 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
Jun 18, 2026Embodied foundation models are expected to benefit from data scaling like large language models, but face a much tighter data bottleneck. Teleoperated real-robot trajectories remain the dominant pretraining source due to their precise action supervision and embodiment alignment, yet their scalability is limited by high collection cost, acquisition difficulty, and low behavioral and environmental diversity. These limitations have sparked interest in egocentric human video as a scalable, substantially lower-cost, and more diverse alternative for embodied model pretraining. However, its effectiveness compared to teleoperated real-robot data remains underexplored. To address this question, we conduct a systematic study comparing egocentric human video and teleoperated real-robot trajectories as pretraining data sources for embodied foundation models, under fixed post-training and validation protocols. Surprisingly, we find that egocentric data, when processed through a carefully designed filtering and labeling pipeline, is not merely a viable substitute for model pretraining but can lead to superior performance. With the same amount of pretraining data, models pretrained on egocentric data achieve a 24% lower validation loss on real-robot action prediction, as well as 52.5% and 90% higher success rates on in-distribution and out-of-distribution real-robot task execution, respectively. This finding verifies a scalable paradigm for embodied foundation models: pretrain on egocentric human video to learn diverse world representations, then adapt with a small amount of labeled real-robot data for action-space alignment. We hope this study encourages broader exploration of egocentric data and offers guidance for data quality assessment before costly robot data collection.
Imitation Learning with Limited Actions via Diffusion Planners and Deep Koopman Controllers
Oct 10, 2024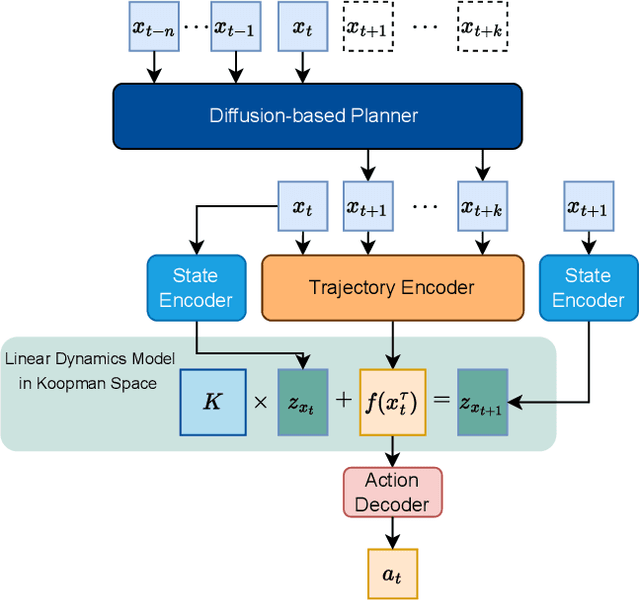
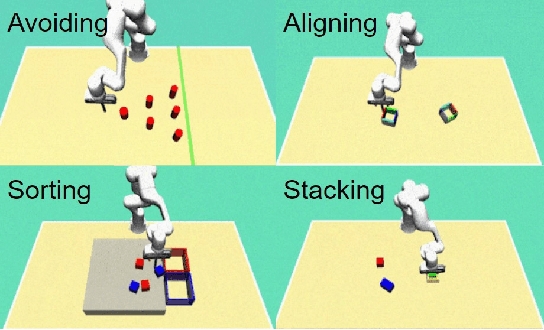
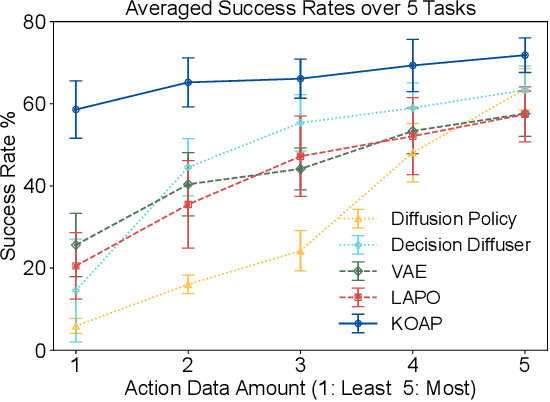
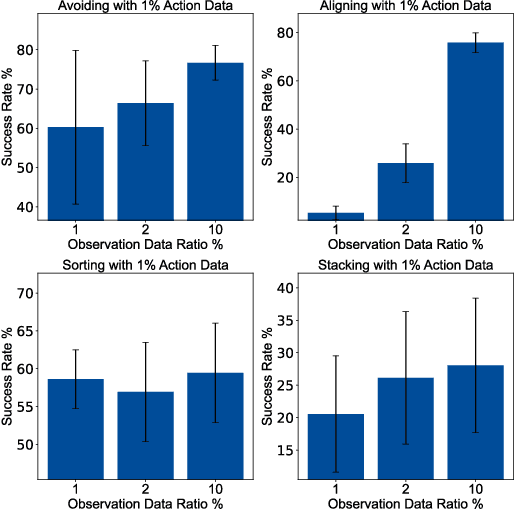
Recent advances in diffusion-based robot policies have demonstrated significant potential in imitating multi-modal behaviors. However, these approaches typically require large quantities of demonstration data paired with corresponding robot action labels, creating a substantial data collection burden. In this work, we propose a plan-then-control framework aimed at improving the action-data efficiency of inverse dynamics controllers by leveraging observational demonstration data. Specifically, we adopt a Deep Koopman Operator framework to model the dynamical system and utilize observation-only trajectories to learn a latent action representation. This latent representation can then be effectively mapped to real high-dimensional continuous actions using a linear action decoder, requiring minimal action-labeled data. Through experiments on simulated robot manipulation tasks and a real robot experiment with multi-modal expert demonstrations, we demonstrate that our approach significantly enhances action-data efficiency and achieves high task success rates with limited action data.
