 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback
Jul 23, 2025Tactile feedback is generally recognized to be crucial for effective interaction with the physical world. However, state-of-the-art Vision-Language-Action (VLA) models lack the ability to interpret and use tactile signals, limiting their effectiveness in contact-rich tasks. Incorporating tactile feedback into these systems is challenging due to the absence of large multi-modal datasets. We present VLA-Touch, an approach that enhances generalist robot policies with tactile sensing \emph{without fine-tuning} the base VLA. Our method introduces two key innovations: (1) a pipeline that leverages a pretrained tactile-language model that provides semantic tactile feedback for high-level task planning, and (2) a diffusion-based controller that refines VLA-generated actions with tactile signals for contact-rich manipulation. Through real-world experiments, we demonstrate that our dual-level integration of tactile feedback improves task planning efficiency while enhancing execution precision. Code is open-sourced at \href{https://github.com/jxbi1010/VLA-Touch}{this URL}.
Imitation Learning with Limited Actions via Diffusion Planners and Deep Koopman Controllers
Oct 10, 2024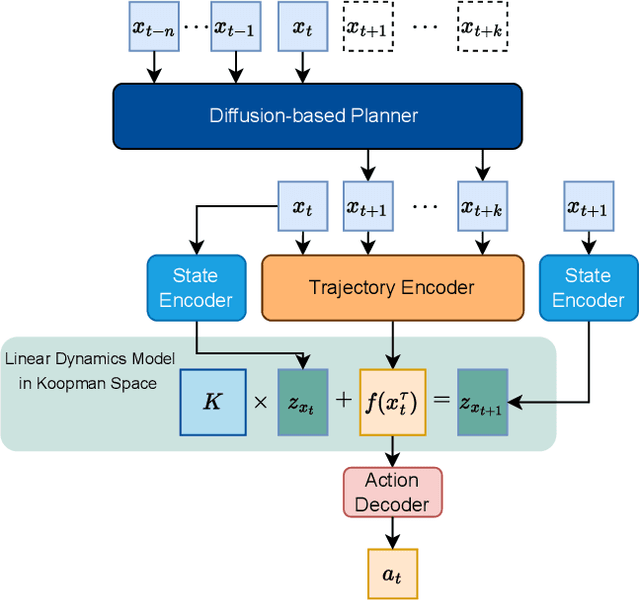
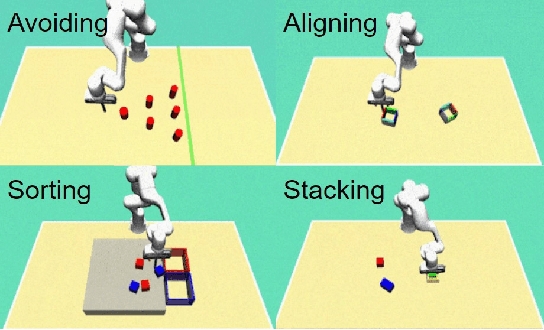
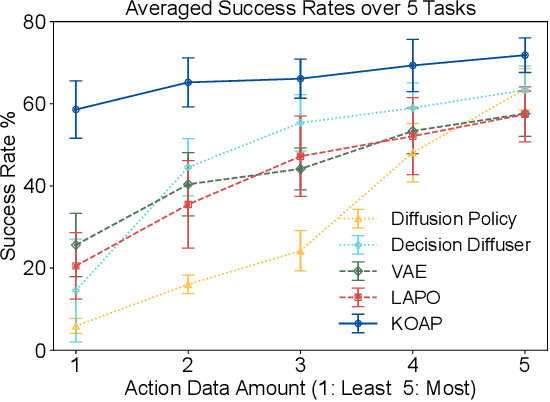
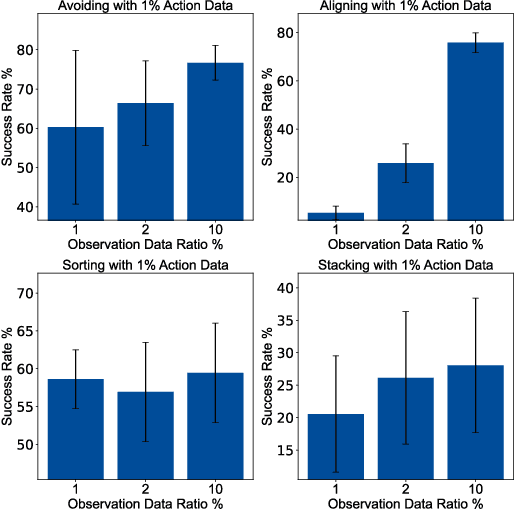
Recent advances in diffusion-based robot policies have demonstrated significant potential in imitating multi-modal behaviors. However, these approaches typically require large quantities of demonstration data paired with corresponding robot action labels, creating a substantial data collection burden. In this work, we propose a plan-then-control framework aimed at improving the action-data efficiency of inverse dynamics controllers by leveraging observational demonstration data. Specifically, we adopt a Deep Koopman Operator framework to model the dynamical system and utilize observation-only trajectories to learn a latent action representation. This latent representation can then be effectively mapped to real high-dimensional continuous actions using a linear action decoder, requiring minimal action-labeled data. Through experiments on simulated robot manipulation tasks and a real robot experiment with multi-modal expert demonstrations, we demonstrate that our approach significantly enhances action-data efficiency and achieves high task success rates with limited action data.
