 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniNet: A Unified Multi-granular Traffic Modeling Framework for Network Security
Mar 06, 2025



As modern networks grow increasingly complex--driven by diverse devices, encrypted protocols, and evolving threats--network traffic analysis has become critically important. Existing machine learning models often rely only on a single representation of packets or flows, limiting their ability to capture the contextual relationships essential for robust analysis. Furthermore, task-specific architectures for supervised, semi-supervised, and unsupervised learning lead to inefficiencies in adapting to varying data formats and security tasks. To address these gaps, we propose UniNet, a unified framework that introduces a novel multi-granular traffic representation (T-Matrix), integrating session, flow, and packet-level features to provide comprehensive contextual information. Combined with T-Attent, a lightweight attention-based model, UniNet efficiently learns latent embeddings for diverse security tasks. Extensive evaluations across four key network security and privacy problems--anomaly detection, attack classification, IoT device identification, and encrypted website fingerprinting--demonstrate UniNet's significant performance gain over state-of-the-art methods, achieving higher accuracy, lower false positive rates, and improved scalability. By addressing the limitations of single-level models and unifying traffic analysis paradigms, UniNet sets a new benchmark for modern network security.
Multimodal Large Language Models for Phishing Webpage Detection and Identification
Aug 12, 2024


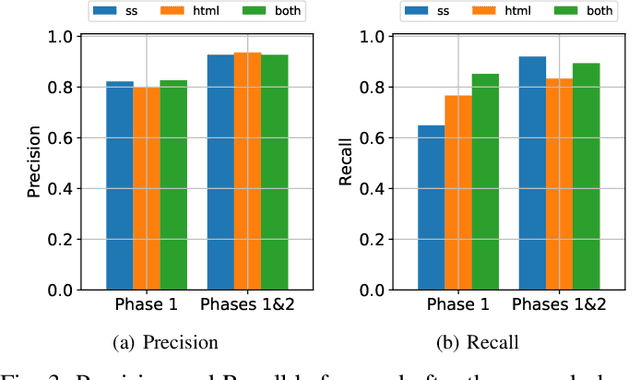
To address the challenging problem of detecting phishing webpages, researchers have developed numerous solutions, in particular those based on machine learning (ML) algorithms. Among these, brand-based phishing detection that uses models from Computer Vision to detect if a given webpage is imitating a well-known brand has received widespread attention. However, such models are costly and difficult to maintain, as they need to be retrained with labeled dataset that has to be regularly and continuously collected. Besides, they also need to maintain a good reference list of well-known websites and related meta-data for effective performance. In this work, we take steps to study the efficacy of large language models (LLMs), in particular the multimodal LLMs, in detecting phishing webpages. Given that the LLMs are pretrained on a large corpus of data, we aim to make use of their understanding of different aspects of a webpage (logo, theme, favicon, etc.) to identify the brand of a given webpage and compare the identified brand with the domain name in the URL to detect a phishing attack. We propose a two-phase system employing LLMs in both phases: the first phase focuses on brand identification, while the second verifies the domain. We carry out comprehensive evaluations on a newly collected dataset. Our experiments show that the LLM-based system achieves a high detection rate at high precision; importantly, it also provides interpretable evidence for the decisions. Our system also performs significantly better than a state-of-the-art brand-based phishing detection system while demonstrating robustness against two known adversarial attacks.
ZEST: Attention-based Zero-Shot Learning for Unseen IoT Device Classification
Oct 12, 2023Recent research works have proposed machine learning models for classifying IoT devices connected to a network. However, there is still a practical challenge of not having all devices (and hence their traffic) available during the training of a model. This essentially means, during the operational phase, we need to classify new devices not seen during the training phase. To address this challenge, we propose ZEST -- a ZSL (zero-shot learning) framework based on self-attention for classifying both seen and unseen devices. ZEST consists of i) a self-attention based network feature extractor, termed SANE, for extracting latent space representations of IoT traffic, ii) a generative model that trains a decoder using latent features to generate pseudo data, and iii) a supervised model that is trained on the generated pseudo data for classifying devices. We carry out extensive experiments on real IoT traffic data; our experiments demonstrate i) ZEST achieves significant improvement (in terms of accuracy) over the baselines; ii) ZEST is able to better extract meaningful representations than LSTM which has been commonly used for modeling network traffic.
