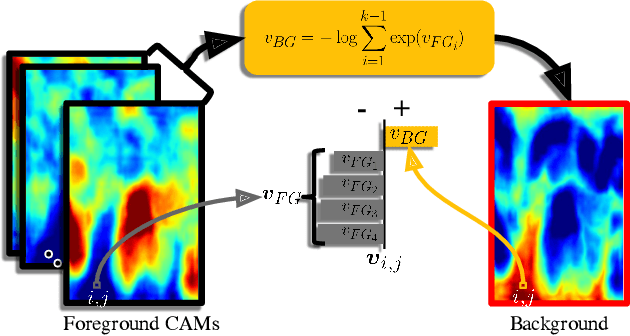
Implicit Background Estimation for Semantic Segmentation
May 23, 2019

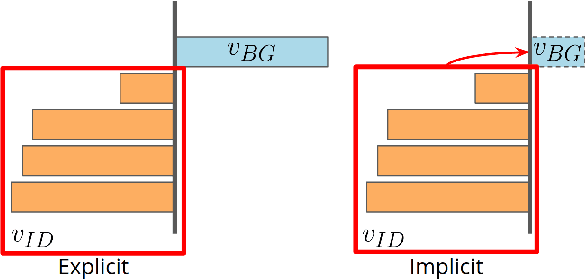

Scene understanding and semantic segmentation are at the core of many computer vision tasks, many of which, involve interacting with humans in potentially dangerous ways. It is therefore paramount that techniques for principled design of robust models be developed. In this paper, we provide analytic and empirical evidence that correcting potentially errant non-distinct mappings that result from the softmax function can result in improving robustness characteristics on a state-of-the-art semantic segmentation model with minimal impact to performance and minimal changes to the code base.
Automated Pupillary Light Reflex Test on a Portable Platform
May 21, 2019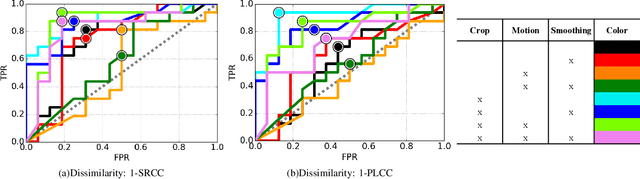
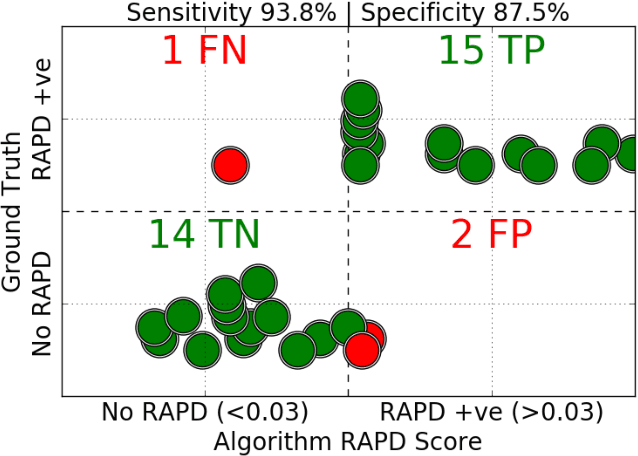
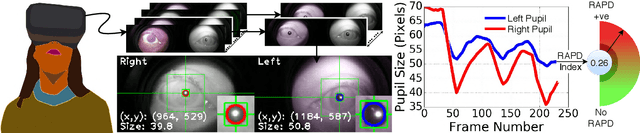
In this paper, we introduce a portable eye imaging device denoted as lab-on-a-headset, which can automatically perform a swinging flashlight test. We utilized this device in a clinical study to obtain high-resolution recordings of eyes while they are exposed to a varying light stimuli. Half of the participants had relative afferent pupillary defect (RAPD) while the other half was a control group. In case of positive RAPD, patients pupils constrict less or do not constrict when light stimuli swings from the unaffected eye to the affected eye. To automatically diagnose RAPD, we propose an algorithm based on pupil localization, pupil size measurement, and pupil size comparison of right and left eye during the light reflex test. We validate the algorithmic performance over a dataset obtained from 22 subjects and show that proposed algorithm can achieve a sensitivity of 93.8% and a specificity of 87.5%.
* 7 pages, 11 figures, 3 tables
Challenging Environments for Traffic Sign Detection: Reliability Assessment under Inclement Conditions
Feb 19, 2019
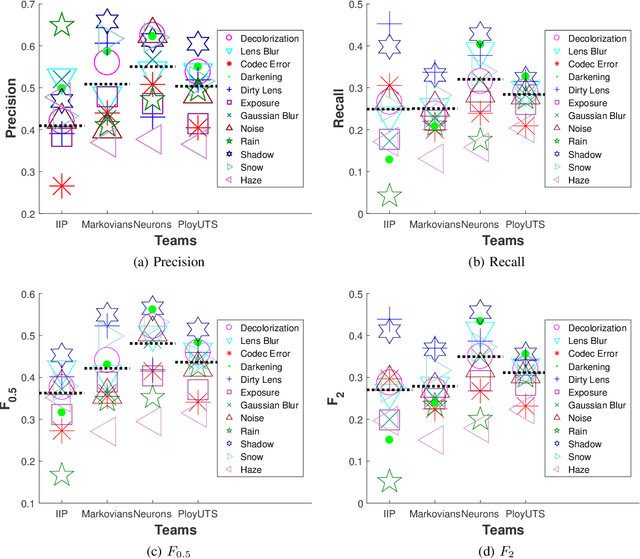
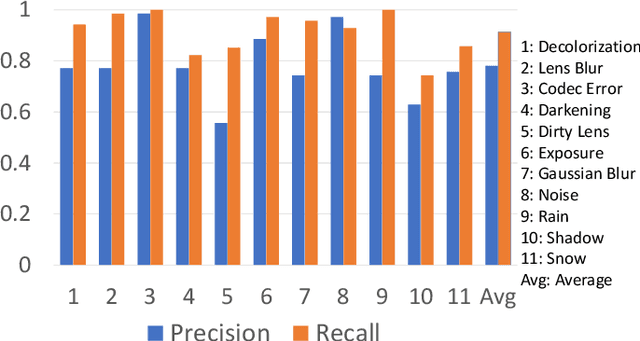

State-of-the-art algorithms successfully localize and recognize traffic signs over existing datasets, which are limited in terms of challenging condition type and severity. Therefore, it is not possible to estimate the performance of traffic sign detection algorithms under overlooked challenging conditions. Another shortcoming of existing datasets is the limited utilization of temporal information and the unavailability of consecutive frames and annotations. To overcome these shortcomings, we generated the CURE-TSD video dataset and hosted the first IEEE Video and Image Processing (VIP) Cup within the IEEE Signal Processing Society. In this paper, we provide a detailed description of the CURE-TSD dataset, analyze the characteristics of the top performing algorithms, and provide a performance benchmark. Moreover, we investigate the robustness of the benchmarked algorithms with respect to sign size, challenge type and severity. Benchmarked algorithms are based on state-of-the-art and custom convolutional neural networks that achieved a precision of 0.55 and a recall of 0.32, F0.5 score of 0.48 and F2 score of 0.35. Experimental results show that benchmarked algorithms are highly sensitive to tested challenging conditions, which result in an average performance drop of 0.17 in terms of precision and a performance drop of 0.28 in recall under severe conditions. The dataset is publicly available at https://ghassanalregib.com/curetsd/.