 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chicken and Egg Dilemma: Co-optimizing Data and Model Configurations for LLMs
Feb 09, 2026Co-optimizing data and model configurations for training LLMs presents a classic chicken-and-egg dilemma: The best training data configuration (e.g., data mixture) for a downstream task depends on the chosen model configuration (e.g., model architecture), and vice versa. However, jointly optimizing both data and model configurations is often deemed intractable, and existing methods focus on either data or model optimization without considering their interaction. We introduce JoBS, an approach that uses a scaling-law-inspired performance predictor to aid Bayesian optimization (BO) in jointly optimizing LLM training data and model configurations efficiently. JoBS allocates a portion of the optimization budget to learn an LLM performance predictor that predicts how promising a training configuration is from a small number of training steps. The remaining budget is used to perform BO entirely with the predictor, effectively amortizing the cost of running full-training runs. We study JoBS's average regret and devise the optimal budget allocation to minimize regret. JoBS outperforms existing multi-fidelity BO baselines, as well as data and model optimization approaches across diverse LLM tasks under the same optimization budget.
Programming over Thinking: Efficient and Robust Multi-Constraint Planning
Jan 14, 2026Multi-constraint planning involves identifying, evaluating, and refining candidate plans while satisfying multiple, potentially conflicting constraints. Existing large language model (LLM) approaches face fundamental limitations in this domain. Pure reasoning paradigms, which rely on long natural language chains, are prone to inconsistency, error accumulation, and prohibitive cost as constraints compound. Conversely, LLMs combined with coding- or solver-based strategies lack flexibility: they often generate problem-specific code from scratch or depend on fixed solvers, failing to capture generalizable logic across diverse problems. To address these challenges, we introduce the Scalable COde Planning Engine (SCOPE), a framework that disentangles query-specific reasoning from generic code execution. By separating reasoning from execution, SCOPE produces solver functions that are consistent, deterministic, and reusable across queries while requiring only minimal changes to input parameters. SCOPE achieves state-of-the-art performance while lowering cost and latency. For example, with GPT-4o, it reaches 93.1% success on TravelPlanner, a 61.6% gain over the best baseline (CoT) while cutting inference cost by 1.4x and time by ~4.67x. Code is available at https://github.com/DerrickGXD/SCOPE.
Minimal Clips, Maximum Salience: Long Video Summarization via Key Moment Extraction
Dec 12, 2025Vision-Language Models (VLMs) are able to process increasingly longer videos. Yet, important visual information is easily lost throughout the entire context and missed by VLMs. Also, it is important to design tools that enable cost-effective analysis of lengthy video content. In this paper, we propose a clip selection method that targets key video moments to be included in a multimodal summary. We divide the video into short clips and generate compact visual descriptions of each using a lightweight video captioning model. These are then passed to a large language model (LLM), which selects the K clips containing the most relevant visual information for a multimodal summary. We evaluate our approach on reference clips for the task, automatically derived from full human-annotated screenplays and summaries in the MovieSum dataset. We further show that these reference clips (less than 6% of the movie) are sufficient to build a complete multimodal summary of the movies in MovieSum. Using our clip selection method, we achieve a summarization performance close to that of these reference clips while capturing substantially more relevant video information than random clip selection. Importantly, we maintain low computational cost by relying on a lightweight captioning model.