Markov Chain Monte Carlo-Based Machine Unlearning: Unlearning What Needs to be Forgotten
Feb 28, 2022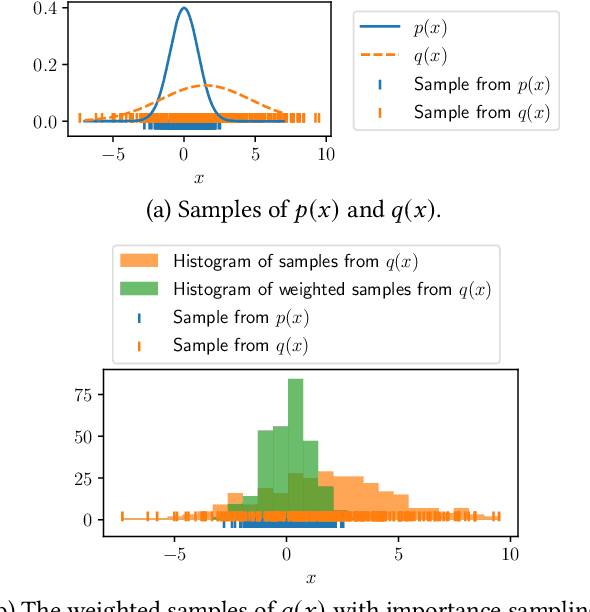
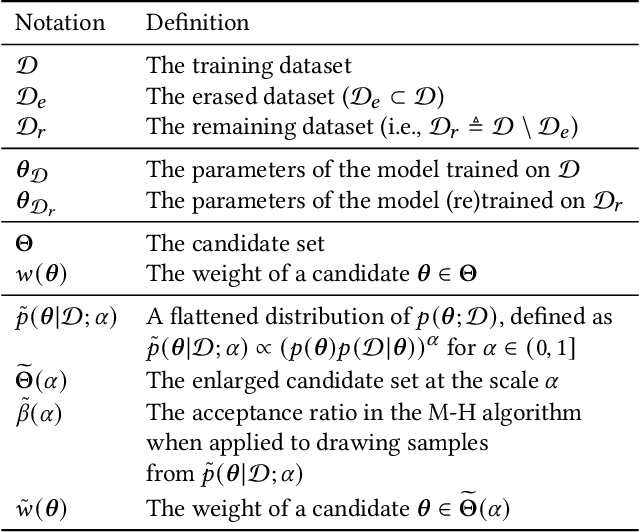
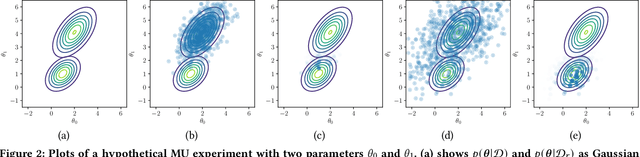

As the use of machine learning (ML) models is becoming increasingly popular in many real-world applications, there are practical challenges that need to be addressed for model maintenance. One such challenge is to 'undo' the effect of a specific subset of dataset used for training a model. This specific subset may contain malicious or adversarial data injected by an attacker, which affects the model performance. Another reason may be the need for a service provider to remove data pertaining to a specific user to respect the user's privacy. In both cases, the problem is to 'unlearn' a specific subset of the training data from a trained model without incurring the costly procedure of retraining the whole model from scratch. Towards this goal, this paper presents a Markov chain Monte Carlo-based machine unlearning (MCU) algorithm. MCU helps to effectively and efficiently unlearn a trained model from subsets of training dataset. Furthermore, we show that with MCU, we are able to explain the effect of a subset of a training dataset on the model prediction. Thus, MCU is useful for examining subsets of data to identify the adversarial data to be removed. Similarly, MCU can be used to erase the lineage of a user's personal data from trained ML models, thus upholding a user's "right to be forgotten". We empirically evaluate the performance of our proposed MCU algorithm on real-world phishing and diabetes datasets. Results show that MCU can achieve a desirable performance by efficiently removing the effect of a subset of training dataset and outperform an existing algorithm that utilizes the remaining dataset.