DeFT: Flash Tree-attention with IO-Awareness for Efficient Tree-search-based LLM Inference
Mar 30, 2024Decoding using tree search can greatly enhance the inference quality for transformer-based Large Language Models (LLMs). Depending on the guidance signal, it searches for the best path from root to leaf in the tree by forming LLM outputs to improve controllability, reasoning ability, alignment, et cetera. However, current tree decoding strategies and their inference systems do not suit each other well due to redundancy in computation, memory footprints, and memory access, resulting in inefficient inference. To address this issue, we propose DeFT, an IO-aware tree attention algorithm that maintains memory-efficient attention calculation with low memory footprints in two stages: (1) QKV Preparation: we propose a KV-Guided Tree Split strategy to group QKV wisely for high utilization of GPUs and reduction of memory reads/writes for the KV cache between GPU global memory and on-chip shared memory as much as possible; (2) Attention Calculation: we calculate partial attention of each QKV groups in a fused kernel then apply a Tree-topology-aware Global Reduction strategy to get final attention. Thanks to a reduction in KV cache IO by 3.6-4.5$\times$, along with an additional reduction in IO for $\mathbf{Q} \mathbf{K}^\top$ and Softmax equivalent to 25% of the total KV cache IO, DeFT can achieve a speedup of 1.7-2.4$\times$ in end-to-end latency across two practical reasoning tasks over the SOTA attention algorithms.
Behavioral Refinement via Interpolant-based Policy Diffusion
Feb 25, 2024



Imitation learning empowers artificial agents to mimic behavior by learning from demonstrations. Recently, diffusion models, which have the ability to model high-dimensional and multimodal distributions, have shown impressive performance on imitation learning tasks. These models learn to shape a policy by diffusing actions (or states) from standard Gaussian noise. However, the target policy to be learned is often significantly different from Gaussian and this mismatch can result in poor performance when using a small number of diffusion steps (to improve inference speed) and under limited data. The key idea in this work is that initiating from a more informative source than Gaussian enables diffusion methods to overcome the above limitations. We contribute both theoretical results, a new method, and empirical findings that show the benefits of using an informative source policy. Our method, which we call BRIDGER, leverages the stochastic interpolants framework to bridge arbitrary policies, thus enabling a flexible approach towards imitation learning. It generalizes prior work in that standard Gaussians can still be applied, but other source policies can be used if available. In experiments on challenging benchmarks, BRIDGER outperforms state-of-the-art diffusion policies and we provide further analysis on design considerations when applying BRIDGER.