Machines Serve Human: A Novel Variable Human-machine Collaborative Compression Framework
Nov 12, 2025


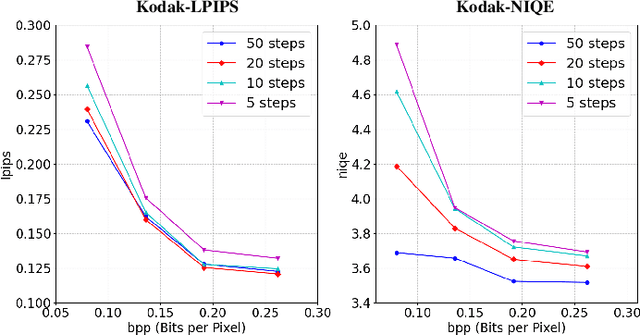
Human-machine collaborative compression has been receiving increasing research efforts for reducing image/video data, serving as the basis for both human perception and machine intelligence. Existing collaborative methods are dominantly built upon the de facto human-vision compression pipeline, witnessing deficiency on complexity and bit-rates when aggregating the machine-vision compression. Indeed, machine vision solely focuses on the core regions within the image/video, requiring much less information compared with the compressed information for human vision. In this paper, we thus set out the first successful attempt by a novel collaborative compression method based on the machine-vision-oriented compression, instead of human-vision pipeline. In other words, machine vision serves as the basis for human vision within collaborative compression. A plug-and-play variable bit-rate strategy is also developed for machine vision tasks. Then, we propose to progressively aggregate the semantics from the machine-vision compression, whilst seamlessly tailing the diffusion prior to restore high-fidelity details for human vision, thus named as diffusion-prior based feature compression for human and machine visions (Diff-FCHM). Experimental results verify the consistently superior performances of our Diff-FCHM, on both machine-vision and human-vision compression with remarkable margins. Our code will be released upon acceptance.
The Imperfect Learner: Incorporating Developmental Trajectories in Memory-based Student Simulation
Nov 08, 2025
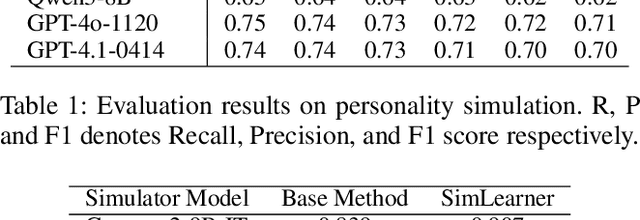
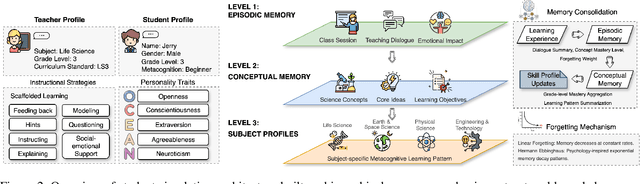
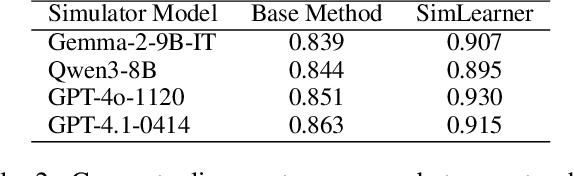
User simulation is important for developing and evaluating human-centered AI, yet current student simulation in educational applications has significant limitations. Existing approaches focus on single learning experiences and do not account for students' gradual knowledge construction and evolving skill sets. Moreover, large language models are optimized to produce direct and accurate responses, making it challenging to represent the incomplete understanding and developmental constraints that characterize real learners. In this paper, we introduce a novel framework for memory-based student simulation that incorporates developmental trajectories through a hierarchical memory mechanism with structured knowledge representation. The framework also integrates metacognitive processes and personality traits to enrich the individual learner profiling, through dynamical consolidation of both cognitive development and personal learning characteristics. In practice, we implement a curriculum-aligned simulator grounded on the Next Generation Science Standards. Experimental results show that our approach can effectively reflect the gradual nature of knowledge development and the characteristic difficulties students face, providing a more accurate representation of learning processes.
