 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Unlearn: Building Immunity to Dataset Bias in Medical Imaging Studies
Dec 03, 2018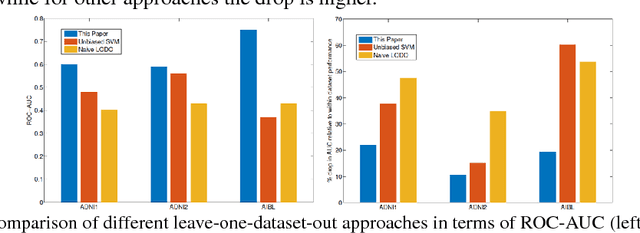
Medical imaging machine learning algorithms are usually evaluated on a single dataset. Although training and testing are performed on different subsets of the dataset, models built on one study show limited capability to generalize to other studies. While database bias has been recognized as a serious problem in the computer vision community, it has remained largely unnoticed in medical imaging research. Transfer learning thus remains confined to the re-use of feature representations requiring re-training on the new dataset. As a result, machine learning models do not generalize even when trained on imaging datasets that were captured to study the same variable of interest. The ability to transfer knowledge gleaned from one study to another, without the need for re-training, if possible, would provide reassurance that the models are learning knowledge fundamental to the problem under study instead of latching onto the idiosyncracies of a dataset. In this paper, we situate the problem of dataset bias in the context of medical imaging studies. We show empirical evidence that such a problem exists in medical datasets. We then present a framework to unlearn study membership as a means to handle the problem of database bias. Our main idea is to take the data from the original feature space to an intermediate space where the data points are indistinguishable in terms of which study they come from, while maintaining the recognition capability with respect to the variable of interest. This will promote models which learn the more general properties of the etiology under study instead of aligning to dataset-specific peculiarities. Essentially, our proposed model learns to unlearn the dataset bias.