Latent Emission-Augmented Perspective-Taking (LEAPT) for Human-Robot Interaction
Aug 12, 2023
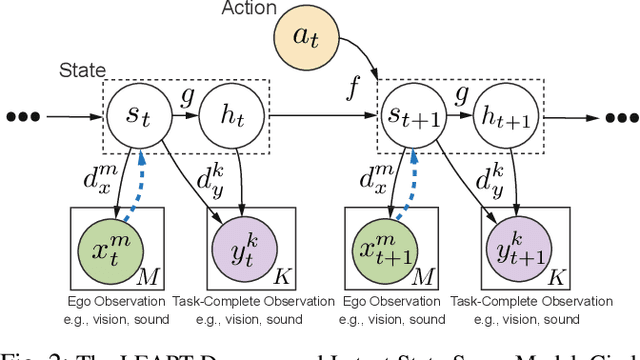


Perspective-taking is the ability to perceive or understand a situation or concept from another individual's point of view, and is crucial in daily human interactions. Enabling robots to perform perspective-taking remains an unsolved problem; existing approaches that use deterministic or handcrafted methods are unable to accurately account for uncertainty in partially-observable settings. This work proposes to address this limitation via a deep world model that enables a robot to perform both perception and conceptual perspective taking, i.e., the robot is able to infer what a human sees and believes. The key innovation is a decomposed multi-modal latent state space model able to generate and augment fictitious observations/emissions. Optimizing the ELBO that arises from this probabilistic graphical model enables the learning of uncertainty in latent space, which facilitates uncertainty estimation from high-dimensional observations. We tasked our model to predict human observations and beliefs on three partially-observable HRI tasks. Experiments show that our method significantly outperforms existing baselines and is able to infer visual observations available to other agent and their internal beliefs.
Semantic Visual Simultaneous Localization and Mapping: A Survey
Sep 14, 2022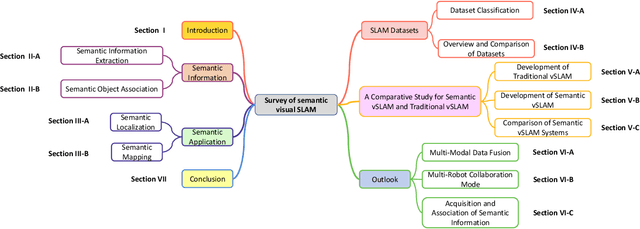
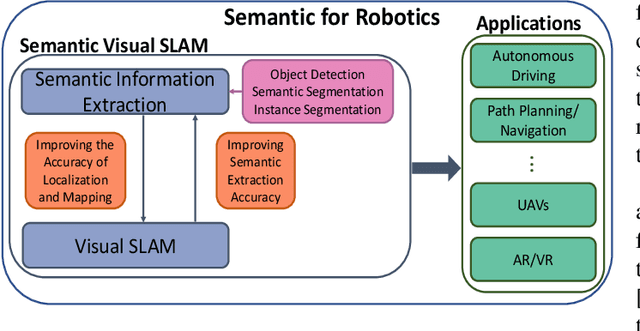

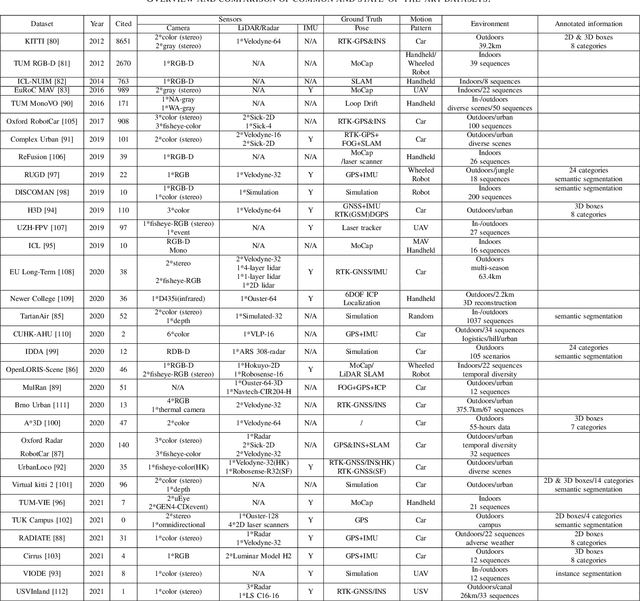
Visual Simultaneous Localization and Mapping (vSLAM) has achieved great progress in the computer vision and robotics communities, and has been successfully used in many fields such as autonomous robot navigation and AR/VR. However, vSLAM cannot achieve good localization in dynamic and complex environments. Numerous publications have reported that, by combining with the semantic information with vSLAM, the semantic vSLAM systems have the capability of solving the above problems in recent years. Nevertheless, there is no comprehensive survey about semantic vSLAM. To fill the gap, this paper first reviews the development of semantic vSLAM, explicitly focusing on its strengths and differences. Secondly, we explore three main issues of semantic vSLAM: the extraction and association of semantic information, the application of semantic information, and the advantages of semantic vSLAM. Then, we collect and analyze the current state-of-the-art SLAM datasets which have been widely used in semantic vSLAM systems. Finally, we discuss future directions that will provide a blueprint for the future development of semantic vSLAM.