Persuasion Dynamics in LLMs: Investigating Robustness and Adaptability in Knowledge and Safety with DuET-PD
Aug 24, 2025Large Language Models (LLMs) can struggle to balance gullibility to misinformation and resistance to valid corrections in persuasive dialogues, a critical challenge for reliable deployment. We introduce DuET-PD (Dual Evaluation for Trust in Persuasive Dialogues), a framework evaluating multi-turn stance-change dynamics across dual dimensions: persuasion type (corrective/misleading) and domain (knowledge via MMLU-Pro, and safety via SALAD-Bench). We find that even a state-of-the-art model like GPT-4o achieves only 27.32% accuracy in MMLU-Pro under sustained misleading persuasions. Moreover, results reveal a concerning trend of increasing sycophancy in newer open-source models. To address this, we introduce Holistic DPO, a training approach balancing positive and negative persuasion examples. Unlike prompting or resist-only training, Holistic DPO enhances both robustness to misinformation and receptiveness to corrections, improving Llama-3.1-8B-Instruct's accuracy under misleading persuasion in safety contexts from 4.21% to 76.54%. These contributions offer a pathway to developing more reliable and adaptable LLMs for multi-turn dialogue. Code is available at https://github.com/Social-AI-Studio/DuET-PD.
COGENT: A Curriculum-oriented Framework for Generating Grade-appropriate Educational Content
Jun 11, 2025While Generative AI has demonstrated strong potential and versatility in content generation, its application to educational contexts presents several challenges. Models often fail to align with curriculum standards and maintain grade-appropriate reading levels consistently. Furthermore, STEM education poses additional challenges in balancing scientific explanations with everyday language when introducing complex and abstract ideas and phenomena to younger students. In this work, we propose COGENT, a curriculum-oriented framework for generating grade-appropriate educational content. We incorporate three curriculum components (science concepts, core ideas, and learning objectives), control readability through length, vocabulary, and sentence complexity, and adopt a ``wonder-based'' approach to increase student engagement and interest. We conduct a multi-dimensional evaluation via both LLM-as-a-judge and human expert analysis. Experimental results show that COGENT consistently produces grade-appropriate passages that are comparable or superior to human references. Our work establishes a viable approach for scaling adaptive and high-quality learning resources.
Integrating Video and Text: A Balanced Approach to Multimodal Summary Generation and Evaluation