Safety-Constrained Policy Transfer with Successor Features
Nov 10, 2022
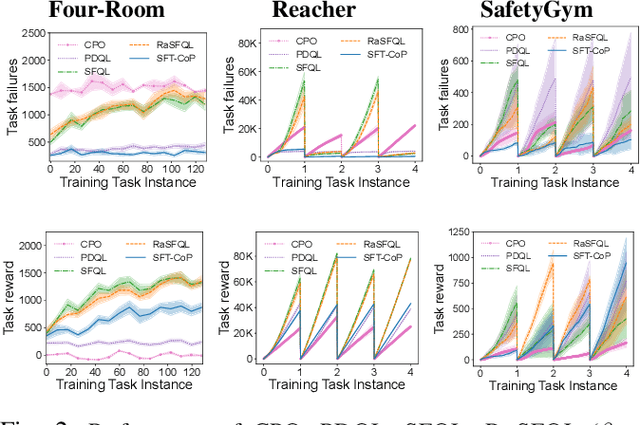


In this work, we focus on the problem of safe policy transfer in reinforcement learning: we seek to leverage existing policies when learning a new task with specified constraints. This problem is important for safety-critical applications where interactions are costly and unconstrained policies can lead to undesirable or dangerous outcomes, e.g., with physical robots that interact with humans. We propose a Constrained Markov Decision Process (CMDP) formulation that simultaneously enables the transfer of policies and adherence to safety constraints. Our formulation cleanly separates task goals from safety considerations and permits the specification of a wide variety of constraints. Our approach relies on a novel extension of generalized policy improvement to constrained settings via a Lagrangian formulation. We devise a dual optimization algorithm that estimates the optimal dual variable of a target task, thus enabling safe transfer of policies derived from successor features learned on source tasks. Our experiments in simulated domains show that our approach is effective; it visits unsafe states less frequently and outperforms alternative state-of-the-art methods when taking safety constraints into account.
SCALES: From Fairness Principles to Constrained Decision-Making
Sep 22, 2022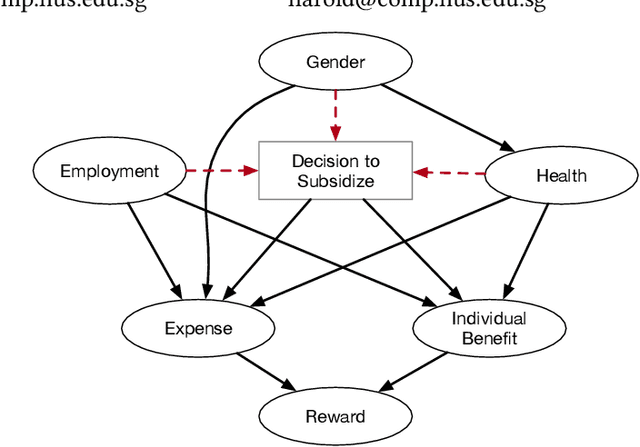
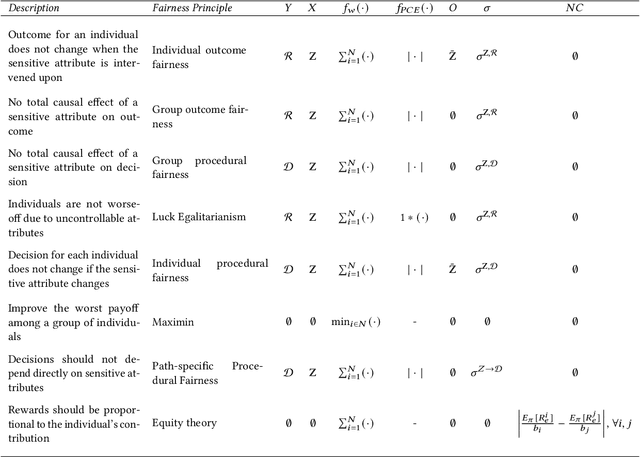

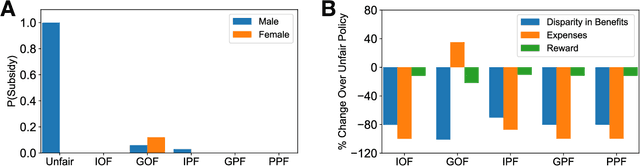
This paper proposes SCALES, a general framework that translates well-established fairness principles into a common representation based on the Constraint Markov Decision Process (CMDP). With the help of causal language, our framework can place constraints on both the procedure of decision making (procedural fairness) as well as the outcomes resulting from decisions (outcome fairness). Specifically, we show that well-known fairness principles can be encoded either as a utility component, a non-causal component, or a causal component in a SCALES-CMDP. We illustrate SCALES using a set of case studies involving a simulated healthcare scenario and the real-world COMPAS dataset. Experiments demonstrate that our framework produces fair policies that embody alternative fairness principles in single-step and sequential decision-making scenarios.