MIRROR: Differentiable Deep Social Projection for Assistive Human-Robot Communication
Mar 06, 2022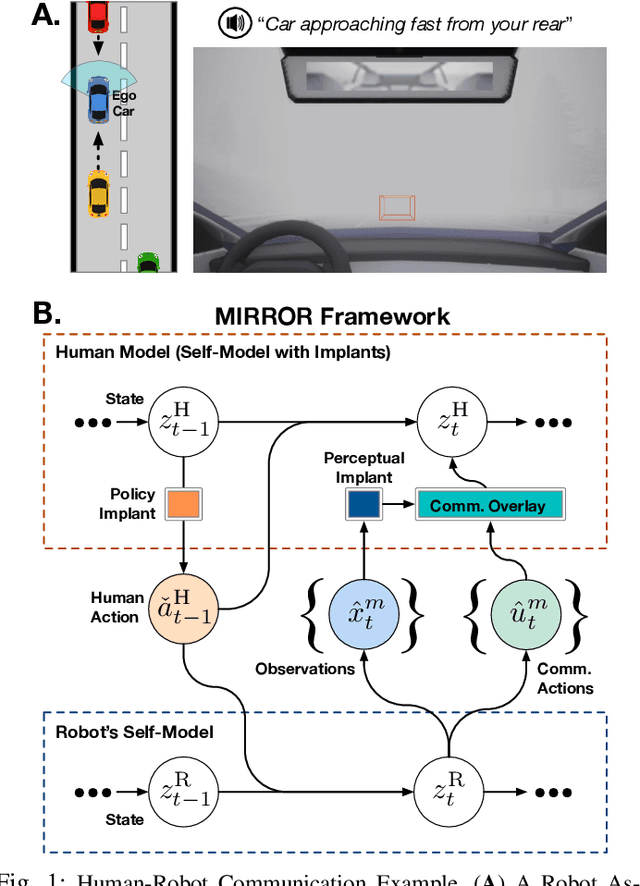
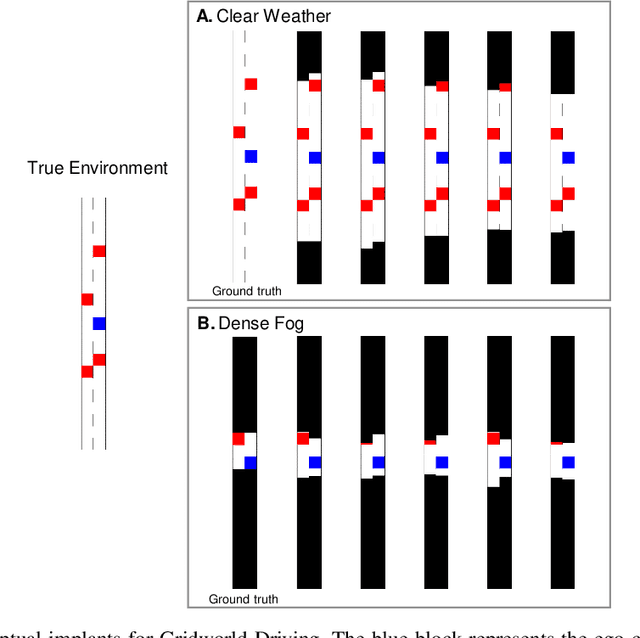
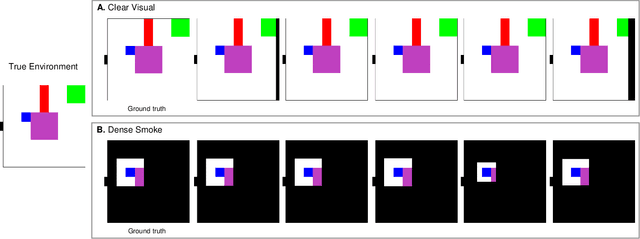
Communication is a hallmark of intelligence. In this work, we present MIRROR, an approach to (i) quickly learn human models from human demonstrations, and (ii) use the models for subsequent communication planning in assistive shared-control settings. MIRROR is inspired by social projection theory, which hypothesizes that humans use self-models to understand others. Likewise, MIRROR leverages self-models learned using reinforcement learning to bootstrap human modeling. Experiments with simulated humans show that this approach leads to rapid learning and more robust models compared to existing behavioral cloning and state-of-the-art imitation learning methods. We also present a human-subject study using the CARLA simulator which shows that (i) MIRROR is able to scale to complex domains with high-dimensional observations and complicated world physics and (ii) provides effective assistive communication that enabled participants to drive more safely in adverse weather conditions.