May 10, 2025Vision-Language Models (VLMs) often struggle to balance visual and textual information when summarizing complex multimodal inputs, such as entire TV show episodes. In this paper, we propose a zero-shot video-to-text summarization approach that builds its own screenplay representation of an episode, effectively integrating key video moments, dialogue, and character information into a unified document. Unlike previous approaches, we simultaneously generate screenplays and name the characters in zero-shot, using only the audio, video, and transcripts as input. Additionally, we highlight that existing summarization metrics can fail to assess the multimodal content in summaries. To address this, we introduce MFactSum, a multimodal metric that evaluates summaries with respect to both vision and text modalities. Using MFactSum, we evaluate our screenplay summaries on the SummScreen3D dataset, demonstrating superiority against state-of-the-art VLMs such as Gemini 1.5 by generating summaries containing 20% more relevant visual information while requiring 75% less of the video as input.
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Apr 15, 2025
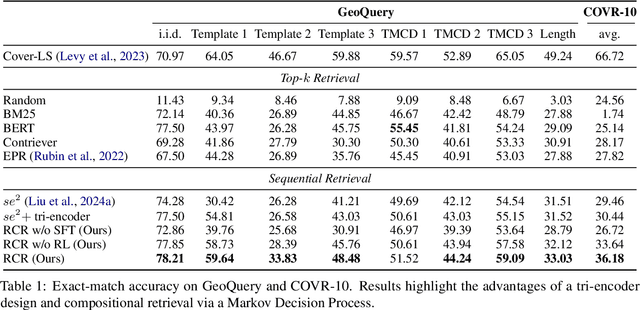
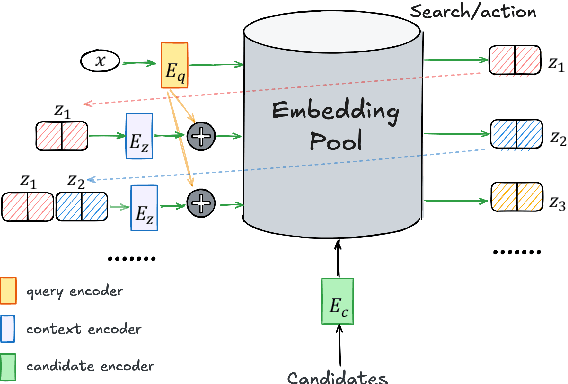
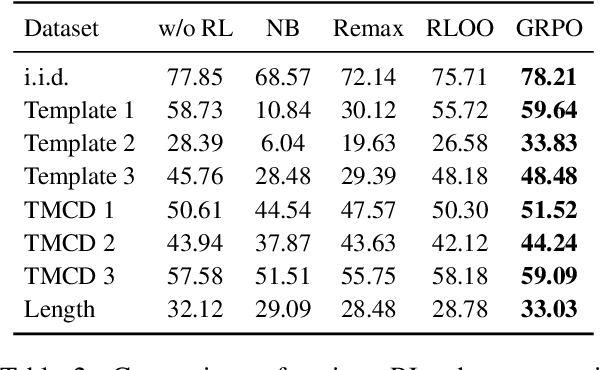
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM's preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
AdaCoT: Rethinking Cross-Lingual Factual Reasoning through Adaptive Chain-of-Thought
Jan 27, 2025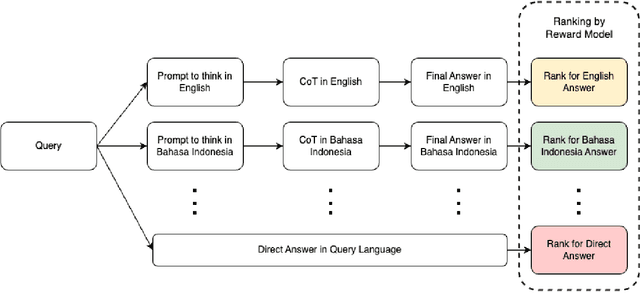
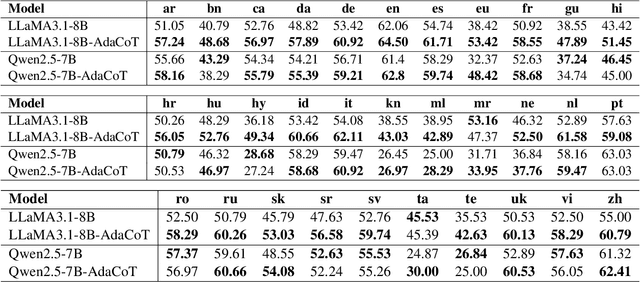

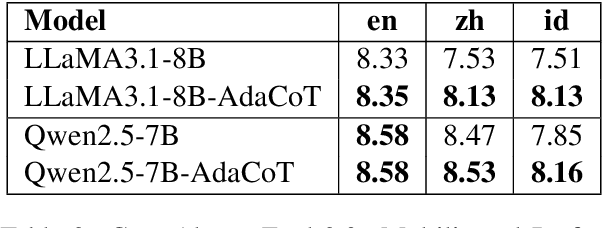
Large language models (LLMs) have shown impressive multilingual capabilities through pretraining on diverse corpora. While these models show strong reasoning abilities, their performance varies significantly across languages due to uneven training data distribution. Existing approaches using machine translation, and extensive multilingual pretraining and cross-lingual tuning face scalability challenges and often fail to capture nuanced reasoning processes across languages. In this paper, we introduce AdaCoT (Adaptive Chain-of-Thought), a framework that enhances multilingual reasoning by dynamically routing thought processes through intermediary "thinking languages" before generating target-language responses. AdaCoT leverages a language-agnostic core and incorporates an adaptive, reward-based mechanism for selecting optimal reasoning pathways without requiring additional pretraining. Our comprehensive evaluation across multiple benchmarks demonstrates substantial improvements in both factual reasoning quality and cross-lingual consistency, with particularly strong performance gains in low-resource language settings. The results suggest that adaptive reasoning paths can effectively bridge the performance gap between high and low-resource languages while maintaining cultural and linguistic nuances.