 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Chemical Toxicity using Missing Features
Sep 23, 2020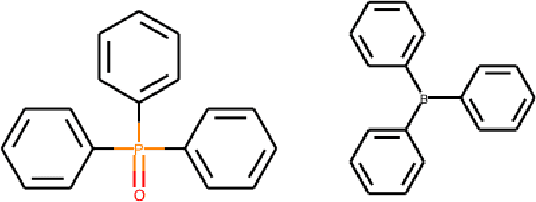
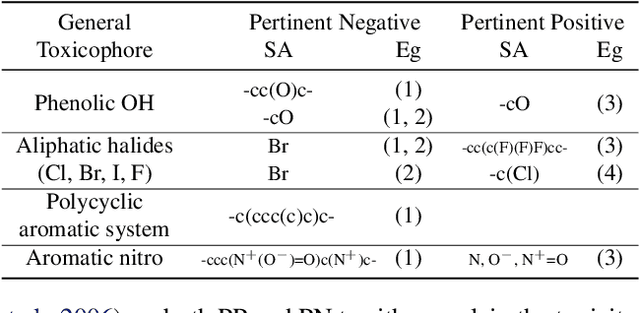

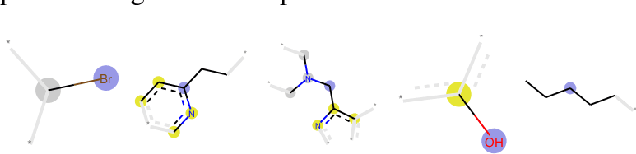
Chemical toxicity prediction using machine learning is important in drug development to reduce repeated animal and human testing, thus saving cost and time. It is highly recommended that the predictions of computational toxicology models are mechanistically explainable. Current state of the art machine learning classifiers are based on deep neural networks, which tend to be complex and harder to interpret. In this paper, we apply a recently developed method named contrastive explanations method (CEM) to explain why a chemical or molecule is predicted to be toxic or not. In contrast to popular methods that provide explanations based on what features are present in the molecule, the CEM provides additional explanation on what features are missing from the molecule that is crucial for the prediction, known as the pertinent negative. The CEM does this by optimizing for the minimum perturbation to the model using a projected fast iterative shrinkage-thresholding algorithm (FISTA). We verified that the explanation from CEM matches known toxicophores and findings from other work.
Target-Specific and Selective Drug Design for COVID-19 Using Deep Generative Models
Apr 02, 2020

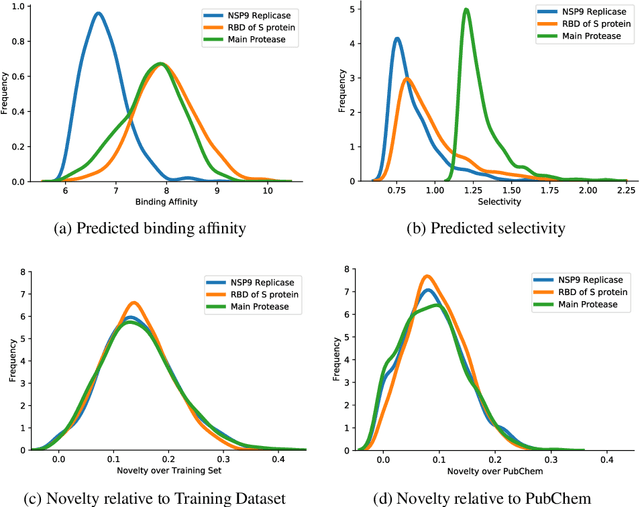
The recent COVID-19 pandemic has highlighted the need for rapid therapeutic development for infectious diseases. To accelerate this process, we present a deep learning based generative modeling framework, CogMol, to design drug candidates specific to a given target protein sequence with high off-target selectivity. We augment this generative framework with an in silico screening process that accounts for toxicity, to lower the failure rate of the generated drug candidates in later stages of the drug development pipeline. We