Multi-Modal Mutual Information (MuMMI) Training for Robust Self-Supervised Deep Reinforcement Learning
Jul 06, 2021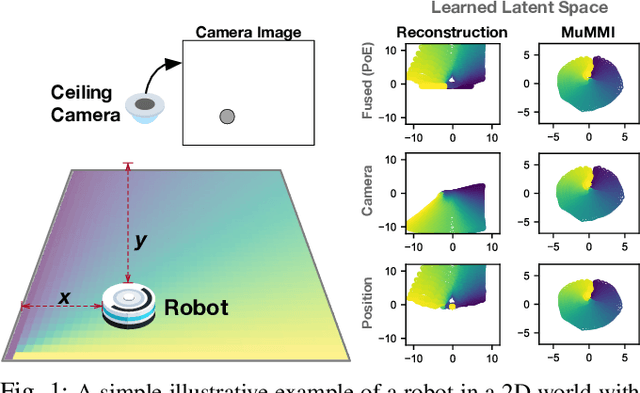
This work focuses on learning useful and robust deep world models using multiple, possibly unreliable, sensors. We find that current methods do not sufficiently encourage a shared representation between modalities; this can cause poor performance on downstream tasks and over-reliance on specific sensors. As a solution, we contribute a new multi-modal deep latent state-space model, trained using a mutual information lower-bound. The key innovation is a specially-designed density ratio estimator that encourages consistency between the latent codes of each modality. We tasked our method to learn policies (in a self-supervised manner) on multi-modal Natural MuJoCo benchmarks and a challenging Table Wiping task. Experiments show our method significantly outperforms state-of-the-art deep reinforcement learning methods, particularly in the presence of missing observations.
Collaborative Visual Inertial SLAM for Multiple Smart Phones
Jun 23, 2021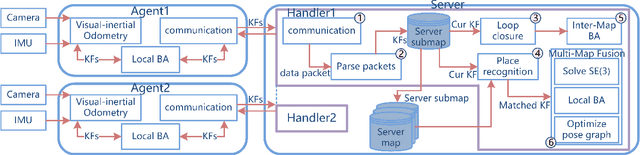
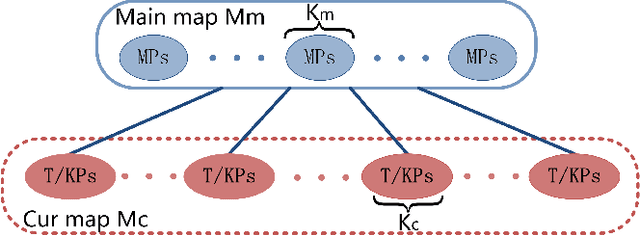
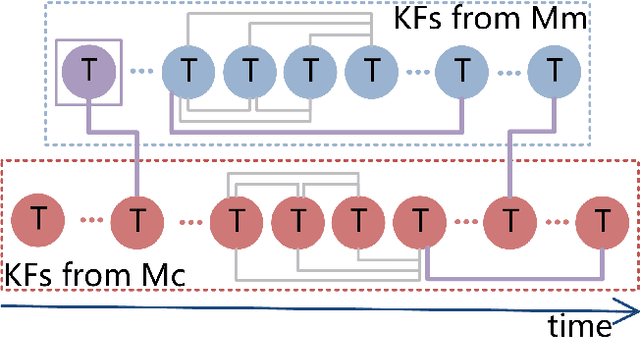
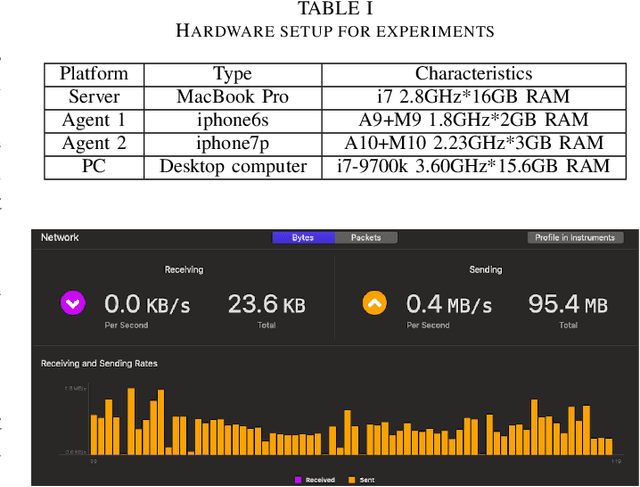
The efficiency and accuracy of mapping are crucial in a large scene and long-term AR applications. Multi-agent cooperative SLAM is the precondition of multi-user AR interaction. The cooperation of multiple smart phones has the potential to improve efficiency and robustness of task completion and can complete tasks that a single agent cannot do. However, it depends on robust communication, efficient location detection, robust mapping, and efficient information sharing among agents. We propose a multi-intelligence collaborative monocular visual-inertial SLAM deployed on multiple ios mobile devices with