 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUPRE: Data Utility Prediction for Efficient Data Valuation
Feb 22, 2025Data valuation is increasingly used in machine learning (ML) to decide the fair compensation for data owners and identify valuable or harmful data for improving ML models. Cooperative game theory-based data valuation, such as Data Shapley, requires evaluating the data utility (e.g., validation accuracy) and retraining the ML model for multiple data subsets. While most existing works on efficient estimation of the Shapley values have focused on reducing the number of subsets to evaluate, our framework, \texttt{DUPRE}, takes an alternative yet complementary approach that reduces the cost per subset evaluation by predicting data utilities instead of evaluating them by model retraining. Specifically, given the evaluated data utilities of some data subsets, \texttt{DUPRE} fits a \emph{Gaussian process} (GP) regression model to predict the utility of every other data subset. Our key contribution lies in the design of our GP kernel based on the sliced Wasserstein distance between empirical data distributions. In particular, we show that the kernel is valid and positive semi-definite, encodes prior knowledge of similarities between different data subsets, and can be efficiently computed. We empirically verify that \texttt{DUPRE} introduces low prediction error and speeds up data valuation for various ML models, datasets, and utility functions.
BILBO: BILevel Bayesian Optimization
Feb 04, 2025



Bilevel optimization is characterized by a two-level optimization structure, where the upper-level problem is constrained by optimal lower-level solutions, and such structures are prevalent in real-world problems. The constraint by optimal lower-level solutions poses significant challenges, especially in noisy, constrained, and derivative-free settings, as repeating lower-level optimizations is sample inefficient and predicted lower-level solutions may be suboptimal. We present BILevel Bayesian Optimization (BILBO), a novel Bayesian optimization algorithm for general bilevel problems with blackbox functions, which optimizes both upper- and lower-level problems simultaneously, without the repeated lower-level optimization required by existing methods. BILBO samples from confidence-bounds based trusted sets, which bounds the suboptimality on the lower level. Moreover, BILBO selects only one function query per iteration, where the function query selection strategy incorporates the uncertainty of estimated lower-level solutions and includes a conditional reassignment of the query to encourage exploration of the lower-level objective. The performance of BILBO is theoretically guaranteed with a sublinear regret bound for commonly used kernels and is empirically evaluated on several synthetic and real-world problems.
Batch Bayesian Optimization for Replicable Experimental Design
Nov 02, 2023



Many real-world experimental design problems (a) evaluate multiple experimental conditions in parallel and (b) replicate each condition multiple times due to large and heteroscedastic observation noise. Given a fixed total budget, this naturally induces a trade-off between evaluating more unique conditions while replicating each of them fewer times vs. evaluating fewer unique conditions and replicating each more times. Moreover, in these problems, practitioners may be risk-averse and hence prefer an input with both good average performance and small variability. To tackle both challenges, we propose the Batch Thompson Sampling for Replicable Experimental Design (BTS-RED) framework, which encompasses three algorithms. Our BTS-RED-Known and BTS-RED-Unknown algorithms, for, respectively, known and unknown noise variance, choose the number of replications adaptively rather than deterministically such that an input with a larger noise variance is replicated more times. As a result, despite the noise heteroscedasticity, both algorithms enjoy a theoretical guarantee and are asymptotically no-regret. Our Mean-Var-BTS-RED algorithm aims at risk-averse optimization and is also asymptotically no-regret. We also show the effectiveness of our algorithms in two practical real-world applications: precision agriculture and AutoML.