apply this framework to three relevant proteins of the SARS-CoV-2, the virus responsible for COVID-19, namely non-structural protein 9 (NSP9) replicase, main protease, and the receptor-binding domain (RBD) of the S protein. Docking to the target proteins demonstrate the potential of these generated molecules as ligands. Structural similarity analyses further imply novelty of the generated molecules with respect to the training dataset as well as possible biological association of a number of generated molecules that might be of relevance to COVID-19 therapeutic design. While the validation of these molecules is underway, we release ~ 3000 novel COVID-19 drug candidates generated using our framework. URL : http://ibm.biz/covid19-mol
GEE: A Gradient-based Explainable Variational Autoencoder for Network Anomaly Detection
Mar 15, 2019
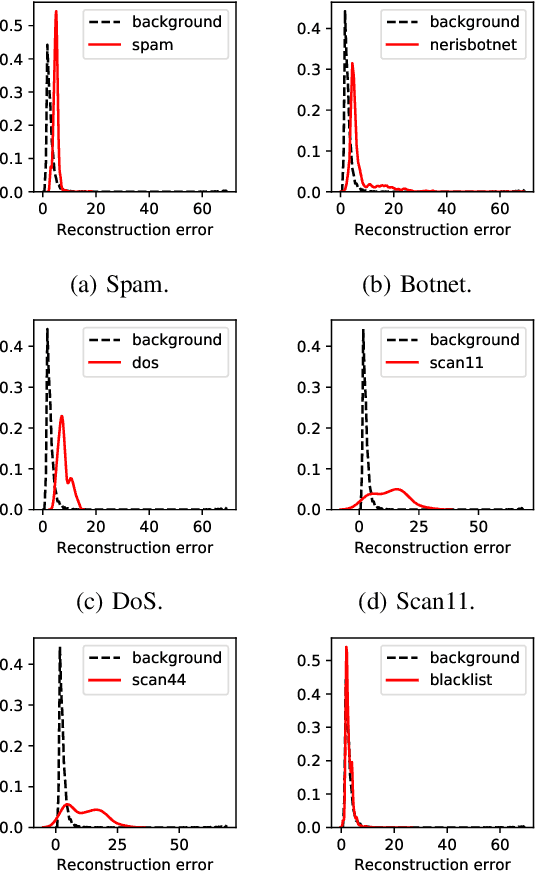
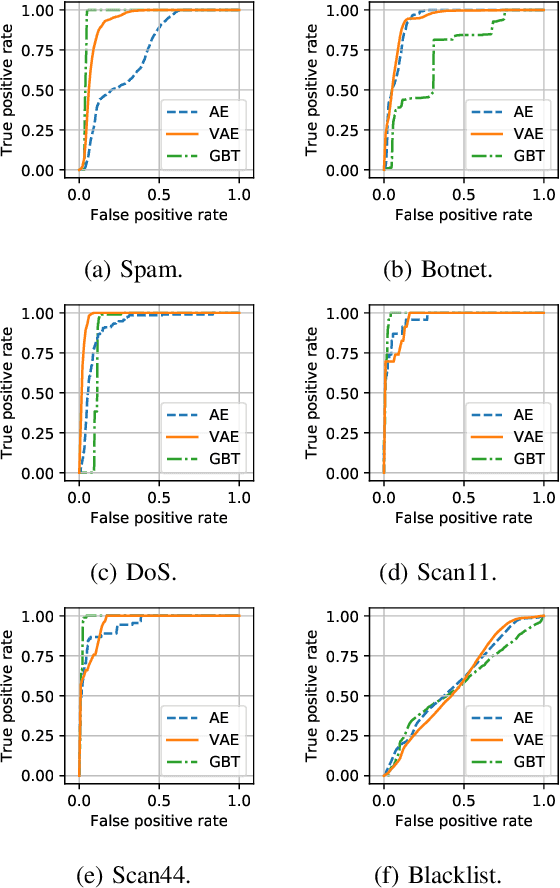
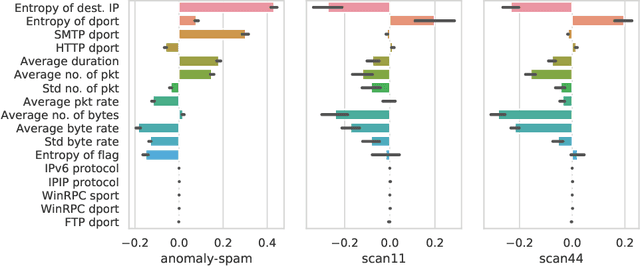
This paper looks into the problem of detecting network anomalies by analyzing NetFlow records. While many previous works have used statistical models and machine learning techniques in a supervised way, such solutions have the limitations that they require large amount of labeled data for training and are unlikely to detect zero-day attacks. Existing anomaly detection solutions also do not provide an easy way to explain or identify attacks in the anomalous traffic. To address these limitations, we develop and present GEE, a framework for detecting and explaining anomalies in network traffic. GEE comprises of two components: (i) Variational Autoencoder (VAE) - an unsupervised deep-learning technique for detecting anomalies, and (ii) a gradient-based fingerprinting technique for explaining anomalies. Evaluation of GEE on the recent UGR dataset demonstrates that our approach is effective in detecting different anomalies as well as identifying fingerprints that are good representations of these various attacks.