Cost-aware Feature Selection for IoT Device Classification
Sep 02, 2020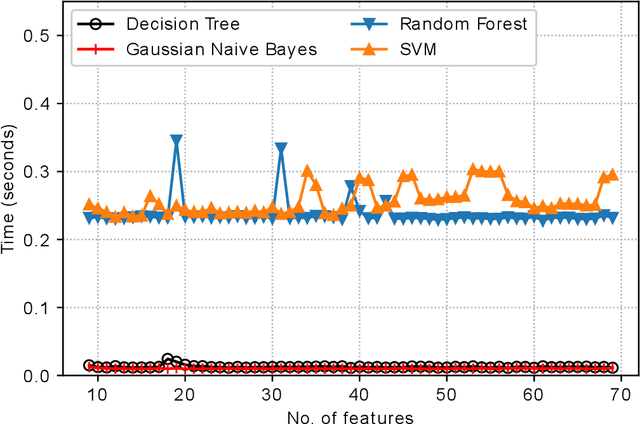
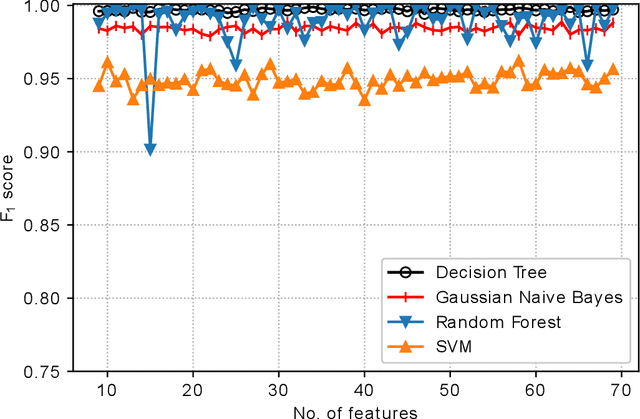
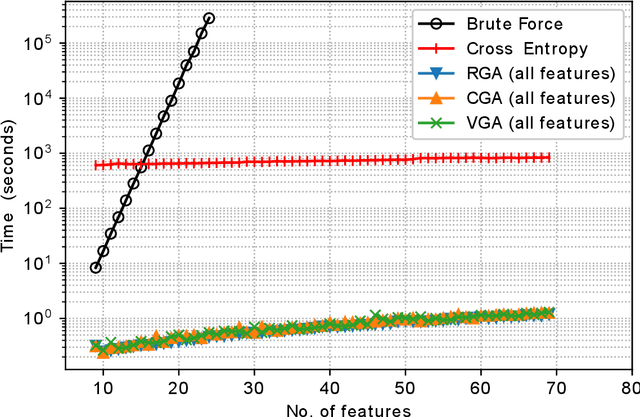
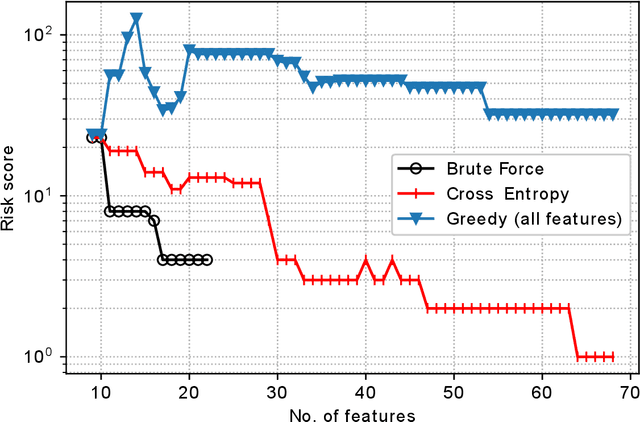
Classification of IoT devices into different types is of paramount importance, from multiple perspectives, including security and privacy aspects. Recent works have explored machine learning techniques for fingerprinting (or classifying) IoT devices, with promising results. However, existing works have assumed that the features used for building the machine learning models are readily available or can be easily extracted from the network traffic; in other words, they do not consider the costs associated with feature extraction. In this work, we take a more realistic approach, and argue that feature extraction has a cost, and the costs are different for different features. We also take a step forward from the current practice of considering the misclassification loss as a binary value, and make a case for different losses based on the misclassification performance. Thereby, and more importantly, we introduce the notion of risk for IoT device classification. We define and formulate the problem of cost-aware IoT device classification. This being a combinatorial optimization problem, we develop a novel algorithm to solve it in a fast and effective way using the Cross-Entropy (CE) based stochastic optimization technique. Using traffic of real devices, we demonstrate the capability of the CE based algorithm in selecting features with minimal risk of misclassification while keeping the cost for feature extraction within a specified limit.