Rectified Max-Value Entropy Search for Bayesian Optimization
Feb 28, 2022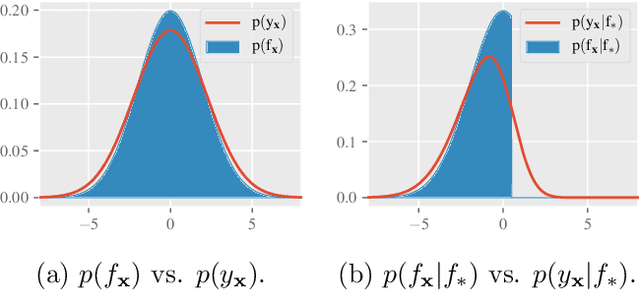

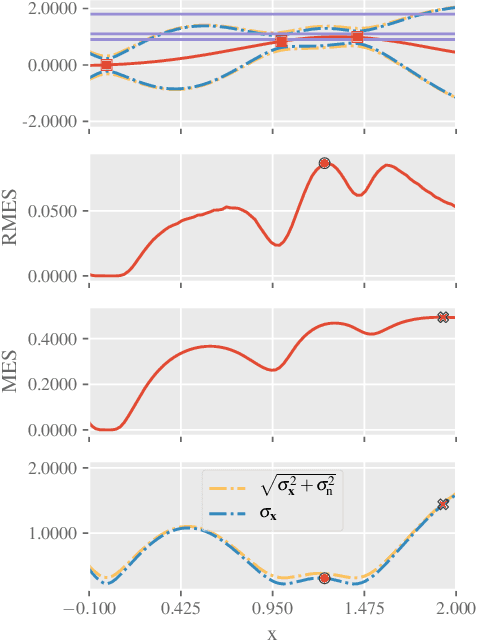
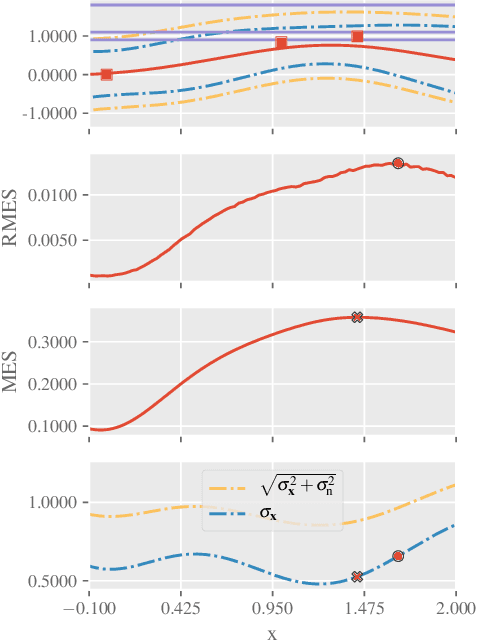
Although the existing max-value entropy search (MES) is based on the widely celebrated notion of mutual information, its empirical performance can suffer due to two misconceptions whose implications on the exploration-exploitation trade-off are investigated in this paper. These issues are essential in the development of future acquisition functions and the improvement of the existing ones as they encourage an accurate measure of the mutual information such as the rectified MES (RMES) acquisition function we develop in this work. Unlike the evaluation of MES, we derive a closed-form probability density for the observation conditioned on the max-value and employ stochastic gradient ascent with reparameterization to efficiently optimize RMES. As a result of a more principled acquisition function, RMES shows a consistent improvement over MES in several synthetic function benchmarks and real-world optimization problems.
