 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Emojis to Train Emotion Classifiers
Paper and Code
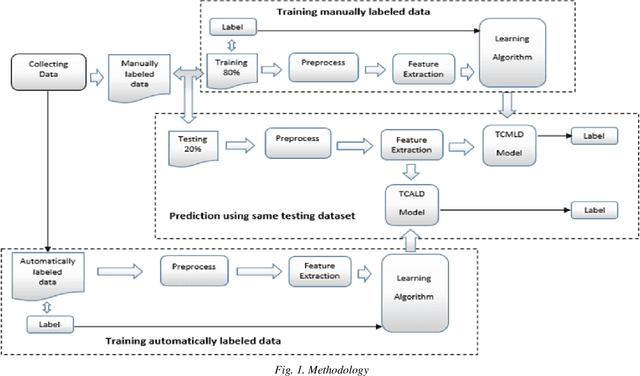
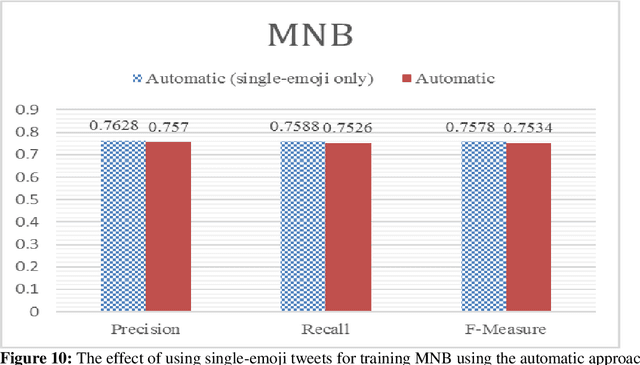
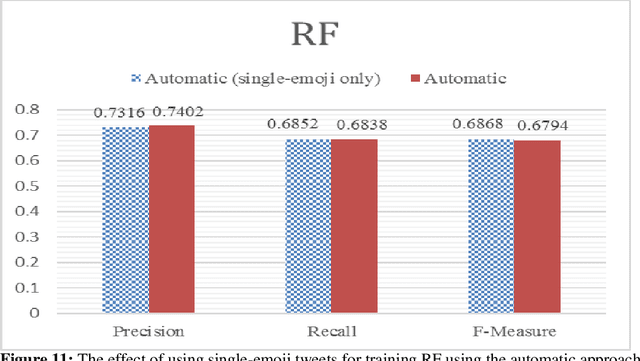
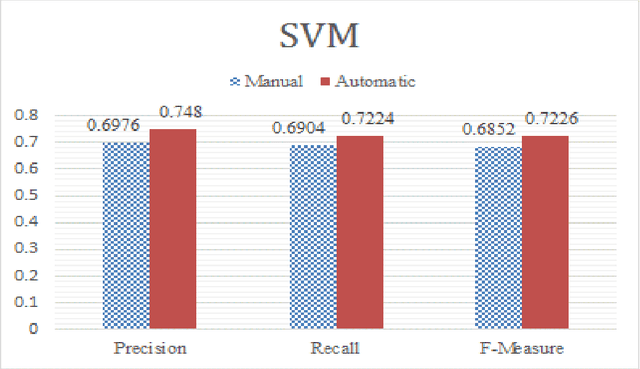
Nowadays, the automatic detection of emotions is employed by many applications in different fields like security informatics, e-learning, humor detection, targeted advertising, etc. Many of these applications focus on social media and treat this problem as a classification problem, which requires preparing training data. The typical method for annotating the training data by human experts is considered time consuming, labor intensive and sometimes prone to error. Moreover, such an approach is not easily extensible to new domains/languages since such extensions require annotating new training data. In this study, we propose a distant supervised learning approach where the training sentences are automatically annotated based on the emojis they have. Such training data would be very cheap to produce compared with the manually created training data, thus, much larger training data can be easily obtained. On the other hand, this training data would naturally have lower quality as it may contain some errors in the annotation. Nonetheless, we experimentally show that training classifiers on cheap, large and possibly erroneous data annotated using this approach leads to more accurate results compared with training the same classifiers on the more expensive, much smaller and error-free manually annotated training data. Our experiments are conducted on an in-house dataset of emotional Arabic tweets and the classifiers we consider are: Support Vector Machine (SVM), Multinomial Naive Bayes (MNB) and Random Forest (RF). In addition to experimenting with single classifiers, we also consider using an ensemble of classifiers. The results show that using an automatically annotated training data (that is only one order of magnitude larger than the manually annotated one) gives better results in almost all settings considered.