GEE: A Gradient-based Explainable Variational Autoencoder for Network Anomaly Detection
Mar 15, 2019
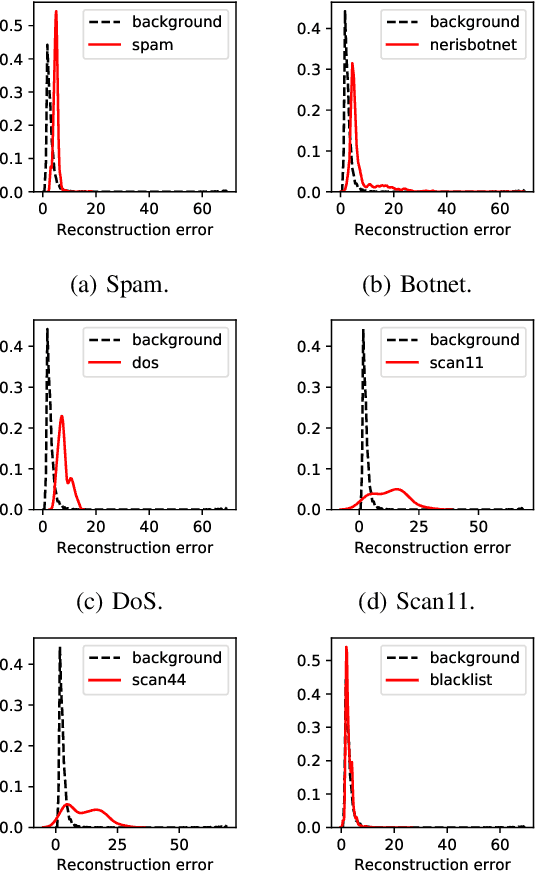
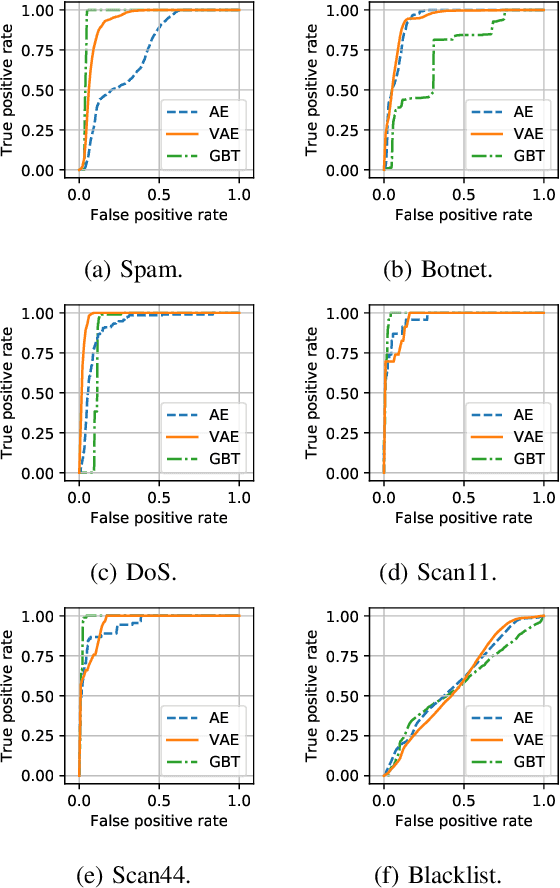
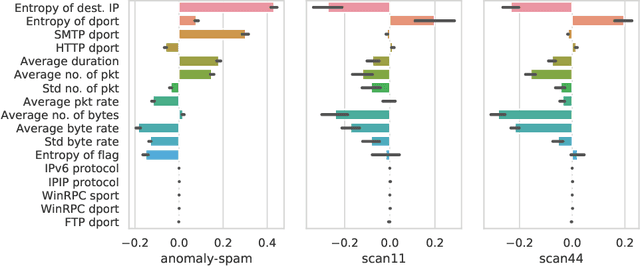
This paper looks into the problem of detecting network anomalies by analyzing NetFlow records. While many previous works have used statistical models and machine learning techniques in a supervised way, such solutions have the limitations that they require large amount of labeled data for training and are unlikely to detect zero-day attacks. Existing anomaly detection solutions also do not provide an easy way to explain or identify attacks in the anomalous traffic. To address these limitations, we develop and present GEE, a framework for detecting and explaining anomalies in network traffic. GEE comprises of two components: (i) Variational Autoencoder (VAE) - an unsupervised deep-learning technique for detecting anomalies, and (ii) a gradient-based fingerprinting technique for explaining anomalies. Evaluation of GEE on the recent UGR dataset demonstrates that our approach is effective in detecting different anomalies as well as identifying fingerprints that are good representations of these various attacks.