Markov Chain Monte Carlo-Based Machine Unlearning: Unlearning What Needs to be Forgotten
Feb 28, 2022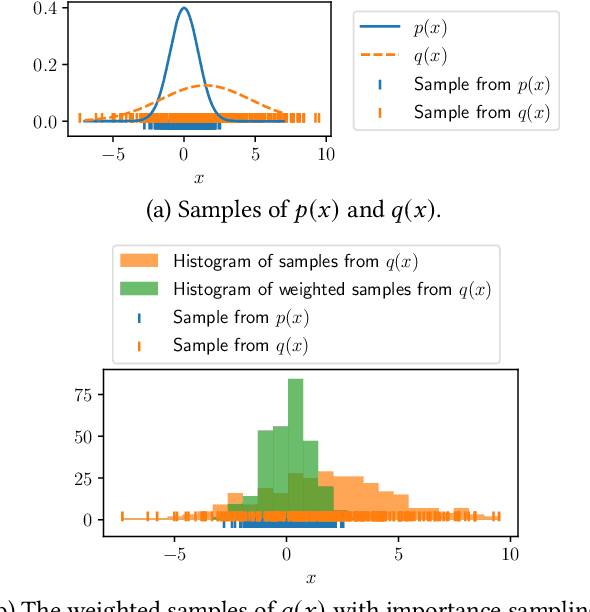
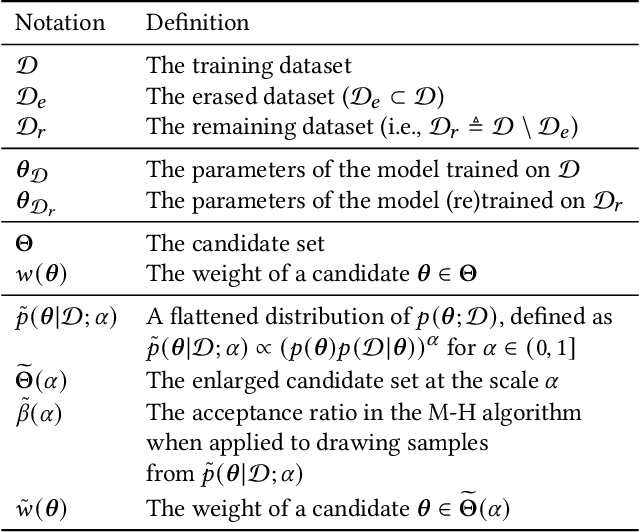
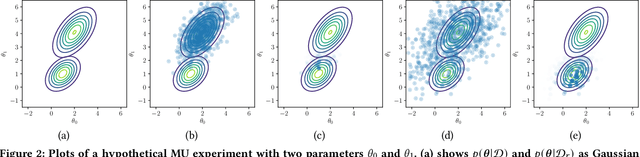

As the use of machine learning (ML) models is becoming increasingly popular in many real-world applications, there are practical challenges that need to be addressed for model maintenance. One such challenge is to 'undo' the effect of a specific subset of dataset used for training a model. This specific subset may contain malicious or adversarial data injected by an attacker, which affects the model performance. Another reason may be the need for a service provider to remove data pertaining to a specific user to respect the user's privacy. In both cases, the problem is to 'unlearn' a specific subset of the training data from a trained model without incurring the costly procedure of retraining the whole model from scratch. Towards this goal, this paper presents a Markov chain Monte Carlo-based machine unlearning (MCU) algorithm. MCU helps to effectively and efficiently unlearn a trained model from subsets of training dataset. Furthermore, we show that with MCU, we are able to explain the effect of a subset of a training dataset on the model prediction. Thus, MCU is useful for examining subsets of data to identify the adversarial data to be removed. Similarly, MCU can be used to erase the lineage of a user's personal data from trained ML models, thus upholding a user's "right to be forgotten". We empirically evaluate the performance of our proposed MCU algorithm on real-world phishing and diabetes datasets. Results show that MCU can achieve a desirable performance by efficiently removing the effect of a subset of training dataset and outperform an existing algorithm that utilizes the remaining dataset.
