 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapDISCOM: An Adaptive Sparse Regression Method for High-Dimensional Multimodal Data With Block-Wise Missingness and Measurement Errors
Jul 31, 2025Multimodal high-dimensional data are increasingly prevalent in biomedical research, yet they are often compromised by block-wise missingness and measurement errors, posing significant challenges for statistical inference and prediction. We propose AdapDISCOM, a novel adaptive direct sparse regression method that simultaneously addresses these two pervasive issues. Building on the DISCOM framework, AdapDISCOM introduces modality-specific weighting schemes to account for heterogeneity in data structures and error magnitudes across modalities. We establish the theoretical properties of AdapDISCOM, including model selection consistency and convergence rates under sub-Gaussian and heavy-tailed settings, and develop robust and computationally efficient variants (AdapDISCOM-Huber and Fast-AdapDISCOM). Extensive simulations demonstrate that AdapDISCOM consistently outperforms existing methods such as DISCOM, SCOM, and CoCoLasso, particularly under heterogeneous contamination and heavy-tailed distributions. Finally, we apply AdapDISCOM to Alzheimers Disease Neuroimaging Initiative (ADNI) data, demonstrating improved prediction of cognitive scores and reliable selection of established biomarkers, even with substantial missingness and measurement errors. AdapDISCOM provides a flexible, robust, and scalable framework for high-dimensional multimodal data analysis under realistic data imperfections.
fastHDMI: Fast Mutual Information Estimation for High-Dimensional Data
Oct 14, 2024



In this paper, we introduce fastHDMI, a Python package designed for efficient variable screening in high-dimensional datasets, particularly neuroimaging data. This work pioneers the application of three mutual information estimation methods for neuroimaging variable selection, a novel approach implemented via fastHDMI. These advancements enhance our ability to analyze the complex structures of neuroimaging datasets, providing improved tools for variable selection in high-dimensional spaces. Using the preprocessed ABIDE dataset, we evaluate the performance of these methods through extensive simulations. The tests cover a range of conditions, including linear and nonlinear associations, as well as continuous and binary outcomes. Our results highlight the superiority of the FFTKDE-based mutual information estimation for feature screening in continuous nonlinear outcomes, while binning-based methods outperform others for binary outcomes with nonlinear probability preimages. For linear simulations, both Pearson correlation and FFTKDE-based methods show comparable performance for continuous outcomes, while Pearson excels in binary outcomes with linear probability preimages. A comprehensive case study using the ABIDE dataset further demonstrates fastHDMI's practical utility, showcasing the predictive power of models built from variables selected using our screening techniques. This research affirms the computational efficiency and methodological strength of fastHDMI, significantly enriching the toolkit available for neuroimaging analysis.
Carbon Footprint of Selecting and Training Deep Learning Models for Medical Image Analysis
Mar 04, 2022

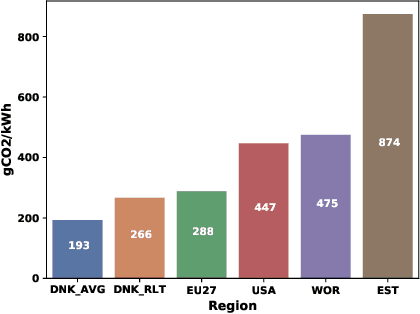

The increasing energy consumption and carbon footprint of deep learning (DL) due to growing compute requirements has become a cause of concern. In this work, we focus on the carbon footprint of developing DL models for medical image analysis (MIA), where volumetric images of high spatial resolution are handled. In this study, we present and compare the features of four tools from literature to quantify the carbon footprint of DL. Using one of these tools we estimate the carbon footprint of medical image segmentation pipelines. We choose nnU-net as the proxy for a medical image segmentation pipeline and experiment on three common datasets. With our work we hope to inform on the increasing energy costs incurred by MIA. We discuss simple strategies to cut-down the environmental impact that can make model selection and training processes more efficient.
An algorithm-based multiple detection influence measure for high dimensional regression using expectile
May 26, 2021


