 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
AraHalluEval: A Fine-grained Hallucination Evaluation Framework for Arabic LLMs
Sep 04, 2025Recently, extensive research on the hallucination of the large language models (LLMs) has mainly focused on the English language. Despite the growing number of multilingual and Arabic-specific LLMs, evaluating LLMs' hallucination in the Arabic context remains relatively underexplored. The knowledge gap is particularly pressing given Arabic's widespread use across many regions and its importance in global communication and media. This paper presents the first comprehensive hallucination evaluation of Arabic and multilingual LLMs on two critical Arabic natural language generation tasks: generative question answering (GQA) and summarization. This study evaluates a total of 12 LLMs, including 4 Arabic pre-trained models, 4 multilingual models, and 4 reasoning-based models. To assess the factual consistency and faithfulness of LLMs' outputs, we developed a fine-grained hallucination evaluation framework consisting of 12 fine-grained hallucination indicators that represent the varying characteristics of each task. The results reveal that factual hallucinations are more prevalent than faithfulness errors across all models and tasks. Notably, the Arabic pre-trained model Allam consistently demonstrates lower hallucination rates than multilingual models and a comparative performance with reasoning-based models. The code is available at: \href{https://github.com/aishaalansari57/AraHalluEval}{Github link}.
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Jun 11, 2025Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
SSLR: A Semi-Supervised Learning Method for Isolated Sign Language Recognition
Apr 23, 2025Sign language is the primary communication language for people with disabling hearing loss. Sign language recognition (SLR) systems aim to recognize sign gestures and translate them into spoken language. One of the main challenges in SLR is the scarcity of annotated datasets. To address this issue, we propose a semi-supervised learning (SSL) approach for SLR (SSLR), employing a pseudo-label method to annotate unlabeled samples. The sign gestures are represented using pose information that encodes the signer's skeletal joint points. This information is used as input for the Transformer backbone model utilized in the proposed approach. To demonstrate the learning capabilities of SSL across various labeled data sizes, several experiments were conducted using different percentages of labeled data with varying numbers of classes. The performance of the SSL approach was compared with a fully supervised learning-based model on the WLASL-100 dataset. The obtained results of the SSL model outperformed the supervised learning-based model with less labeled data in many cases.
CLIP-SLA: Parameter-Efficient CLIP Adaptation for Continuous Sign Language Recognition
Apr 02, 2025



Continuous sign language recognition (CSLR) focuses on interpreting and transcribing sequences of sign language gestures in videos. In this work, we propose CLIP sign language adaptation (CLIP-SLA), a novel CSLR framework that leverages the powerful pre-trained visual encoder from the CLIP model to sign language tasks through parameter-efficient fine-tuning (PEFT). We introduce two variants, SLA-Adapter and SLA-LoRA, which integrate PEFT modules into the CLIP visual encoder, enabling fine-tuning with minimal trainable parameters. The effectiveness of the proposed frameworks is validated on four datasets: Phoenix2014, Phoenix2014-T, CSL-Daily, and Isharah-500, where both CLIP-SLA variants outperformed several SOTA models with fewer trainable parameters. Extensive ablation studies emphasize the effectiveness and flexibility of the proposed methods with different vision-language models for CSLR. These findings showcase the potential of adapting large-scale pre-trained models for scalable and efficient CSLR, which pave the way for future advancements in sign language understanding.
A Comparative Study of Continuous Sign Language Recognition Techniques
Jun 18, 2024



Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.
FSBI: Deepfakes Detection with Frequency Enhanced Self-Blended Images
Jun 12, 2024



Advances in deepfake research have led to the creation of almost perfect manipulations undetectable by human eyes and some deepfakes detection tools. Recently, several techniques have been proposed to differentiate deepfakes from realistic images and videos. This paper introduces a Frequency Enhanced Self-Blended Images (FSBI) approach for deepfakes detection. This proposed approach utilizes Discrete Wavelet Transforms (DWT) to extract discriminative features from the self-blended images (SBI) to be used for training a convolutional network architecture model. The SBIs blend the image with itself by introducing several forgery artifacts in a copy of the image before blending it. This prevents the classifier from overfitting specific artifacts by learning more generic representations. These blended images are then fed into the frequency features extractor to detect artifacts that can not be detected easily in the time domain. The proposed approach has been evaluated on FF++ and Celeb-DF datasets and the obtained results outperformed the state-of-the-art techniques with the cross-dataset evaluation protocol.
Taqyim: Evaluating Arabic NLP Tasks Using ChatGPT Models
Jun 28, 2023



Large language models (LLMs) have demonstrated impressive performance on various downstream tasks without requiring fine-tuning, including ChatGPT, a chat-based model built on top of LLMs such as GPT-3.5 and GPT-4. Despite having a lower training proportion compared to English, these models also exhibit remarkable capabilities in other languages. In this study, we assess the performance of GPT-3.5 and GPT-4 models on seven distinct Arabic NLP tasks: sentiment analysis, translation, transliteration, paraphrasing, part of speech tagging, summarization, and diacritization. Our findings reveal that GPT-4 outperforms GPT-3.5 on five out of the seven tasks. Furthermore, we conduct an extensive analysis of the sentiment analysis task, providing insights into how LLMs achieve exceptional results on a challenging dialectal dataset. Additionally, we introduce a new Python interface https://github.com/ARBML/Taqyim that facilitates the evaluation of these tasks effortlessly.
Recursions Are All You Need: Towards Efficient Deep Unfolding Networks
May 09, 2023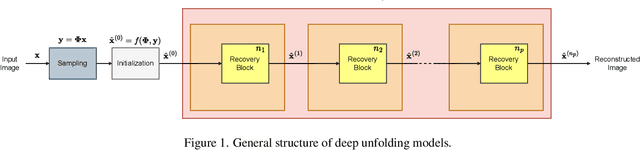
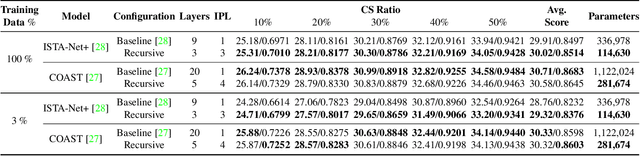

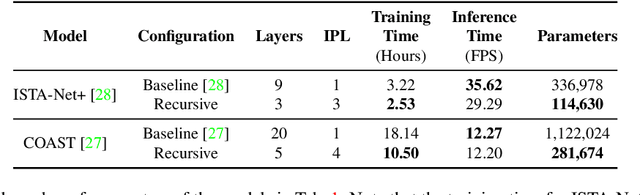
The use of deep unfolding networks in compressive sensing (CS) has seen wide success as they provide both simplicity and interpretability. However, since most deep unfolding networks are iterative, this incurs significant redundancies in the network. In this work, we propose a novel recursion-based framework to enhance the efficiency of deep unfolding models. First, recursions are used to effectively eliminate the redundancies in deep unfolding networks. Secondly, we randomize the number of recursions during training to decrease the overall training time. Finally, to effectively utilize the power of recursions, we introduce a learnable unit to modulate the features of the model based on both the total number of iterations and the current iteration index. To evaluate the proposed framework, we apply it to both ISTA-Net+ and COAST. Extensive testing shows that our proposed framework allows the network to cut down as much as 75% of its learnable parameters while mostly maintaining its performance, and at the same time, it cuts around 21% and 42% from the training time for ISTA-Net+ and COAST respectively. Moreover, when presented with a limited training dataset, the recursive models match or even outperform their respective non-recursive baseline. Codes and pretrained models are available at https://github.com/Rawwad-Alhejaili/Recursions-Are-All-You-Need .