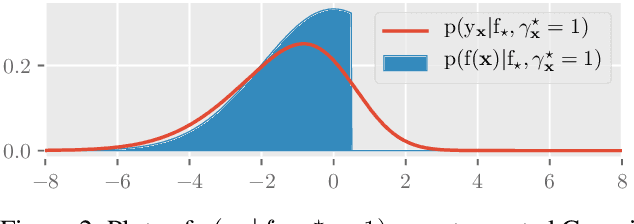
Trusted-Maximizers Entropy Search for Efficient Bayesian Optimization
Jul 30, 2021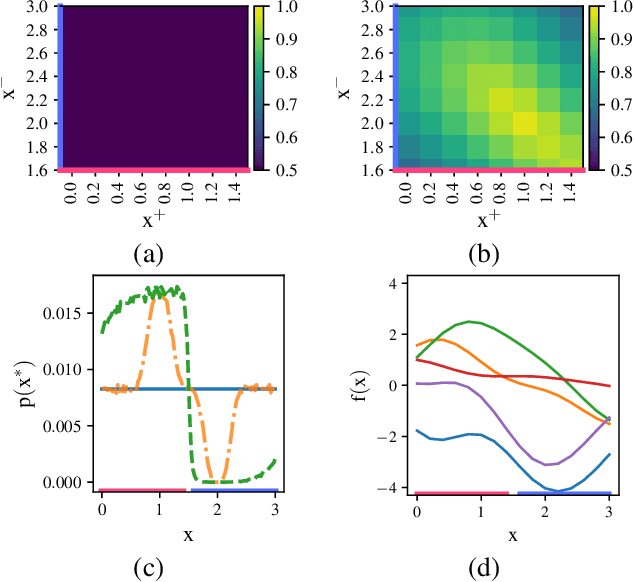
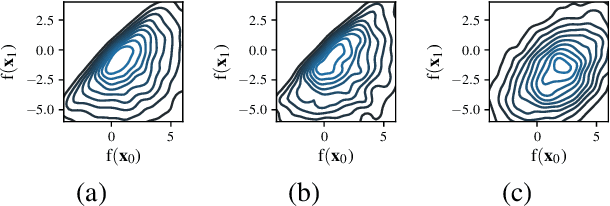
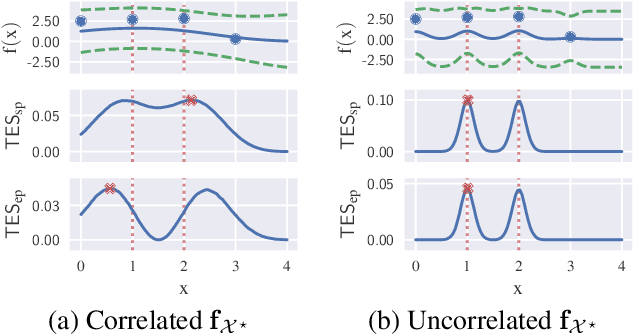
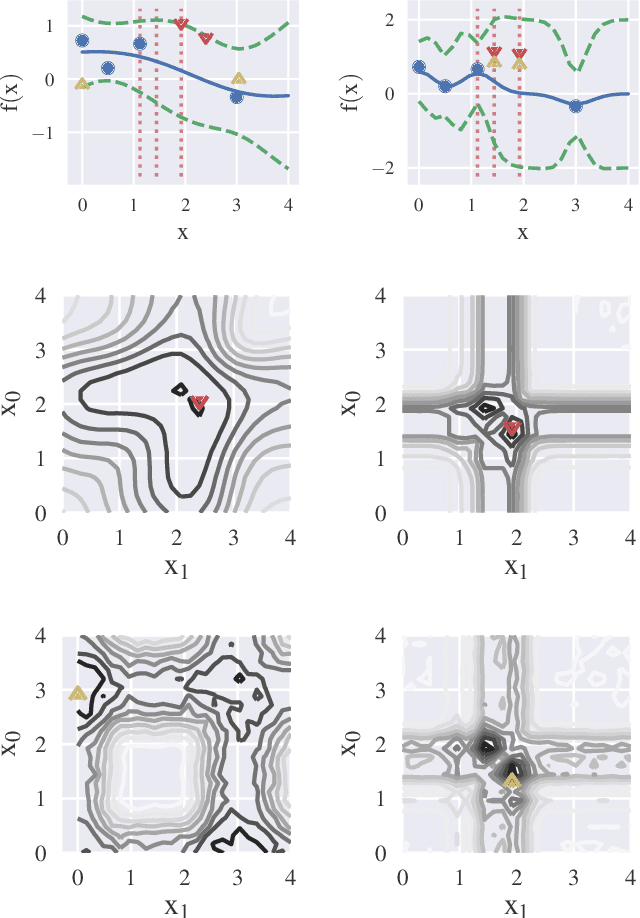
Information-based Bayesian optimization (BO) algorithms have achieved state-of-the-art performance in optimizing a black-box objective function. However, they usually require several approximations or simplifying assumptions (without clearly understanding their effects on the BO performance) and/or their generalization to batch BO is computationally unwieldy, especially with an increasing batch size. To alleviate these issues, this paper presents a novel trusted-maximizers entropy search (TES) acquisition function: It measures how much an input query contributes to the information gain on the maximizer over a finite set of trusted maximizers, i.e., inputs optimizing functions that are sampled from the Gaussian process posterior belief of the objective function. Evaluating TES requires either only a stochastic approximation with sampling or a deterministic approximation with expectation propagation, both of which are investigated and empirically evaluated using synthetic benchmark objective functions and real-world optimization problems, e.g., hyperparameter tuning of a convolutional neural network and synthesizing 'physically realizable' faces to fool a black-box face recognition system. Though TES can naturally be generalized to a batch variant with either approximation, the latter is amenable to be scaled to a much larger batch size in our experiments.
