 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Emission-Augmented Perspective-Taking (LEAPT) for Human-Robot Interaction
Aug 12, 2023
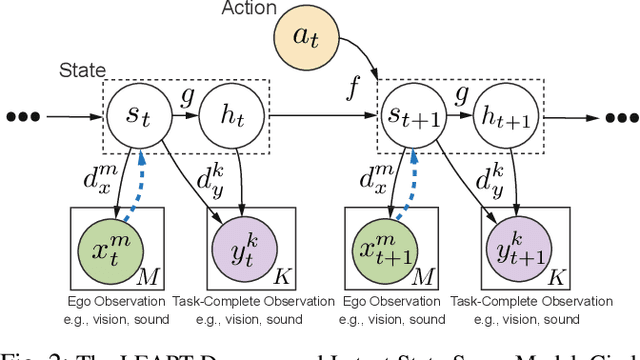


Perspective-taking is the ability to perceive or understand a situation or concept from another individual's point of view, and is crucial in daily human interactions. Enabling robots to perform perspective-taking remains an unsolved problem; existing approaches that use deterministic or handcrafted methods are unable to accurately account for uncertainty in partially-observable settings. This work proposes to address this limitation via a deep world model that enables a robot to perform both perception and conceptual perspective taking, i.e., the robot is able to infer what a human sees and believes. The key innovation is a decomposed multi-modal latent state space model able to generate and augment fictitious observations/emissions. Optimizing the ELBO that arises from this probabilistic graphical model enables the learning of uncertainty in latent space, which facilitates uncertainty estimation from high-dimensional observations. We tasked our model to predict human observations and beliefs on three partially-observable HRI tasks. Experiments show that our method significantly outperforms existing baselines and is able to infer visual observations available to other agent and their internal beliefs.
Truly Multi-modal YouTube-8M Video Classification with Video, Audio, and Text
Jul 10, 2017
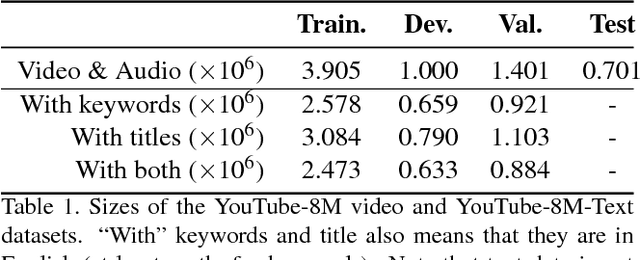
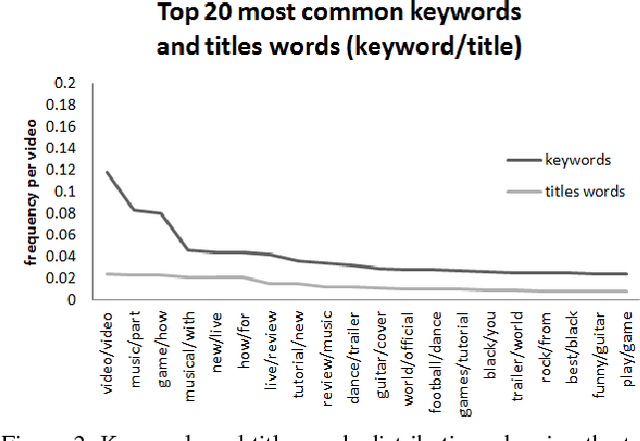

The YouTube-8M video classification challenge requires teams to classify 0.7 million videos into one or more of 4,716 classes. In this Kaggle competition, we placed in the top 3% out of 650 participants using released video and audio features. Beyond that, we extend the original competition by including text information in the classification, making this a truly multi-modal approach with vision, audio and text. The newly introduced text data is termed as YouTube-8M-Text. We present a classification framework for the joint use of text, visual and audio features, and conduct an extensive set of experiments to quantify the benefit that this additional mode brings. The inclusion of text yields state-of-the-art results, e.g. 86.7% GAP on the YouTube-8M-Text validation dataset.
