 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Annotation-Free Validation of MLLMs: A Vision-Language Logical Consistency Metric
May 07, 2026Dominant accuracy evaluation might reward unwarranted guessing of Large Language Models, and it might not be applicable to novel tasks for model validation without ground-truth (gt) annotation. Based on basic logic principle, we propose a novel framework to evaluate the vision-language logical consistency of MLLMs on both sufficient and necessary cause-effect relations. We define Vision-Language Logical Consistency Metric (VL-LCM) on traditional MC-VQA tests, and recent NaturalBench tests without the need for gt annotation. Through systematic experiments on representative VL benchmark MMMU and recent VL challenges like NaturalBench, we evaluated 11 recent open-source MLLMs from 4 frontier families. Our findings reveal that, despite significant progress of recent MLLMs on accuracy, logical consistency lags behind significantly. Extensive evaluations on the correlations of VL-LCM with metrics on gt, the reliability of LCM, and the relation of VL-LCM with response distribution justify the validity and applicability of VL-LCM even without gt annotation. Our findings suggest that, beyond accuracy, logical consistency could be employed for both accuracy and reliability. VL-LCM can also be employed for MLLM selection, validation, and reliable answer justification in novel tasks without gt annotation.
Explicit Logic Channel for Validation and Enhancement of MLLMs on Zero-Shot Tasks
Mar 12, 2026Frontier Multimodal Large Language Models (MLLMs) exhibit remarkable capabilities in Visual-Language Comprehension (VLC) tasks. However, they are often deployed as zero-shot solution to new tasks in a black-box manner. Validating and understanding the behavior of these models become important for application to new task. We propose an Explicit Logic Channel, in parallel with the black-box model channel, to perform explicit logical reasoning for model validation, selection and enhancement. The frontier MLLM, encapsulating latent vision-language knowledge, can be considered as an Implicit Logic Channel. The proposed Explicit Logic Channel, mimicking human logical reasoning, incorporates a LLM, a VFM, and logical reasoning with probabilistic inference for factual, counterfactual, and relational reasoning over the explicit visual evidence. A Consistency Rate (CR) is proposed for cross-channel validation and model selection, even without ground-truth annotations. Additionally, cross-channel integration further improves performance in zero-shot tasks over MLLMs, grounded with explicit visual evidence to enhance trustworthiness. Comprehensive experiments conducted for two representative VLC tasks, i.e., MC-VQA and HC-REC, on three challenging benchmarks, with 11 recent open-source MLLMs from 4 frontier families. Our systematic evaluations demonstrate the effectiveness of proposed ELC and CR for model validation, selection and improvement on MLLMs with enhanced explainability and trustworthiness.
Structure from Rank: Rank-Order Coding as a Bridge from Sequence to Structure
Mar 09, 2026Understanding how structured sequence information can be represented and generalized in neural systems is key to modeling the transition from acoustic input to emergent structure. In this study, we propose a rank-order based neural network inspired by the STG-LIFG-PMC pathway, modeling the bottom-up transition from acoustic input to abstract rank representation, and the top-down generation from that representation to motor execution. Building on previous work in rank coding, we first demonstrate that this model efficiently compresses input while retaining the capacity to reconstruct full utterances from partial cues, revealing emergent structure-sensitive generation process that reflects context-general representations of sensorimotor states, which are later shaped into context-specific motor plans during speech planning. We then show that the network exhibits global-level novelty detection similar to the P3B novelty wave, replicating the global-sequence-sensitive mechanism. As a supplement, we also compare the model's behavior under local (index-level) and global (rank-level) perturbations, revealing robustness to superficial variation and sensitivity to abstract structural violation, key features associated with proto-syntactic generalization. These results suggest that rank-order coding not only serve as a compact encoding scheme but also support encoding hierarchical grammar.
The Reward Model Selection Crisis in Personalized Alignment
Dec 28, 2025Personalized alignment from preference data has focused primarily on improving reward model (RM) accuracy, with the implicit assumption that better preference ranking translates to better personalized behavior. However, in deployment, computational constraints necessitate inference-time adaptation via reward-guided decoding (RGD) rather than per-user policy fine-tuning. This creates a critical but overlooked requirement: reward models must not only rank preferences accurately but also effectively guide token-level generation decisions. We demonstrate that standard RM accuracy fails catastrophically as a selection criterion for deployment-ready personalized alignment. Through systematic evaluation across three datasets, we introduce policy accuracy, a metric quantifying whether RGD scoring functions correctly discriminate between preferred and dispreferred responses. We show that RM accuracy correlates only weakly with this policy-level discrimination ability (Kendall's tau = 0.08--0.31). More critically, we introduce Pref-LaMP, the first personalized alignment benchmark with ground-truth user completions, enabling direct behavioral evaluation without circular reward-based metrics. On Pref-LaMP, we expose a complete decoupling between discrimination and generation: methods with 20-point RM accuracy differences produce almost identical output quality, and even methods achieving high discrimination fail to generate behaviorally aligned responses. Finally, simple in-context learning (ICL) dominates all reward-guided methods for models > 3B parameters, achieving 3-5 point ROUGE-1 gains over the best reward method at 7B scale. These findings show that the field optimizes proxy metrics that fail to predict deployment performance and do not translate preferences into real behavioral adaptation under deployment constraints.
Incorporating Contextual Paralinguistic Understanding in Large Speech-Language Models
Aug 10, 2025Current large speech language models (Speech-LLMs) often exhibit limitations in empathetic reasoning, primarily due to the absence of training datasets that integrate both contextual content and paralinguistic cues. In this work, we propose two approaches to incorporate contextual paralinguistic information into model training: (1) an explicit method that provides paralinguistic metadata (e.g., emotion annotations) directly to the LLM, and (2) an implicit method that automatically generates novel training question-answer (QA) pairs using both categorical and dimensional emotion annotations alongside speech transcriptions. Our implicit method boosts performance (LLM-judged) by 38.41% on a human-annotated QA benchmark, reaching 46.02% when combined with the explicit approach, showing effectiveness in contextual paralinguistic understanding. We also validate the LLM judge by demonstrating its correlation with classification metrics, providing support for its reliability.
In2Core: Leveraging Influence Functions for Coreset Selection in Instruction Finetuning of Large Language Models
Aug 07, 2024Despite advancements, fine-tuning Large Language Models (LLMs) remains costly due to the extensive parameter count and substantial data requirements for model generalization. Accessibility to computing resources remains a barrier for the open-source community. To address this challenge, we propose the In2Core algorithm, which selects a coreset by analyzing the correlation between training and evaluation samples with a trained model. Notably, we assess the model's internal gradients to estimate this relationship, aiming to rank the contribution of each training point. To enhance efficiency, we propose an optimization to compute influence functions with a reduced number of layers while achieving similar accuracy. By applying our algorithm to instruction fine-tuning data of LLMs, we can achieve similar performance with just 50% of the training data. Meantime, using influence functions to analyze model coverage to certain testing samples could provide a reliable and interpretable signal on the training set's coverage of those test points.
PromptSum: Parameter-Efficient Controllable Abstractive Summarization
Aug 06, 2023