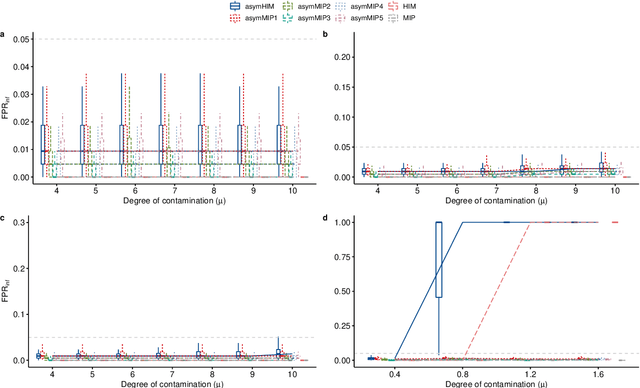
The identification of influential observations is an important part of data analysis that can prevent erroneous conclusions drawn from biased estimators. However, in high dimensional data, this identification is challenging. Classical and recently-developed methods often perform poorly when there are multiple influential observations in the same dataset. In particular, current methods can fail when there is masking several influential observations with similar characteristics, or swamping when the influential observations are near the boundary of the space spanned by well-behaved observations. Therefore, we propose an algorithm-based, multi-step, multiple detection procedure to identify influential observations that addresses current limitations. Our three-step algorithm to identify and capture undesirable variability in the data, $\asymMIP,$ is based on two complementary statistics, inspired by asymmetric correlations, and built on expectiles. Simulations demonstrate higher detection power than competing methods. Use of the resulting asymptotic distribution leads to detection of influential observations without the need for computationally demanding procedures such as the bootstrap. The application of our method to the Autism Brain Imaging Data Exchange neuroimaging dataset resulted in a more balanced and accurate prediction of brain maturity based on cortical thickness. See our GitHub for a free R package that implements our algorithm: \texttt{asymMIP} (\url{github.com/AmBarry/hidetify}).
Learning to Unlearn: Building Immunity to Dataset Bias in Medical Imaging Studies
Dec 03, 2018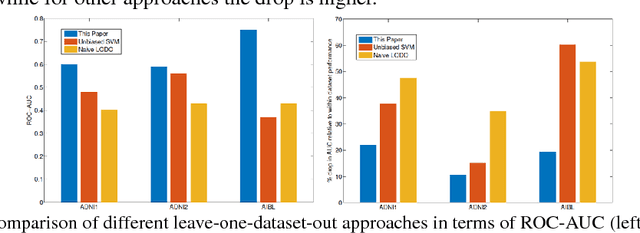
Medical imaging machine learning algorithms are usually evaluated on a single dataset. Although training and testing are performed on different subsets of the dataset, models built on one study show limited capability to generalize to other studies. While database bias has been recognized as a serious problem in the computer vision community, it has remained largely unnoticed in medical imaging research. Transfer learning thus remains confined to the re-use of feature representations requiring re-training on the new dataset. As a result, machine learning models do not generalize even when trained on imaging datasets that were captured to study the same variable of interest. The ability to transfer knowledge gleaned from one study to another, without the need for re-training, if possible, would provide reassurance that the models are learning knowledge fundamental to the problem under study instead of latching onto the idiosyncracies of a dataset. In this paper, we situate the problem of dataset bias in the context of medical imaging studies. We show empirical evidence that such a problem exists in medical datasets. We then present a framework to unlearn study membership as a means to handle the problem of database bias. Our main idea is to take the data from the original feature space to an intermediate space where the data points are indistinguishable in terms of which study they come from, while maintaining the recognition capability with respect to the variable of interest. This will promote models which learn the more general properties of the etiology under study instead of aligning to dataset-specific peculiarities. Essentially, our proposed model learns to unlearn the dataset bias.