Simulation and Calibration of a Fully Bayesian Marked Multidimensional Hawkes Process with Dissimilar Decays
Mar 13, 2018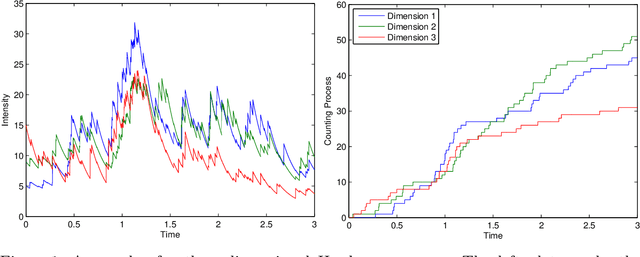
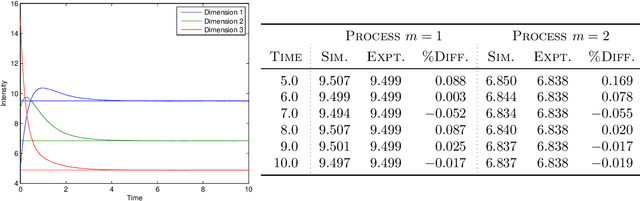
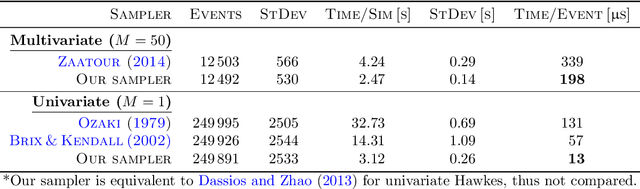
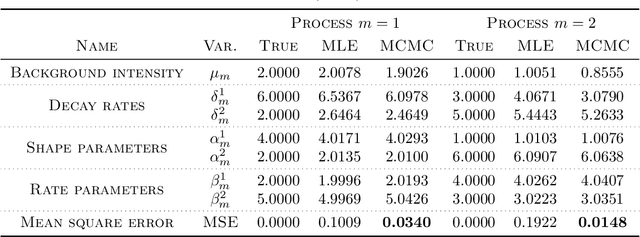
We propose a simulation method for multidimensional Hawkes processes based on superposition theory of point processes. This formulation allows us to design efficient simulations for Hawkes processes with differing exponentially decaying intensities. We demonstrate that inter-arrival times can be decomposed into simpler auxiliary variables that can be sampled directly, giving exact simulation with no approximation. We establish that the auxiliary variables provides information on the parent process for each event time. The algorithm correctness is shown by verifying the simulated intensities with their theoretical moments. A modular inference procedure consisting of Gibbs samplers through the auxiliary variable augmentation and adaptive rejection sampling is presented. Finally, we compare our proposed simulation method against existing methods, and find significant improvement in terms of algorithm speed. Our inference algorithm is used to discover the strengths of mutually excitations in real dark networks.