Prompt tuning (PT), a parameter-efficient technique that only tunes the additional prompt embeddings while keeping the backbone pre-trained language model (PLM) frozen, has shown promising results in language understanding tasks, especially in low-resource scenarios. However, effective prompt design methods suitable for generation tasks such as summarization are still lacking. At the same time, summarization guided through instructions (discrete prompts) can achieve a desirable double objective of high quality and controllability in summary generation. Towards a goal of strong summarization performance under the triple conditions of parameter-efficiency, data-efficiency, and controllability, we introduce PromptSum, a method combining PT with a multi-task objective and discrete entity prompts for abstractive summarization. Our model achieves competitive ROUGE results on popular abstractive summarization benchmarks coupled with a strong level of controllability through entities, all while only tuning several orders of magnitude less parameters.
Unsupervised Summarization Re-ranking
Dec 19, 2022



With the rise of task-specific pre-training objectives, abstractive summarization models like PEGASUS offer appealing zero-shot performance on downstream summarization tasks. However, the performance of such unsupervised models still lags significantly behind their supervised counterparts. Similarly to the supervised setup, we notice a very high variance in quality among summary candidates from these models whereas only one candidate is kept as the summary output. In this paper, we propose to re-rank summary candidates in an unsupervised manner, aiming to close the performance gap between unsupervised and supervised models. Our approach improves the pre-trained unsupervised PEGASUS by 4.37% to 7.27% relative mean ROUGE across four widely-adopted summarization benchmarks, and achieves relative gains of 7.51% (up to 23.73%) averaged over 30 transfer setups.
Truly Multi-modal YouTube-8M Video Classification with Video, Audio, and Text
Jul 10, 2017
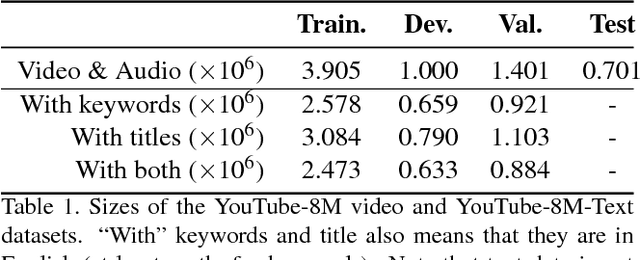
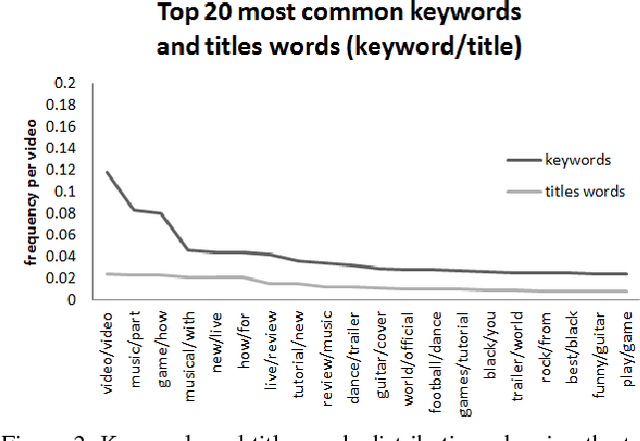

The YouTube-8M video classification challenge requires teams to classify 0.7 million videos into one or more of 4,716 classes. In this Kaggle competition, we placed in the top 3% out of 650 participants using released video and audio features. Beyond that, we extend the original competition by including text information in the classification, making this a truly multi-modal approach with vision, audio and text. The newly introduced text data is termed as YouTube-8M-Text. We present a classification framework for the joint use of text, visual and audio features, and conduct an extensive set of experiments to quantify the benefit that this additional mode brings. The inclusion of text yields state-of-the-art results, e.g. 86.7% GAP on the YouTube-8M-Text validation dataset.