Value-at-Risk Optimization with Gaussian Processes
May 13, 2021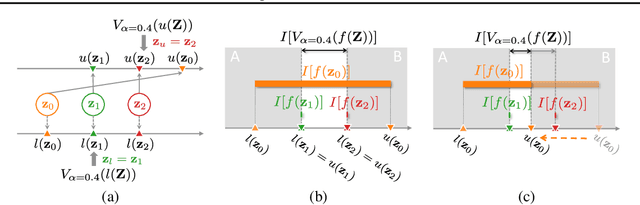

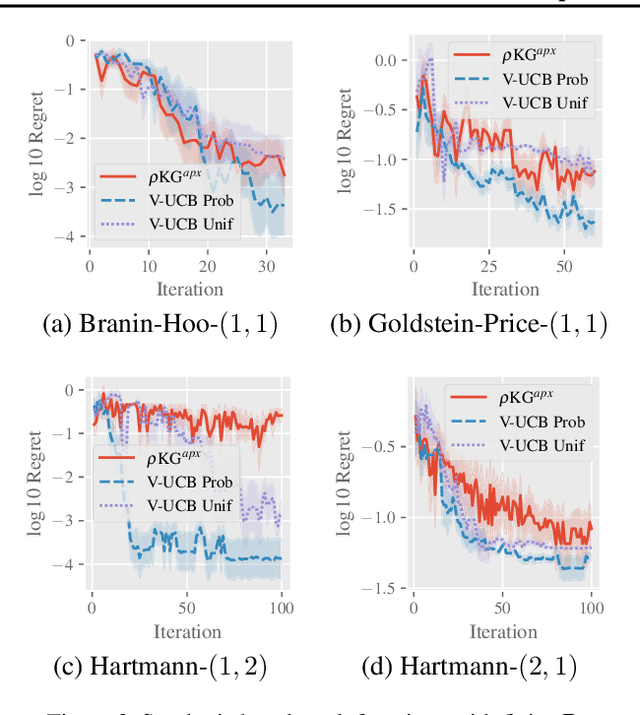

Value-at-risk (VaR) is an established measure to assess risks in critical real-world applications with random environmental factors. This paper presents a novel VaR upper confidence bound (V-UCB) algorithm for maximizing the VaR of a black-box objective function with the first no-regret guarantee. To realize this, we first derive a confidence bound of VaR and then prove the existence of values of the environmental random variable (to be selected to achieve no regret) such that the confidence bound of VaR lies within that of the objective function evaluated at such values. Our V-UCB algorithm empirically demonstrates state-of-the-art performance in optimizing synthetic benchmark functions, a portfolio optimization problem, and a simulated robot task.