Deep Learning for Lung Cancer Detection: Tackling the Kaggle Data Science Bowl 2017 Challenge
May 26, 2017
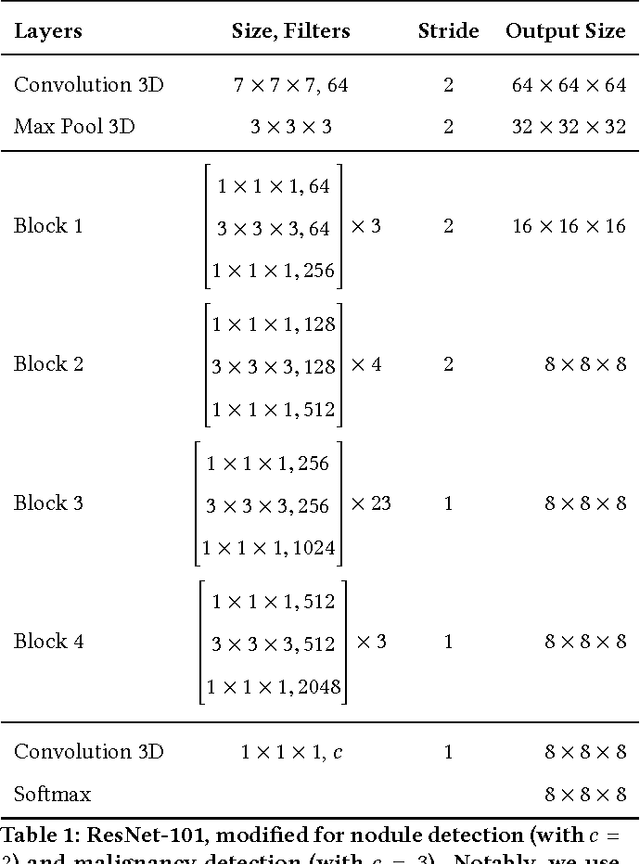
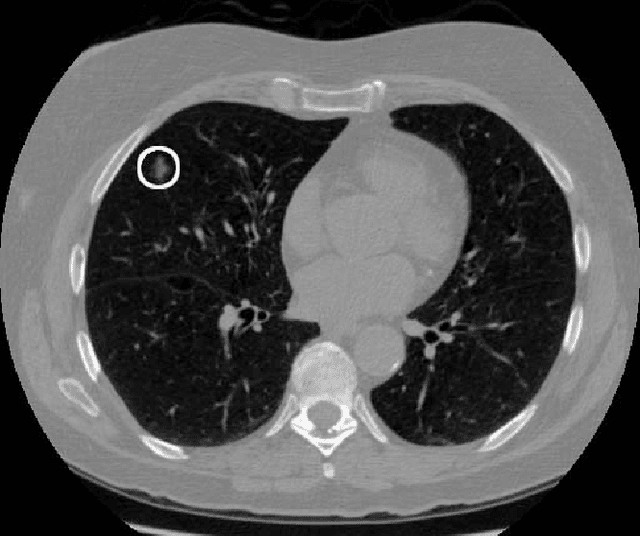
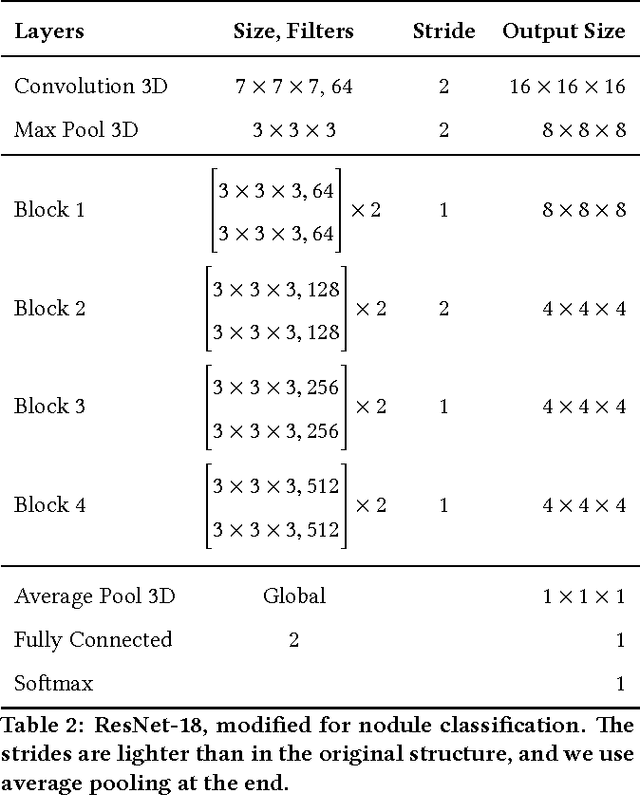
We present a deep learning framework for computer-aided lung cancer diagnosis. Our multi-stage framework detects nodules in 3D lung CAT scans, determines if each nodule is malignant, and finally assigns a cancer probability based on these results. We discuss the challenges and advantages of our framework. In the Kaggle Data Science Bowl 2017, our framework ranked 41st out of 1972 teams.