* 24 pages, long version of ACML paper with supplementary material
Hawkes Processes with Stochastic Excitations
Sep 22, 2016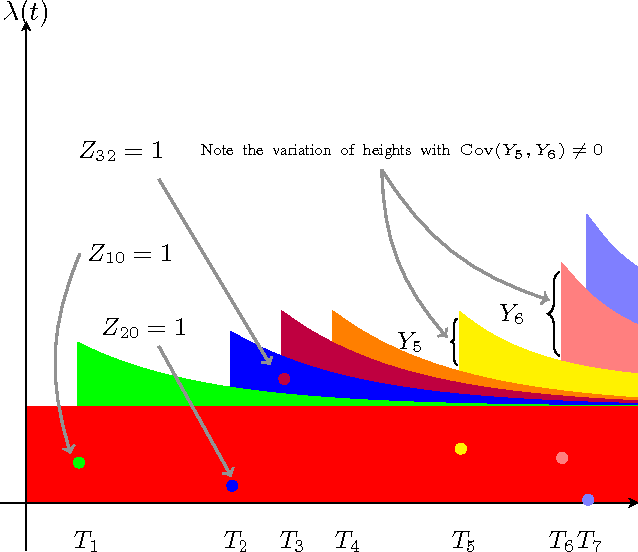
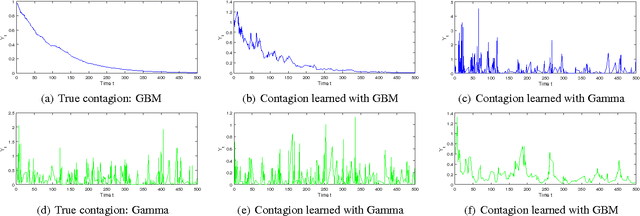
We propose an extension to Hawkes processes by treating the levels of self-excitation as a stochastic differential equation. Our new point process allows better approximation in application domains where events and intensities accelerate each other with correlated levels of contagion. We generalize a recent algorithm for simulating draws from Hawkes processes whose levels of excitation are stochastic processes, and propose a hybrid Markov chain Monte Carlo approach for model fitting. Our sampling procedure scales linearly with the number of required events and does not require stationarity of the point process. A modular inference procedure consisting of a combination between Gibbs and Metropolis Hastings steps is put forward. We recover expectation maximization as a special case. Our general approach is illustrated for contagion following geometric Brownian motion and exponential Langevin dynamics.
* Copy of ICML paper
Bibliographic Analysis with the Citation Network Topic Model
Sep 22, 2016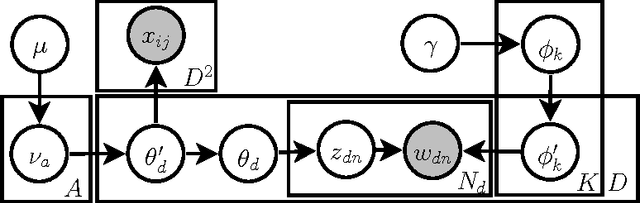
Bibliographic analysis considers author's research areas, the citation network and paper content among other things. In this paper, we combine these three in a topic model that produces a bibliographic model of authors, topics and documents using a non-parametric extension of a combination of the Poisson mixed-topic link model and the author-topic model. We propose a novel and efficient inference algorithm for the model to explore subsets of research publications from CiteSeerX. Our model demonstrates improved performance in both model fitting and a clustering task compared to several baselines.
* A copy of ACML paper. arXiv admin note: substantial text overlap with arXiv:1609.06532
Twitter-Network Topic Model: A Full Bayesian Treatment for Social Network and Text Modeling
Sep 22, 2016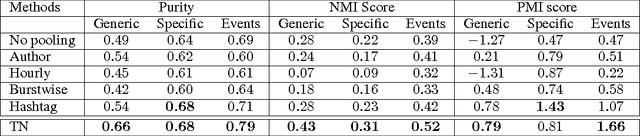
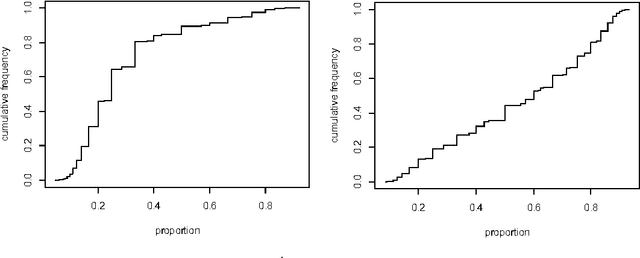


Twitter data is extremely noisy -- each tweet is short, unstructured and with informal language, a challenge for current topic modeling. On the other hand, tweets are accompanied by extra information such as authorship, hashtags and the user-follower network. Exploiting this additional information, we propose the Twitter-Network (TN) topic model to jointly model the text and the social network in a full Bayesian nonparametric way. The TN topic model employs the hierarchical Poisson-Dirichlet processes (PDP) for text modeling and a Gaussian process random function model for social network modeling. We show that the TN topic model significantly outperforms several existing nonparametric models due to its flexibility. Moreover, the TN topic model enables additional informative inference such as authors' interests, hashtag analysis, as well as leading to further applications such as author recommendation, automatic topic labeling and hashtag suggestion. Note our general inference framework can readily be applied to other topic models with embedded PDP nodes.