An Information-Theoretic Framework for Unifying Active Learning Problems
Dec 19, 2020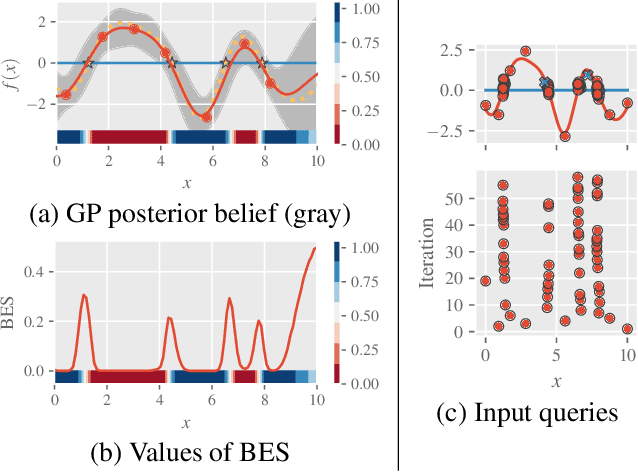
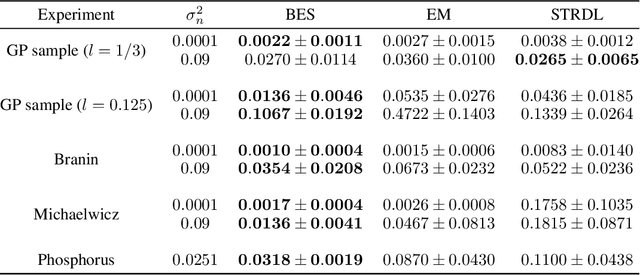

This paper presents an information-theoretic framework for unifying active learning problems: level set estimation (LSE), Bayesian optimization (BO), and their generalized variant. We first introduce a novel active learning criterion that subsumes an existing LSE algorithm and achieves state-of-the-art performance in LSE problems with a continuous input domain. Then, by exploiting the relationship between LSE and BO, we design a competitive information-theoretic acquisition function for BO that has interesting connections to upper confidence bound and max-value entropy search (MES). The latter connection reveals a drawback of MES which has important implications on not only MES but also on other MES-based acquisition functions. Finally, our unifying information-theoretic framework can be applied to solve a generalized problem of LSE and BO involving multiple level sets in a data-efficient manner. We empirically evaluate the performance of our proposed algorithms using synthetic benchmark functions, a real-world dataset, and in hyperparameter tuning of machine learning models.
Top-$k$ Ranking Bayesian Optimization
Dec 19, 2020
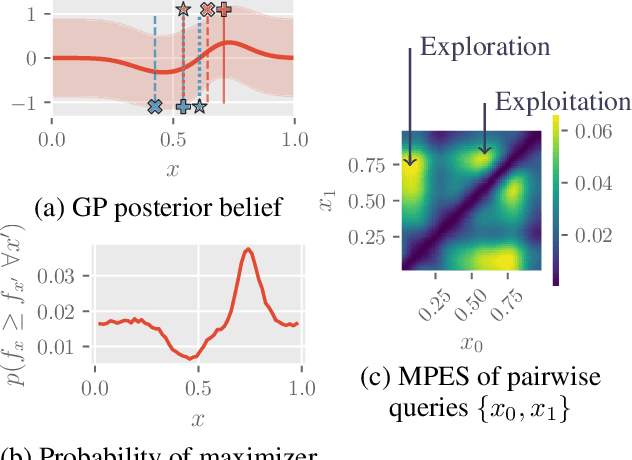
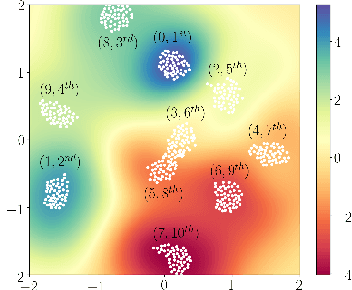
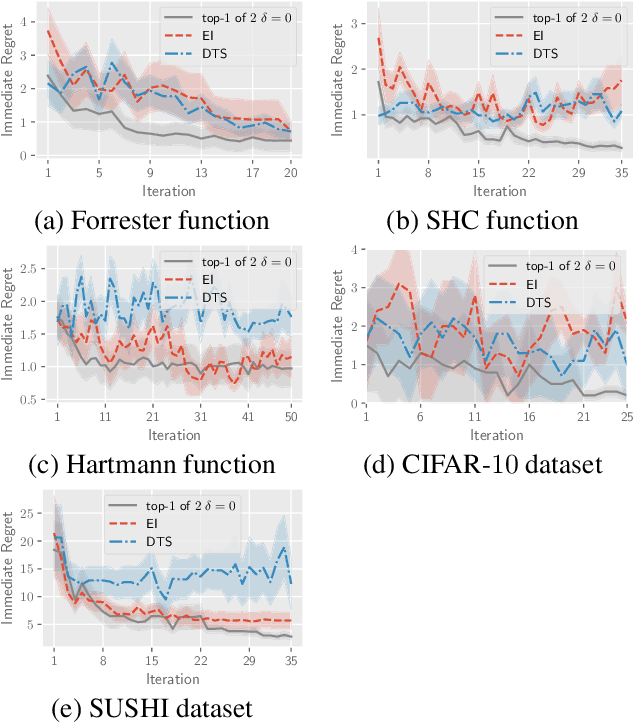
This paper presents a novel approach to top-$k$ ranking Bayesian optimization (top-$k$ ranking BO) which is a practical and significant generalization of preferential BO to handle top-$k$ ranking and tie/indifference observations. We first design a surrogate model that is not only capable of catering to the above observations, but is also supported by a classic random utility model. Another equally important contribution is the introduction of the first information-theoretic acquisition function in BO with preferential observation called