a centralized architecture. Each agent can independently explore the environment, run a visual-inertial odometry module online, and then send all the measurement information to a central server with higher computing resources. The server manages all the information received, detects overlapping areas, merges and optimizes the map, and shares information with the agents when needed. We have verified the performance of the system in public datasets and real environments. The accuracy of mapping and fusion of the proposed system is comparable to VINS-Mono which requires higher computing resources.
Accurate Object Association and Pose Updating for Semantic SLAM
Dec 21, 2020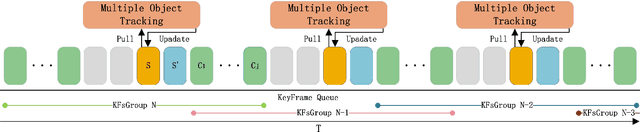
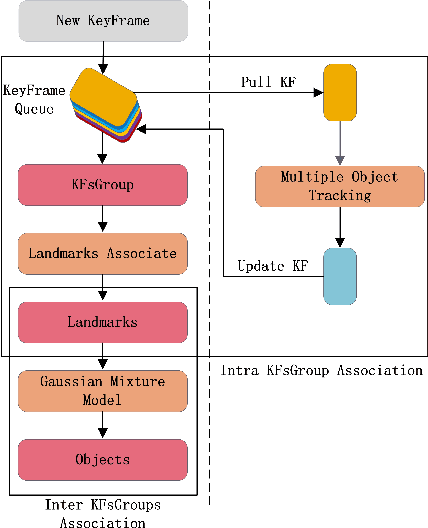
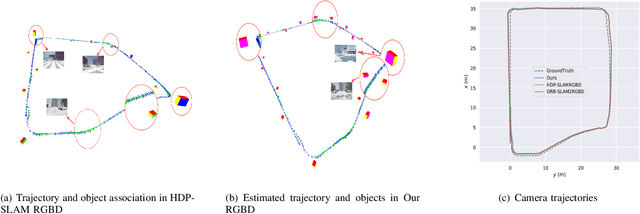
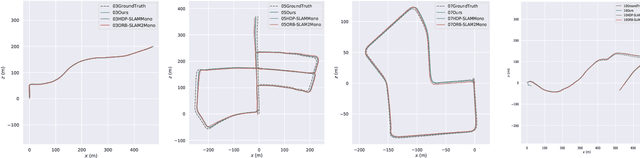
Nowadays in the field of semantic SLAM, how to correctly use semantic information for data association is still a problem worthy of study. The key to solving this problem is to correctly associate multiple object measurements of one object landmark, and refine the pose of object landmark. However, different objects locating closely are prone to be associated as one object landmark, and it is difficult to pick up a best pose from multiple object measurements associated with one object landmark. To tackle these problems, we propose a hierarchical object association strategy by means of multiple object tracking, through which closing objects will be correctly associated to different object landmarks, and an approach to refine the pose of object landmark from multiple object measurements. The proposed method is evaluated on a simulated sequence and several sequences in the Kitti dataset. Experimental results show a very impressive improvement with respect to the traditional SLAM and the state-of-the-art semantic SLAM method.