* NIPS workshop paper
Nonparametric Bayesian Topic Modelling with the Hierarchical Pitman-Yor Processes
Sep 22, 2016



The Dirichlet process and its extension, the Pitman-Yor process, are stochastic processes that take probability distributions as a parameter. These processes can be stacked up to form a hierarchical nonparametric Bayesian model. In this article, we present efficient methods for the use of these processes in this hierarchical context, and apply them to latent variable models for text analytics. In particular, we propose a general framework for designing these Bayesian models, which are called topic models in the computer science community. We then propose a specific nonparametric Bayesian topic model for modelling text from social media. We focus on tweets (posts on Twitter) in this article due to their ease of access. We find that our nonparametric model performs better than existing parametric models in both goodness of fit and real world applications.
* Preprint for International Journal of Approximate Reasoning
Twitter Opinion Topic Model: Extracting Product Opinions from Tweets by Leveraging Hashtags and Sentiment Lexicon
Sep 21, 2016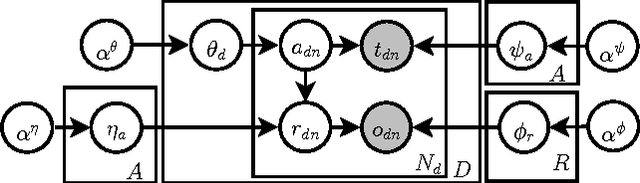
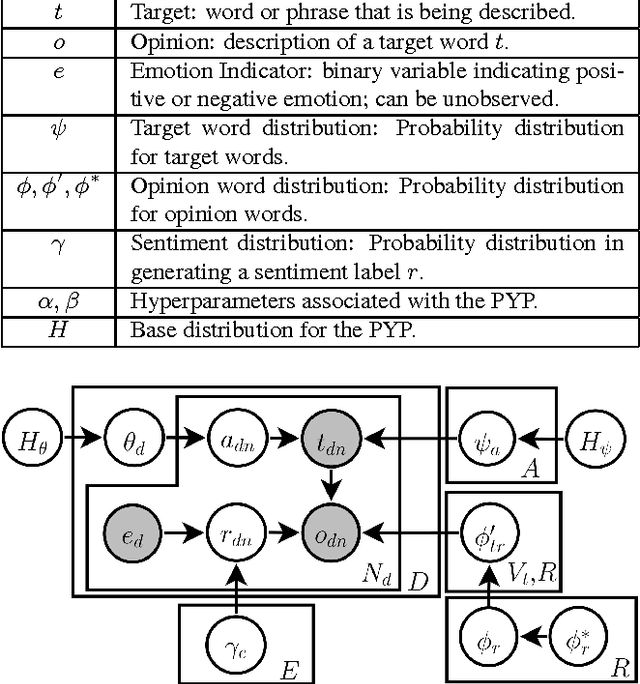

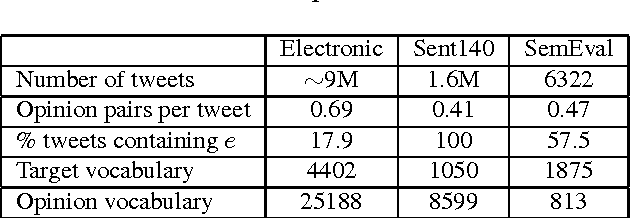
Aspect-based opinion mining is widely applied to review data to aggregate or summarize opinions of a product, and the current state-of-the-art is achieved with Latent Dirichlet Allocation (LDA)-based model. Although social media data like tweets are laden with opinions, their "dirty" nature (as natural language) has discouraged researchers from applying LDA-based opinion model for product review mining. Tweets are often informal, unstructured and lacking labeled data such as categories and ratings, making it challenging for product opinion mining. In this paper, we propose an LDA-based opinion model named Twitter Opinion Topic Model (TOTM) for opinion mining and sentiment analysis. TOTM leverages hashtags, mentions, emoticons and strong sentiment words that are present in tweets in its discovery process. It improves opinion prediction by modeling the target-opinion interaction directly, thus discovering target specific opinion words, neglected in existing approaches. Moreover, we propose a new formulation of incorporating sentiment prior information into a topic model, by utilizing an existing public sentiment lexicon. This is novel in that it learns and updates with the data. We conduct experiments on 9 million tweets on electronic products, and demonstrate the improved performance of TOTM in both quantitative evaluations and qualitative analysis. We show that aspect-based opinion analysis on massive volume of tweets provides useful opinions on products.