multinomial predictive entropy search (MPES) which is flexible in handling these observations and optimized for all inputs of a query jointly. MPES possesses superior performance compared with existing acquisition functions that select the inputs of a query one at a time greedily. We empirically evaluate the performance of MPES using several synthetic benchmark functions, CIFAR-$10$ dataset, and SUSHI preference dataset.
Efficient Exploration of Reward Functions in Inverse Reinforcement Learning via Bayesian Optimization
Nov 17, 2020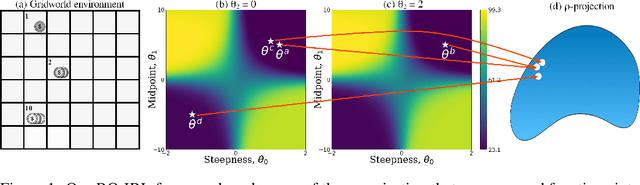
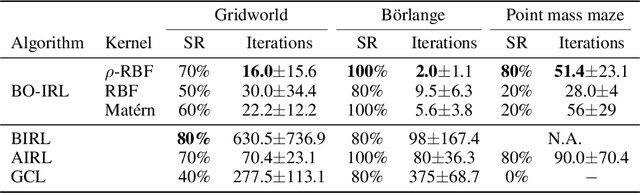

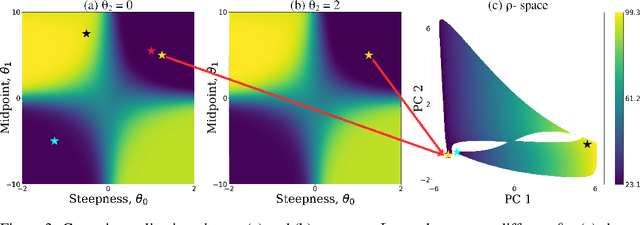
The problem of inverse reinforcement learning (IRL) is relevant to a variety of tasks including value alignment and robot learning from demonstration. Despite significant algorithmic contributions in recent years, IRL remains an ill-posed problem at its core; multiple reward functions coincide with the observed behavior and the actual reward function is not identifiable without prior knowledge or supplementary information. This paper presents an IRL framework called Bayesian optimization-IRL (BO-IRL) which identifies multiple solutions that are consistent with the expert demonstrations by efficiently exploring the reward function space. BO-IRL achieves this by utilizing Bayesian Optimization along with our newly proposed kernel that (a) projects the parameters of policy invariant reward functions to a single point in a latent space and (b) ensures nearby points in the latent space correspond to reward functions yielding similar likelihoods. This projection allows the use of standard stationary kernels in the latent space to capture the correlations present across the reward function space. Empirical results on synthetic and real-world environments (model-free and model-based) show that BO-IRL discovers multiple reward functions while minimizing the number of expensive exact policy optimizations.