 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALES: From Fairness Principles to Constrained Decision-Making
Sep 22, 2022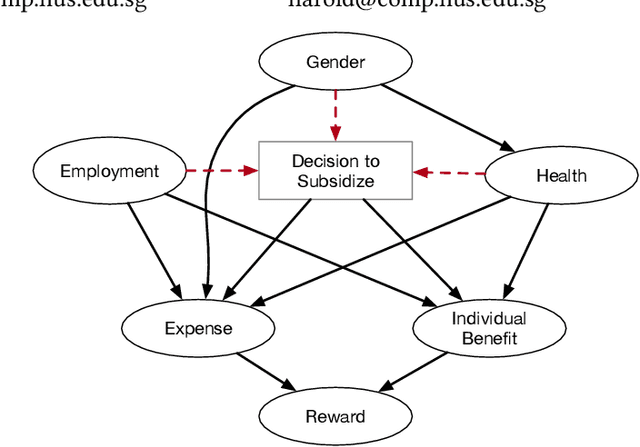
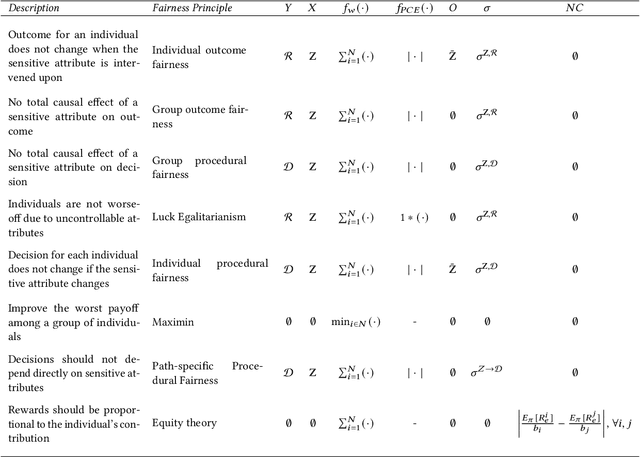

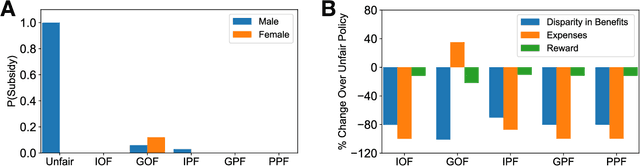
This paper proposes SCALES, a general framework that translates well-established fairness principles into a common representation based on the Constraint Markov Decision Process (CMDP). With the help of causal language, our framework can place constraints on both the procedure of decision making (procedural fairness) as well as the outcomes resulting from decisions (outcome fairness). Specifically, we show that well-known fairness principles can be encoded either as a utility component, a non-causal component, or a causal component in a SCALES-CMDP. We illustrate SCALES using a set of case studies involving a simulated healthcare scenario and the real-world COMPAS dataset. Experiments demonstrate that our framework produces fair policies that embody alternative fairness principles in single-step and sequential decision-making scenarios.
Efficient Exploration of Reward Functions in Inverse Reinforcement Learning via Bayesian Optimization
Nov 17, 2020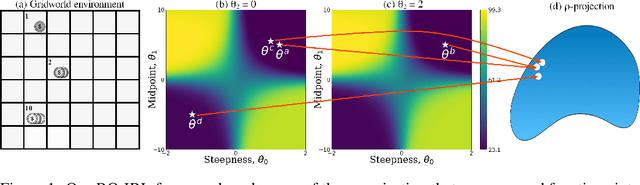
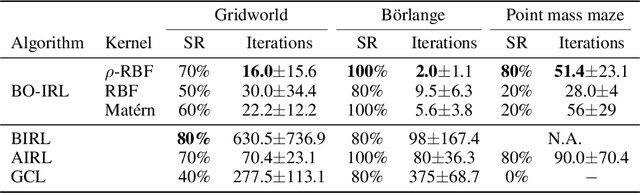

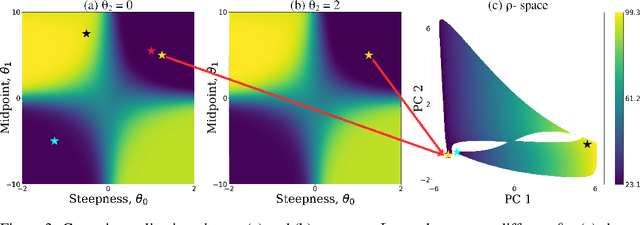
The problem of inverse reinforcement learning (IRL) is relevant to a variety of tasks including value alignment and robot learning from demonstration. Despite significant algorithmic contributions in recent years, IRL remains an ill-posed problem at its core; multiple reward functions coincide with the observed behavior and the actual reward function is not identifiable without prior knowledge or supplementary information. This paper presents an IRL framework called Bayesian optimization-IRL (BO-IRL) which identifies multiple solutions that are consistent with the expert demonstrations by efficiently exploring the reward function space. BO-IRL achieves this by utilizing Bayesian Optimization along with our newly proposed kernel that (a) projects the parameters of policy invariant reward functions to a single point in a latent space and (b) ensures nearby points in the latent space correspond to reward functions yielding similar likelihoods. This projection allows the use of standard stationary kernels in the latent space to capture the correlations present across the reward function space. Empirical results on synthetic and real-world environments (model-free and model-based) show that BO-IRL discovers multiple reward functions while minimizing the number of expensive exact policy optimizations.