* CIKM paper
Bibliographic Analysis on Research Publications using Authors, Categorical Labels and the Citation Network
Sep 21, 2016
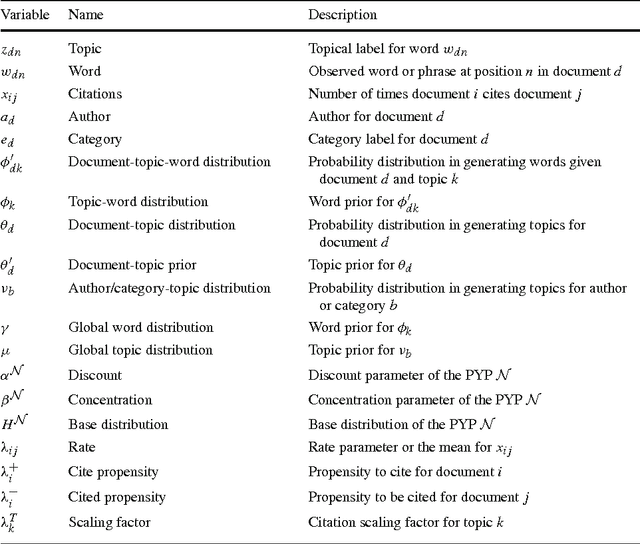


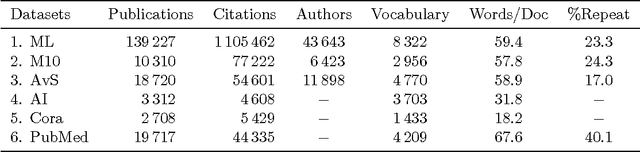
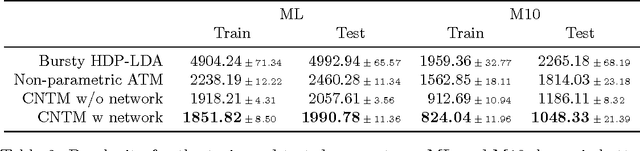
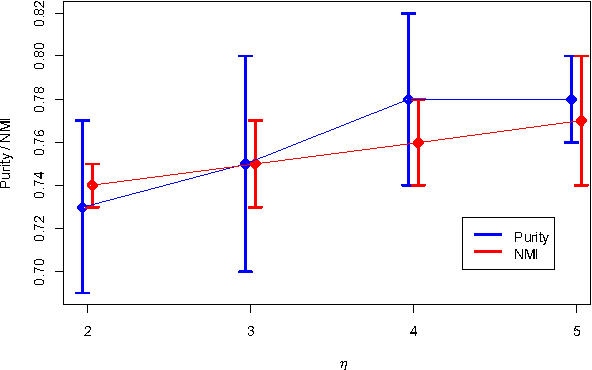
Bibliographic analysis considers the author's research areas, the citation network and the paper content among other things. In this paper, we combine these three in a topic model that produces a bibliographic model of authors, topics and documents, using a nonparametric extension of a combination of the Poisson mixed-topic link model and the author-topic model. This gives rise to the Citation Network Topic Model (CNTM). We propose a novel and efficient inference algorithm for the CNTM to explore subsets of research publications from CiteSeerX. The publication datasets are organised into three corpora, totalling to about 168k publications with about 62k authors. The queried datasets are made available online. In three publicly available corpora in addition to the queried datasets, our proposed model demonstrates an improved performance in both model fitting and document clustering, compared to several baselines. Moreover, our model allows extraction of additional useful knowledge from the corpora, such as the visualisation of the author-topics network. Additionally, we propose a simple method to incorporate supervision into topic modelling to achieve further improvement on the clustering task.
* Preprint for Journal Machine Learning